 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation
Jun 07, 2024

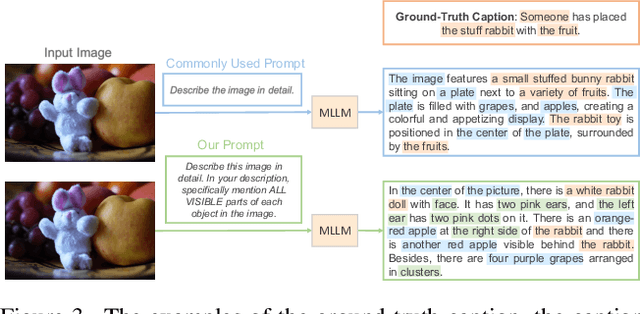
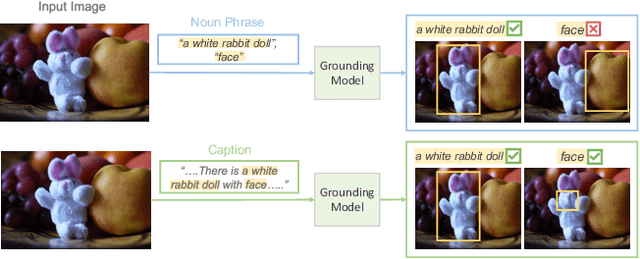
The open-vocabulary image segmentation task involves partitioning images into semantically meaningful segments and classifying them with flexible text-defined categories. The recent vision-based foundation models such as the Segment Anything Model (SAM) have shown superior performance in generating class-agnostic image segments. The main challenge in open-vocabulary image segmentation now lies in accurately classifying these segments into text-defined categories. In this paper, we introduce the Universal Segment Embedding (USE) framework to address this challenge. This framework is comprised of two key components: 1) a data pipeline designed to efficiently curate a large amount of segment-text pairs at various granularities, and 2) a universal segment embedding model that enables precise segment classification into a vast range of text-defined categories. The USE model can not only help open-vocabulary image segmentation but also facilitate other downstream tasks (e.g., querying and ranking). Through comprehensive experimental studies on semantic segmentation and part segmentation benchmarks, we demonstrate that the USE framework outperforms state-of-the-art open-vocabulary segmentation methods.
A streamlined Approach to Multimodal Few-Shot Class Incremental Learning for Fine-Grained Datasets
Mar 10, 2024



Few-shot Class-Incremental Learning (FSCIL) poses the challenge of retaining prior knowledge while learning from limited new data streams, all without overfitting. The rise of Vision-Language models (VLMs) has unlocked numerous applications, leveraging their existing knowledge to fine-tune on custom data. However, training the whole model is computationally prohibitive, and VLMs while being versatile in general domains still struggle with fine-grained datasets crucial for many applications. We tackle these challenges with two proposed simple modules. The first, Session-Specific Prompts (SSP), enhances the separability of image-text embeddings across sessions. The second, Hyperbolic distance, compresses representations of image-text pairs within the same class while expanding those from different classes, leading to better representations. Experimental results demonstrate an average 10-point increase compared to baselines while requiring at least 8 times fewer trainable parameters. This improvement is further underscored on our three newly introduced fine-grained datasets.
GradOrth: A Simple yet Efficient Out-of-Distribution Detection with Orthogonal Projection of Gradients
Aug 01, 2023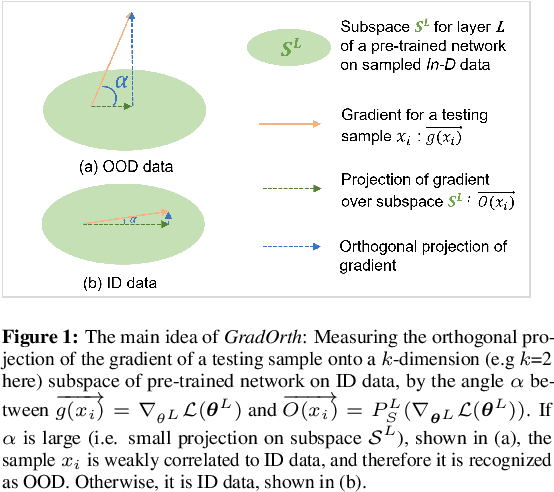
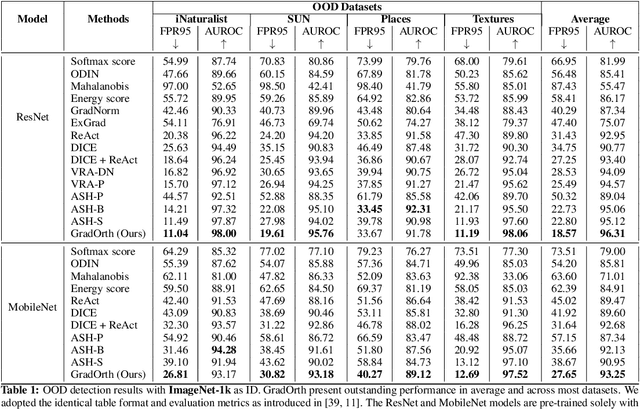
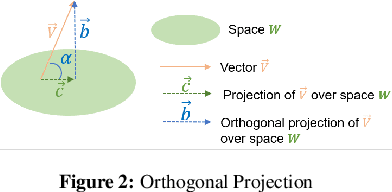

Detecting out-of-distribution (OOD) data is crucial for ensuring the safe deployment of machine learning models in real-world applications. However, existing OOD detection approaches primarily rely on the feature maps or the full gradient space information to derive OOD scores neglecting the role of most important parameters of the pre-trained network over in-distribution (ID) data. In this study, we propose a novel approach called GradOrth to facilitate OOD detection based on one intriguing observation that the important features to identify OOD data lie in the lower-rank subspace of in-distribution (ID) data. In particular, we identify OOD data by computing the norm of gradient projection on the subspaces considered important for the in-distribution data. A large orthogonal projection value (i.e. a small projection value) indicates the sample as OOD as it captures a weak correlation of the ID data. This simple yet effective method exhibits outstanding performance, showcasing a notable reduction in the average false positive rate at a 95% true positive rate (FPR95) of up to 8% when compared to the current state-of-the-art methods.
UP-DP: Unsupervised Prompt Learning for Data Pre-Selection with Vision-Language Models
Jul 20, 2023In this study, we investigate the task of data pre-selection, which aims to select instances for labeling from an unlabeled dataset through a single pass, thereby optimizing performance for undefined downstream tasks with a limited annotation budget. Previous approaches to data pre-selection relied solely on visual features extracted from foundation models, such as CLIP and BLIP-2, but largely ignored the powerfulness of text features. In this work, we argue that, with proper design, the joint feature space of both vision and text can yield a better representation for data pre-selection. To this end, we introduce UP-DP, a simple yet effective unsupervised prompt learning approach that adapts vision-language models, like BLIP-2, for data pre-selection. Specifically, with the BLIP-2 parameters frozen, we train text prompts to extract the joint features with improved representation, ensuring a diverse cluster structure that covers the entire dataset. We extensively compare our method with the state-of-the-art using seven benchmark datasets in different settings, achieving up to a performance gain of 20%. Interestingly, the prompts learned from one dataset demonstrate significant generalizability and can be applied directly to enhance the feature extraction of BLIP-2 from other datasets. To the best of our knowledge, UP-DP is the first work to incorporate unsupervised prompt learning in a vision-language model for data pre-selection.
Hyp-OW: Exploiting Hierarchical Structure Learning with Hyperbolic Distance Enhances Open World Object Detection
Jun 25, 2023Open World Object Detection (OWOD) is a challenging and realistic task that extends beyond the scope of standard Object Detection task. It involves detecting both known and unknown objects while integrating learned knowledge for future tasks. However, the level of 'unknownness' varies significantly depending on the context. For example, a tree is typically considered part of the background in a self-driving scene, but it may be significant in a household context. We argue that this external or contextual information should already be embedded within the known classes. In other words, there should be a semantic or latent structure relationship between the known and unknown items to be discovered. Motivated by this observation, we propose Hyp-OW, a method that learns and models hierarchical representation of known items through a SuperClass Regularizer. Leveraging this learned representation allows us to effectively detect unknown objects using a Similarity Distance-based Relabeling module. Extensive experiments on benchmark datasets demonstrate the effectiveness of Hyp-OW achieving improvement in both known and unknown detection (up to 6 points). These findings are particularly pronounced in our newly designed benchmark, where a strong hierarchical structure exists between known and unknown objects.
Building a Subspace of Policies for Scalable Continual Learning
Nov 18, 2022The ability to continuously acquire new knowledge and skills is crucial for autonomous agents. Existing methods are typically based on either fixed-size models that struggle to learn a large number of diverse behaviors, or growing-size models that scale poorly with the number of tasks. In this work, we aim to strike a better balance between an agent's size and performance by designing a method that grows adaptively depending on the task sequence. We introduce Continual Subspace of Policies (CSP), a new approach that incrementally builds a subspace of policies for training a reinforcement learning agent on a sequence of tasks. The subspace's high expressivity allows CSP to perform well for many different tasks while growing sublinearly with the number of tasks. Our method does not suffer from forgetting and displays positive transfer to new tasks. CSP outperforms a number of popular baselines on a wide range of scenarios from two challenging domains, Brax (locomotion) and Continual World (manipulation).
Efficient Continual Learning Ensembles in Neural Network Subspaces
Feb 20, 2022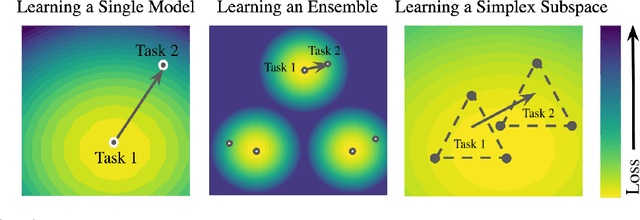
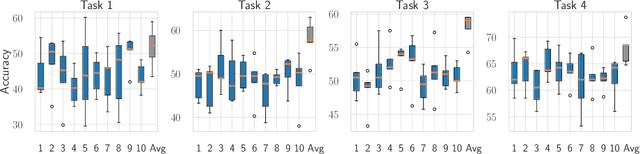

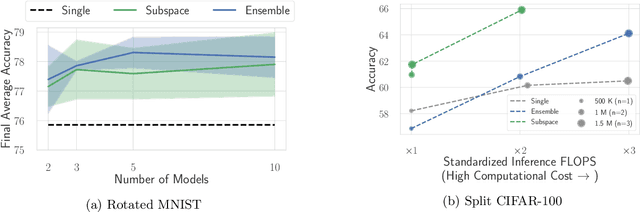
A growing body of research in continual learning focuses on the catastrophic forgetting problem. While many attempts have been made to alleviate this problem, the majority of the methods assume a single model in the continual learning setup. In this work, we question this assumption and show that employing ensemble models can be a simple yet effective method to improve continual performance. However, the training and inference cost of ensembles can increase linearly with the number of models. Motivated by this limitation, we leverage the recent advances in the deep learning optimization literature, such as mode connectivity and neural network subspaces, to derive a new method that is both computationally advantageous and can outperform the state-of-the-art continual learning algorithms.
Domain Adversarial Reinforcement Learning
Feb 14, 2021

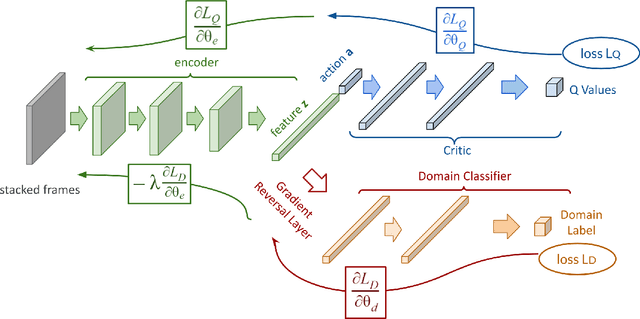
We consider the problem of generalization in reinforcement learning where visual aspects of the observations might differ, e.g. when there are different backgrounds or change in contrast, brightness, etc. We assume that our agent has access to only a few of the MDPs from the MDP distribution during training. The performance of the agent is then reported on new unknown test domains drawn from the distribution (e.g. unseen backgrounds). For this "zero-shot RL" task, we enforce invariance of the learned representations to visual domains via a domain adversarial optimization process. We empirically show that this approach allows achieving a significant generalization improvement to new unseen domains.
Regularized Inverse Reinforcement Learning
Oct 07, 2020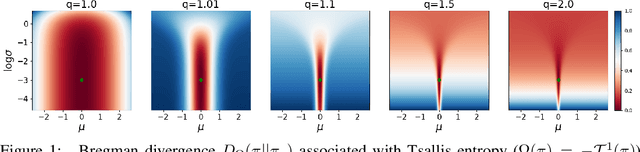

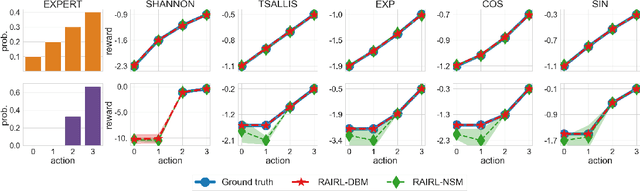

Inverse Reinforcement Learning (IRL) aims to facilitate a learner's ability to imitate expert behavior by acquiring reward functions that explain the expert's decisions. Regularized IRL applies convex regularizers to the learner's policy in order to avoid the expert's behavior being rationalized by arbitrary constant rewards, also known as degenerate solutions. We propose analytical solutions, and practical methods to obtain them, for regularized IRL. Current methods are restricted to the maximum-entropy IRL framework, limiting them to Shannon-entropy regularizers, as well as proposing functional-form solutions that are generally intractable. We present theoretical backing for our proposed IRL method's applicability to both discrete and continuous controls and empirically validate its performance on a variety of tasks.
A Theoretical Analysis of Catastrophic Forgetting through the NTK Overlap Matrix
Oct 07, 2020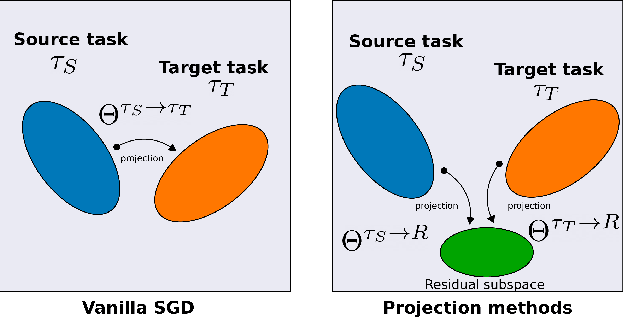
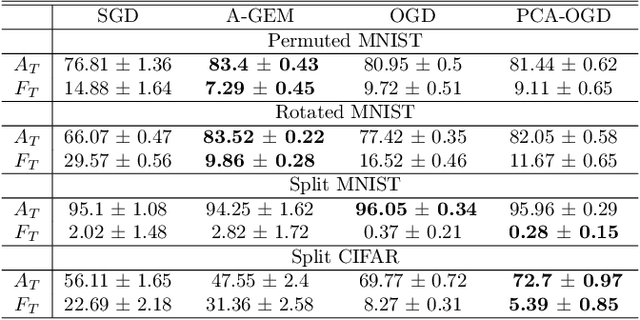
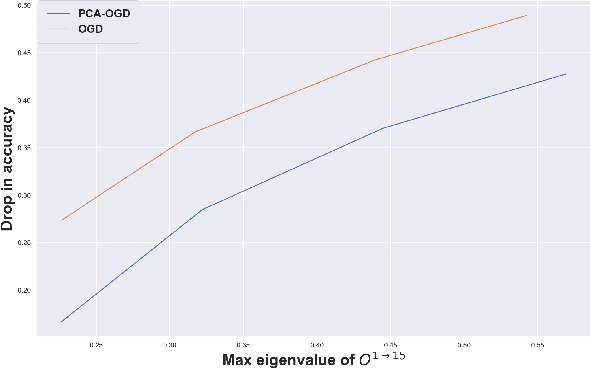

Continual learning (CL) is a setting in which an agent has to learn from an incoming stream of data during its entire lifetime. Although major advances have been made in the field, one recurring problem which remains unsolved is that of Catastrophic Forgetting (CF). While the issue has been extensively studied empirically, little attention has been paid from a theoretical angle. In this paper, we show that the impact of CF increases as two tasks increasingly align. We introduce a measure of task similarity called the NTK overlap matrix which is at the core of CF. We analyze common projected gradient algorithms and demonstrate how they mitigate forgetting. Then, we propose a variant of Orthogonal Gradient Descent (OGD) which leverages structure of the data through Principal Component Analysis (PCA). Experiments support our theoretical findings and show how our method reduces CF on classical CL datasets.