 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Continual Learning Ensembles in Neural Network Subspaces
Feb 20, 2022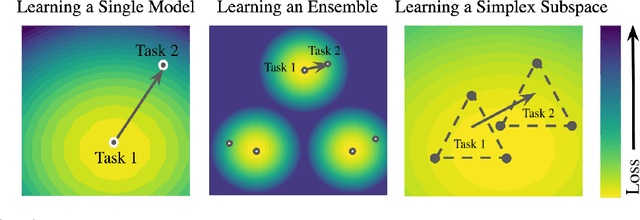
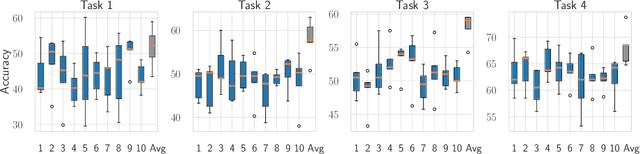

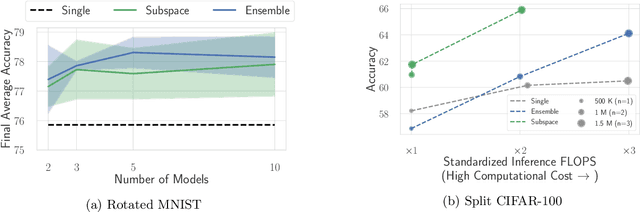
A growing body of research in continual learning focuses on the catastrophic forgetting problem. While many attempts have been made to alleviate this problem, the majority of the methods assume a single model in the continual learning setup. In this work, we question this assumption and show that employing ensemble models can be a simple yet effective method to improve continual performance. However, the training and inference cost of ensembles can increase linearly with the number of models. Motivated by this limitation, we leverage the recent advances in the deep learning optimization literature, such as mode connectivity and neural network subspaces, to derive a new method that is both computationally advantageous and can outperform the state-of-the-art continual learning algorithms.
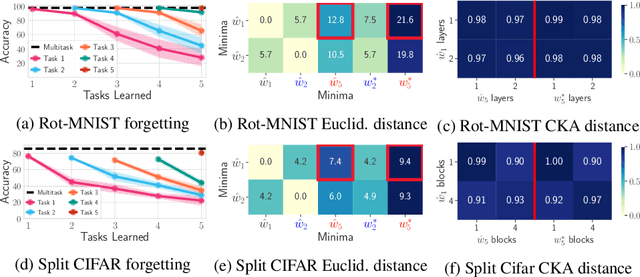
Architecture Matters in Continual Learning
Feb 01, 2022

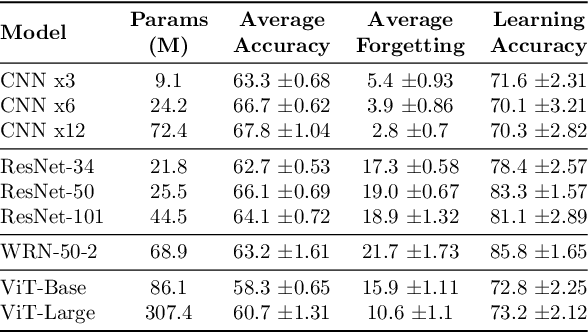

A large body of research in continual learning is devoted to overcoming the catastrophic forgetting of neural networks by designing new algorithms that are robust to the distribution shifts. However, the majority of these works are strictly focused on the "algorithmic" part of continual learning for a "fixed neural network architecture", and the implications of using different architectures are mostly neglected. Even the few existing continual learning methods that modify the model assume a fixed architecture and aim to develop an algorithm that efficiently uses the model throughout the learning experience. However, in this work, we show that the choice of architecture can significantly impact the continual learning performance, and different architectures lead to different trade-offs between the ability to remember previous tasks and learning new ones. Moreover, we study the impact of various architectural decisions, and our findings entail best practices and recommendations that can improve the continual learning performance.
Wide Neural Networks Forget Less Catastrophically
Oct 21, 2021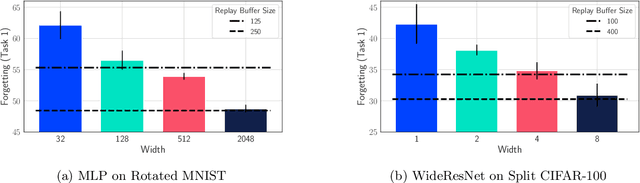
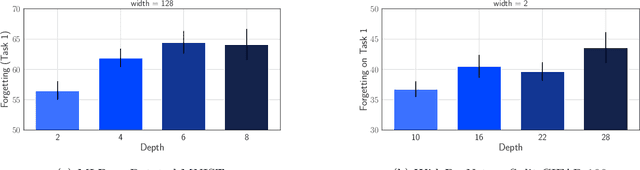
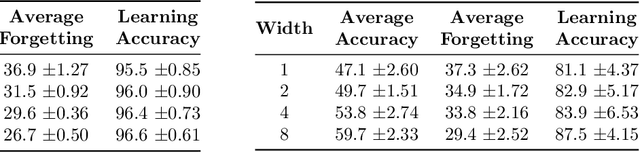
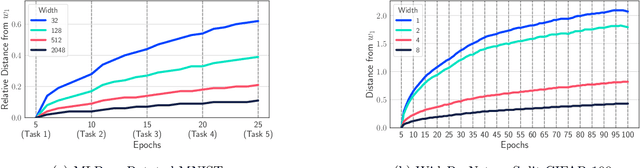
A growing body of research in continual learning is devoted to overcoming the "Catastrophic Forgetting" of neural networks by designing new algorithms that are more robust to the distribution shifts. While the recent progress in continual learning literature is encouraging, our understanding of what properties of neural networks contribute to catastrophic forgetting is still limited. To address this, instead of focusing on continual learning algorithms, in this work, we focus on the model itself and study the impact of "width" of the neural network architecture on catastrophic forgetting, and show that width has a surprisingly significant effect on forgetting. To explain this effect, we study the learning dynamics of the network from various perspectives such as gradient norm and sparsity, orthogonalization, and lazy training regime. We provide potential explanations that are consistent with the empirical results across different architectures and continual learning benchmarks.
Inter-Beat Interval Estimation with Tiramisu Model: A Novel Approach with Reduced Error
Jul 01, 2021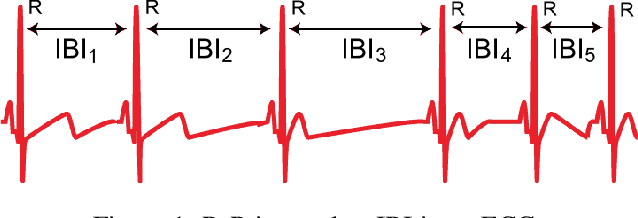
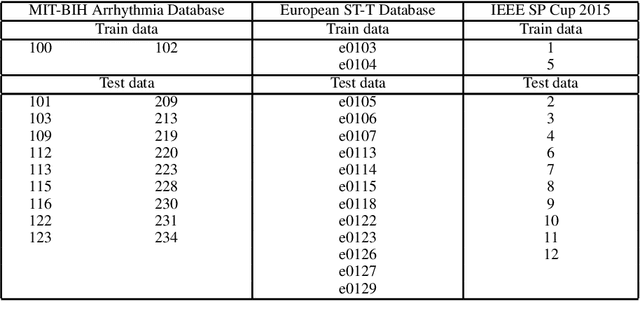
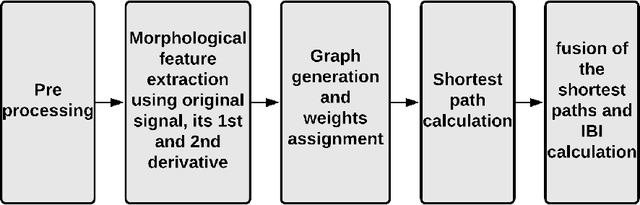
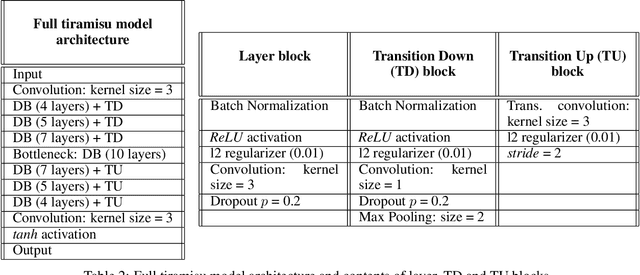
Inter-beat interval (IBI) measurement enables estimation of heart-rate variability (HRV) which, in turns, can provide early indication of potential cardiovascular diseases. However, extracting IBIs from noisy signals is challenging since the morphology of the signal is distorted in the presence of the noise. Electrocardiogram (ECG) of a person in heavy motion is highly corrupted with noise, known as motion-artifact, and IBI extracted from it is inaccurate. As a part of remote health monitoring and wearable system development, denoising ECG signals and estimating IBIs correctly from them have become an emerging topic among signal-processing researchers. Apart from conventional methods, deep-learning techniques have been successfully used in signal denoising recently, and diagnosis process has become easier, leading to accuracy levels that were previously unachievable. We propose a deep-learning approach leveraging tiramisu autoencoder model to suppress motion-artifact noise and make the R-peaks of the ECG signal prominent even in the presence of high-intensity motion. After denoising, IBIs are estimated more accurately expediting diagnosis tasks. Results illustrate that our method enables IBI estimation from noisy ECG signals with SNR up to -30dB with average root mean square error (RMSE) of 13 milliseconds for estimated IBIs. At this noise level, our error percentage remains below 8% and outperforms other state of the art techniques.
Linear Mode Connectivity in Multitask and Continual Learning
Oct 09, 2020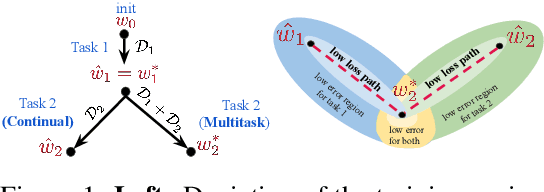


Continual (sequential) training and multitask (simultaneous) training are often attempting to solve the same overall objective: to find a solution that performs well on all considered tasks. The main difference is in the training regimes, where continual learning can only have access to one task at a time, which for neural networks typically leads to catastrophic forgetting. That is, the solution found for a subsequent task does not perform well on the previous ones anymore. However, the relationship between the different minima that the two training regimes arrive at is not well understood. What sets them apart? Is there a local structure that could explain the difference in performance achieved by the two different schemes? Motivated by recent work showing that different minima of the same task are typically connected by very simple curves of low error, we investigate whether multitask and continual solutions are similarly connected. We empirically find that indeed such connectivity can be reliably achieved and, more interestingly, it can be done by a linear path, conditioned on having the same initialization for both. We thoroughly analyze this observation and discuss its significance for the continual learning process. Furthermore, we exploit this finding to propose an effective algorithm that constrains the sequentially learned minima to behave as the multitask solution. We show that our method outperforms several state of the art continual learning algorithms on various vision benchmarks.
Understanding the Role of Training Regimes in Continual Learning
Jun 12, 2020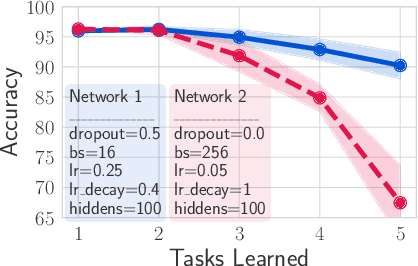
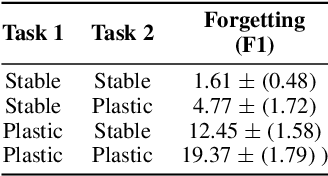
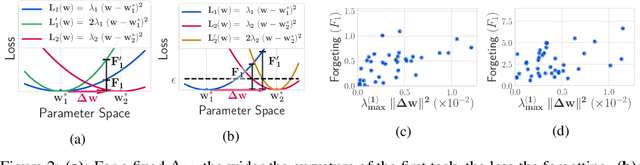
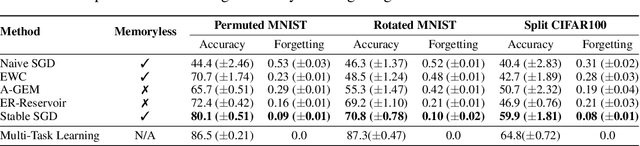
Catastrophic forgetting affects the training of neural networks, limiting their ability to learn multiple tasks sequentially. From the perspective of the well established plasticity-stability dilemma, neural networks tend to be overly plastic, lacking the stability necessary to prevent the forgetting of previous knowledge, which means that as learning progresses, networks tend to forget previously seen tasks. This phenomenon coined in the continual learning literature, has attracted much attention lately, and several families of approaches have been proposed with different degrees of success. However, there has been limited prior work extensively analyzing the impact that different training regimes -- learning rate, batch size, regularization method-- can have on forgetting. In this work, we depart from the typical approach of altering the learning algorithm to improve stability. Instead, we hypothesize that the geometrical properties of the local minima found for each task play an important role in the overall degree of forgetting. In particular, we study the effect of dropout, learning rate decay, and batch size, on forming training regimes that widen the tasks' local minima and consequently, on helping it not to forget catastrophically. Our study provides practical insights to improve stability via simple yet effective techniques that outperform alternative baselines.