 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM Planning Capabilities through Intrinsic Self-Critique
Dec 30, 2025We demonstrate an approach for LLMs to critique their \emph{own} answers with the goal of enhancing their performance that leads to significant improvements over established planning benchmarks. Despite the findings of earlier research that has cast doubt on the effectiveness of LLMs leveraging self critique methods, we show significant performance gains on planning datasets in the Blocksworld domain through intrinsic self-critique, without external source such as a verifier. We also demonstrate similar improvements on Logistics and Mini-grid datasets, exceeding strong baseline accuracies. We employ a few-shot learning technique and progressively extend it to a many-shot approach as our base method and demonstrate that it is possible to gain substantial improvement on top of this already competitive approach by employing an iterative process for correction and refinement. We illustrate how self-critique can significantly boost planning performance. Our empirical results present new state-of-the-art on the class of models considered, namely LLM model checkpoints from October 2024. Our primary focus lies on the method itself, demonstrating intrinsic self-improvement capabilities that are applicable regardless of the specific model version, and we believe that applying our method to more complex search techniques and more capable models will lead to even better performance.
Finetuning Language Models to Emit Linguistic Expressions of Uncertainty
Sep 18, 2024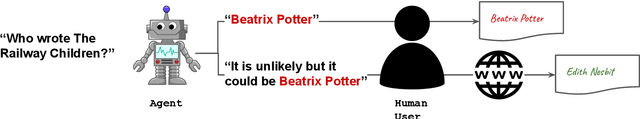

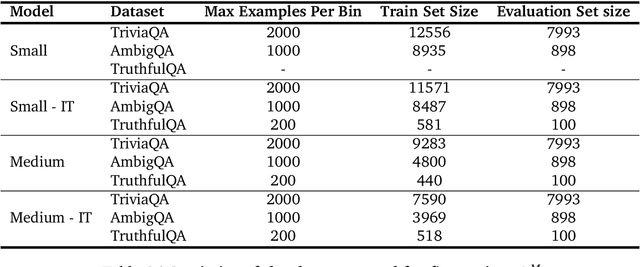
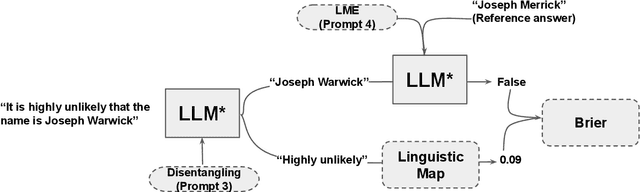
Large language models (LLMs) are increasingly employed in information-seeking and decision-making tasks. Despite their broad utility, LLMs tend to generate information that conflicts with real-world facts, and their persuasive style can make these inaccuracies appear confident and convincing. As a result, end-users struggle to consistently align the confidence expressed by LLMs with the accuracy of their predictions, often leading to either blind trust in all outputs or a complete disregard for their reliability. In this work, we explore supervised finetuning on uncertainty-augmented predictions as a method to develop models that produce linguistic expressions of uncertainty. Specifically, we measure the calibration of pre-trained models and then fine-tune language models to generate calibrated linguistic expressions of uncertainty. Through experiments on various question-answering datasets, we demonstrate that LLMs are well-calibrated in assessing their predictions, and supervised finetuning based on the model's own confidence leads to well-calibrated expressions of uncertainty, particularly for single-claim answers.
Is forgetting less a good inductive bias for forward transfer?
Mar 14, 2023



One of the main motivations of studying continual learning is that the problem setting allows a model to accrue knowledge from past tasks to learn new tasks more efficiently. However, recent studies suggest that the key metric that continual learning algorithms optimize, reduction in catastrophic forgetting, does not correlate well with the forward transfer of knowledge. We believe that the conclusion previous works reached is due to the way they measure forward transfer. We argue that the measure of forward transfer to a task should not be affected by the restrictions placed on the continual learner in order to preserve knowledge of previous tasks. Instead, forward transfer should be measured by how easy it is to learn a new task given a set of representations produced by continual learning on previous tasks. Under this notion of forward transfer, we evaluate different continual learning algorithms on a variety of image classification benchmarks. Our results indicate that less forgetful representations lead to a better forward transfer suggesting a strong correlation between retaining past information and learning efficiency on new tasks. Further, we found less forgetful representations to be more diverse and discriminative compared to their forgetful counterparts.
* Published as a conference paper at ICLR 2023
Architecture Matters in Continual Learning
Feb 01, 2022

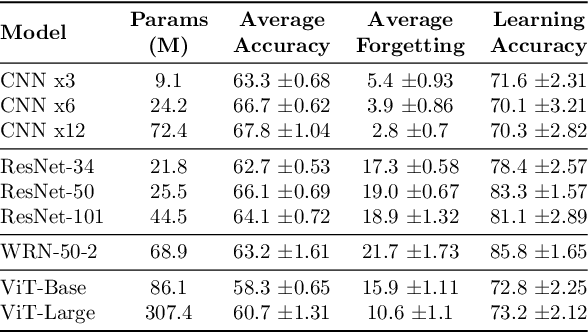

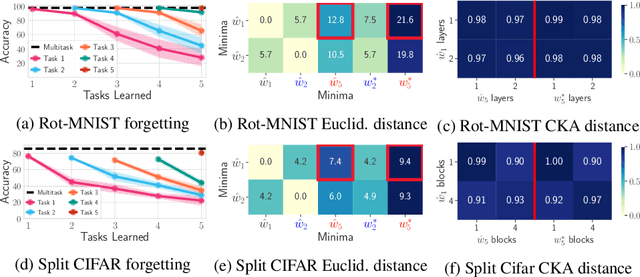
A large body of research in continual learning is devoted to overcoming the catastrophic forgetting of neural networks by designing new algorithms that are robust to the distribution shifts. However, the majority of these works are strictly focused on the "algorithmic" part of continual learning for a "fixed neural network architecture", and the implications of using different architectures are mostly neglected. Even the few existing continual learning methods that modify the model assume a fixed architecture and aim to develop an algorithm that efficiently uses the model throughout the learning experience. However, in this work, we show that the choice of architecture can significantly impact the continual learning performance, and different architectures lead to different trade-offs between the ability to remember previous tasks and learning new ones. Moreover, we study the impact of various architectural decisions, and our findings entail best practices and recommendations that can improve the continual learning performance.
One Pass ImageNet
Nov 03, 2021

We present the One Pass ImageNet (OPIN) problem, which aims to study the effectiveness of deep learning in a streaming setting. ImageNet is a widely known benchmark dataset that has helped drive and evaluate recent advancements in deep learning. Typically, deep learning methods are trained on static data that the models have random access to, using multiple passes over the dataset with a random shuffle at each epoch of training. Such data access assumption does not hold in many real-world scenarios where massive data is collected from a stream and storing and accessing all the data becomes impractical due to storage costs and privacy concerns. For OPIN, we treat the ImageNet data as arriving sequentially, and there is limited memory budget to store a small subset of the data. We observe that training a deep network in a single pass with the same training settings used for multi-epoch training results in a huge drop in prediction accuracy. We show that the performance gap can be significantly decreased by paying a small memory cost and utilizing techniques developed for continual learning, despite the fact that OPIN differs from typical continual problem settings. We propose using OPIN to study resource-efficient deep learning.
Wide Neural Networks Forget Less Catastrophically
Oct 21, 2021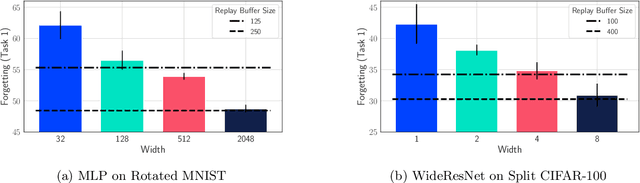
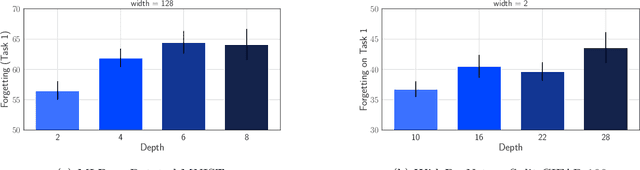
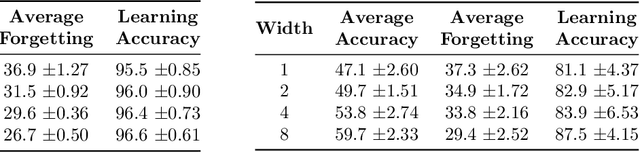
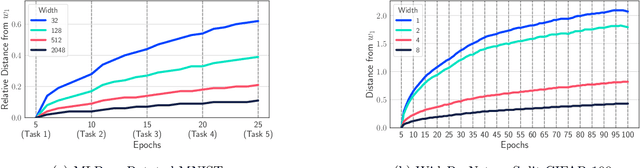
A growing body of research in continual learning is devoted to overcoming the "Catastrophic Forgetting" of neural networks by designing new algorithms that are more robust to the distribution shifts. While the recent progress in continual learning literature is encouraging, our understanding of what properties of neural networks contribute to catastrophic forgetting is still limited. To address this, instead of focusing on continual learning algorithms, in this work, we focus on the model itself and study the impact of "width" of the neural network architecture on catastrophic forgetting, and show that width has a surprisingly significant effect on forgetting. To explain this effect, we study the learning dynamics of the network from various perspectives such as gradient norm and sparsity, orthogonalization, and lazy training regime. We provide potential explanations that are consistent with the empirical results across different architectures and continual learning benchmarks.
Linear Mode Connectivity in Multitask and Continual Learning
Oct 09, 2020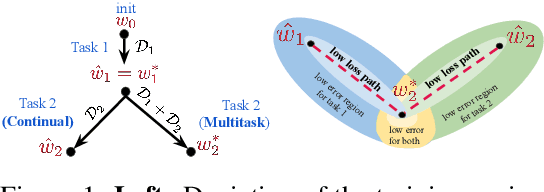


Continual (sequential) training and multitask (simultaneous) training are often attempting to solve the same overall objective: to find a solution that performs well on all considered tasks. The main difference is in the training regimes, where continual learning can only have access to one task at a time, which for neural networks typically leads to catastrophic forgetting. That is, the solution found for a subsequent task does not perform well on the previous ones anymore. However, the relationship between the different minima that the two training regimes arrive at is not well understood. What sets them apart? Is there a local structure that could explain the difference in performance achieved by the two different schemes? Motivated by recent work showing that different minima of the same task are typically connected by very simple curves of low error, we investigate whether multitask and continual solutions are similarly connected. We empirically find that indeed such connectivity can be reliably achieved and, more interestingly, it can be done by a linear path, conditioned on having the same initialization for both. We thoroughly analyze this observation and discuss its significance for the continual learning process. Furthermore, we exploit this finding to propose an effective algorithm that constrains the sequentially learned minima to behave as the multitask solution. We show that our method outperforms several state of the art continual learning algorithms on various vision benchmarks.
A maximum-entropy approach to off-policy evaluation in average-reward MDPs
Jun 17, 2020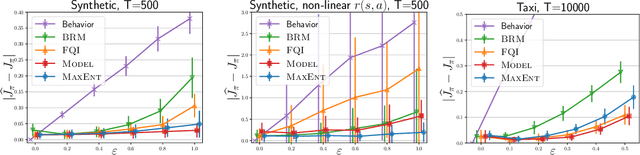
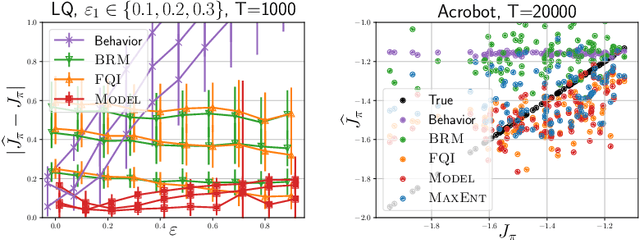
This work focuses on off-policy evaluation (OPE) with function approximation in infinite-horizon undiscounted Markov decision processes (MDPs). For MDPs that are ergodic and linear (i.e. where rewards and dynamics are linear in some known features), we provide the first finite-sample OPE error bound, extending existing results beyond the episodic and discounted cases. In a more general setting, when the feature dynamics are approximately linear and for arbitrary rewards, we propose a new approach for estimating stationary distributions with function approximation. We formulate this problem as finding the maximum-entropy distribution subject to matching feature expectations under empirical dynamics. We show that this results in an exponential-family distribution whose sufficient statistics are the features, paralleling maximum-entropy approaches in supervised learning. We demonstrate the effectiveness of the proposed OPE approaches in multiple environments.
Hybrid Models with Deep and Invertible Features
Feb 07, 2019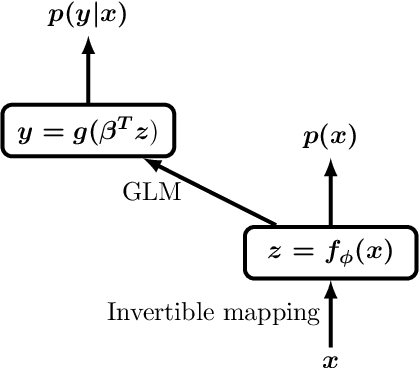
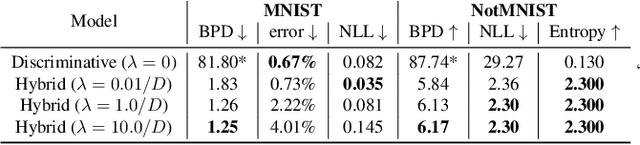
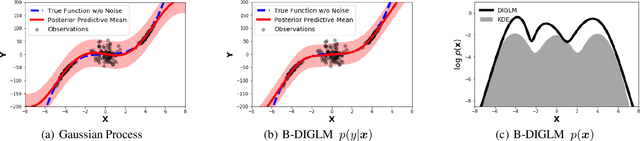
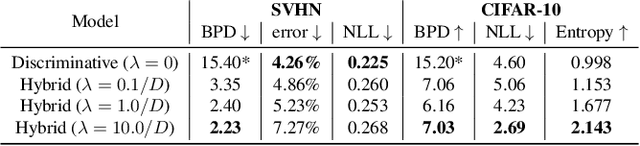
We propose a neural hybrid model consisting of a linear model defined on a set of features computed by a deep, invertible transformation (i.e. a normalizing flow). An attractive property of our model is that both p(features), the features' density, and p(targets | features), the predictive distribution, can be computed exactly in a single feed-forward pass. We show that our hybrid model, despite the invertibility constraints, achieves similar accuracy to purely predictive models. Yet the generative component remains a good model of the input features despite the hybrid optimization objective. This offers additional capabilities such as detection of out-of-distribution inputs and enabling semi-supervised learning. The availability of the exact joint density p(targets, features) also allows us to compute many quantities readily, making our hybrid model a useful building block for downstream applications of probabilistic deep learning.
Do Deep Generative Models Know What They Don't Know?
Oct 22, 2018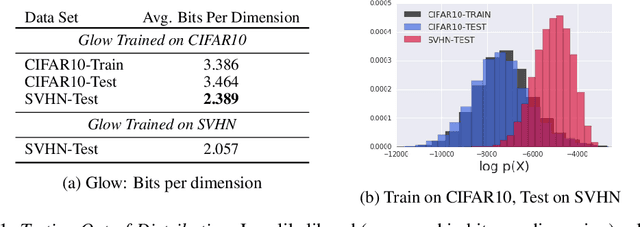
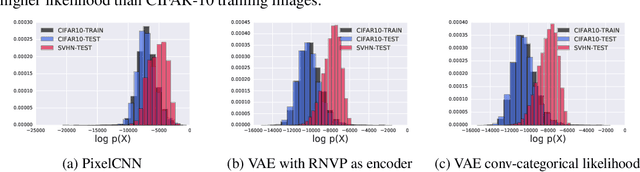
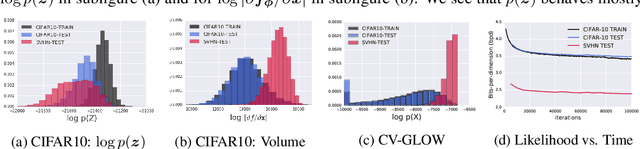
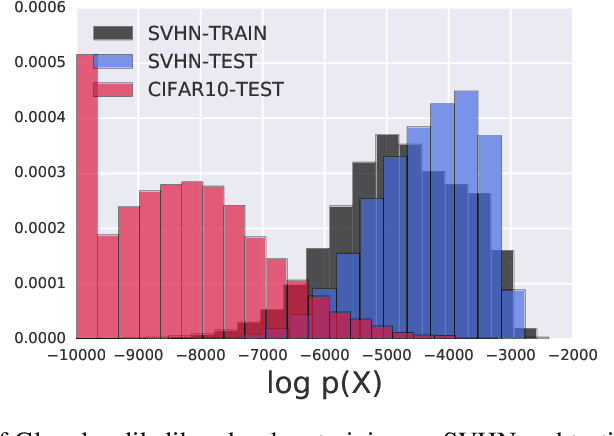
A neural network deployed in the wild may be asked to make predictions for inputs that were drawn from a different distribution than that of the training data. A plethora of work has demonstrated that it is easy to find or synthesize inputs for which a neural network is highly confident yet wrong. Generative models are widely viewed to be robust to such mistaken confidence as modeling the density of the input features can be used to detect novel, out-of-distribution inputs. In this paper we challenge this assumption. We find that the model density from flow-based models, VAEs and PixelCNN cannot distinguish images of common objects such as dogs, trucks, and horses (i.e. CIFAR-10) from those of house numbers (i.e. SVHN), assigning a higher likelihood to the latter when the model is trained on the former. We focus our analysis on flow-based generative models in particular since they are trained and evaluated via the exact marginal likelihood. We find such behavior persists even when we restrict the flow models to constant-volume transformations. These transformations admit some theoretical analysis, and we show that the difference in likelihoods can be explained by the location and variances of the data and the model curvature, which shows that such behavior is more general and not just restricted to the pairs of datasets used in our experiments. Our results caution against using the density estimates from deep generative models to identify inputs similar to the training distribution, until their behavior on out-of-distribution inputs is better understood.