 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?
Jun 03, 2026Scientific and engineering progress is fundamentally a long-horizon iterative process: proposing changes, running experiments, measuring outcomes, and continuously refining artifacts. Yet existing benchmarks for frontier models primarily evaluate either single-turn responses or short-horizon agent trajectories, failing to capture the challenges of sustained iterative improvement over extended time horizons. To address this gap, we introduce AutoLab, a new benchmark for ultra long-horizon closed-loop optimization. AutoLab consists of 36 realistic, expert-curated tasks spanning four diverse domains: system optimization, puzzle & challenge, model development, and CUDA kernel optimization. Each task begins with a correct but deliberately suboptimal baseline and challenges agents to improve it within a strict wall-clock budget. Evaluating 17 state-of-the-art models reveals the dominant predictor of success is not the quality of an agent's initial attempt, but its persistence in repeatedly benchmarking, editing, and incorporating empirical feedback. While claude-opus-4.6 exhibits strong long-horizon optimization capabilities, most frontier models, including several proprietary ones, either terminate prematurely or exhaust their budgets with minimal progress. These results underscore the importance of time awareness and persistent iteration in autonomous agents. We open-source the full benchmark, evaluation harness, and task artifacts, to accelerate research toward truly capable long-horizon agents.
Converted, Not Equivalent: Benchmarking Codebase Conversion via Observational Equivalence
May 27, 2026Coding agents increasingly act as codebase-scale collaborators that can assist with codebase conversion, but this progress has exposed a critical weakness: agents often over-trust their own local validation routines and declare success on artifacts that satisfy surface checks while violating the semantic contracts users actually care about. This problem is especially acute in codebase conversion, where prior evaluation is largely outcome-driven and therefore unstable: two implementations can match on a shallow outcome, such as a single forward loss, while diverging in gradients, optimizer behavior, or short-horizon training dynamics. We introduce T2J-Bench, a benchmark for codebase conversion that reformulates conversion as transfer under a fixed equivalence contract. A fixed verifier then compares source and converted codebases through three ordered stages: Spec (interface admissibility), Numeric (forward outputs, losses, gradients, and objective-specific tensors), and Behavioral (short training dynamics under fixed seeds). Across 355 blind conversion attempts, the best system reaches only 26.7--28.9% overall pass rate despite Spec pass rates up to 91.1%; a 4.7x token-budget spread yields only a 2.2x pass-rate spread; and all systems overestimate success by 66.6--97.8 points relative to the fixed evaluator. This suggests that failures stem more from contract-misaligned self-validation than from limited budget or backbone strength.
ScientistOne: Towards Human-Level Autonomous Research via Chain-of-Evidence
May 25, 2026Autonomous research agents produce competitive solutions and professional-looking manuscripts, yet their outputs contain verifiability failures undetectable by surface-level evaluation: fabricated citations, unreproducible scores, and method descriptions that diverge from the implementation. We address this through three contributions. First, Chain-of-Evidence (CoE), a verifiability framework requiring every claim to be traceable to its evidence source. Second, ScientistOne, an end-to-end autonomous research system that maintains evidence chains by construction throughout literature review, solution discovery, and paper writing. Third, CoE Audit, a post-hoc audit whose four integrity checks -- score verification, specification violation, reference verification, and method-code alignment -- apply uniformly to all systems. Across 75 papers spanning five systems and five frontier research tasks, every baseline exhibits at least one systematic failure mode: hallucinated reference rates reach 21%, score verification passes in as few as 42% of papers, and method-code alignment ranges from 20% to 80%. ScientistOne achieves zero hallucinated references (0/337), perfect score verification (12/12), and the highest method-code alignment (14/15), while matching or exceeding human expert performance on all five tasks. ScientistOne further generalizes to six additional tasks spanning medical imaging, fine-grained recognition, 3D perception, and language modeling, achieving state-of-the-art on Parameter Golf and gold medals on MLE-Bench tasks where baselines fail entirely.
MARS: Modular Agent with Reflective Search for Automated AI Research
Feb 02, 2026Automating AI research differs from general software engineering due to computationally expensive evaluation (e.g., model training) and opaque performance attribution. Current LLM-based agents struggle here, often generating monolithic scripts that ignore execution costs and causal factors. We introduce MARS (Modular Agent with Reflective Search), a framework optimized for autonomous AI research. MARS relies on three pillars: (1) Budget-Aware Planning via cost-constrained Monte Carlo Tree Search (MCTS) to explicitly balance performance with execution expense; (2) Modular Construction, employing a "Design-Decompose-Implement" pipeline to manage complex research repositories; and (3) Comparative Reflective Memory, which addresses credit assignment by analyzing solution differences to distill high-signal insights. MARS achieves state-of-the-art performance among open-source frameworks on MLE-Bench under comparable settings, maintaining competitiveness with the global leaderboard's top methods. Furthermore, the system exhibits qualitative "Aha!" moments, where 63% of all utilized lessons originate from cross-branch transfer, demonstrating that the agent effectively generalizes insights across search paths.
DocLens : A Tool-Augmented Multi-Agent Framework for Long Visual Document Understanding
Nov 14, 2025Comprehending long visual documents, where information is distributed across extensive pages of text and visual elements, is a critical but challenging task for modern Vision-Language Models (VLMs). Existing approaches falter on a fundamental challenge: evidence localization. They struggle to retrieve relevant pages and overlook fine-grained details within visual elements, leading to limited performance and model hallucination. To address this, we propose DocLens, a tool-augmented multi-agent framework that effectively ``zooms in'' on evidence like a lens. It first navigates from the full document to specific visual elements on relevant pages, then employs a sampling-adjudication mechanism to generate a single, reliable answer. Paired with Gemini-2.5-Pro, DocLens achieves state-of-the-art performance on MMLongBench-Doc and FinRAGBench-V, surpassing even human experts. The framework's superiority is particularly evident on vision-centric and unanswerable queries, demonstrating the power of its enhanced localization capabilities.
SETS: Leveraging Self-Verification and Self-Correction for Improved Test-Time Scaling
Jan 31, 2025



Recent advancements in Large Language Models (LLMs) have created new opportunities to enhance performance on complex reasoning tasks by leveraging test-time computation. However, conventional approaches such as repeated sampling with majority voting or reward model scoring, often face diminishing returns as test-time compute scales, in addition to requiring costly task-specific reward model training. In this paper, we present Self-Enhanced Test-Time Scaling (SETS), a novel method that leverages the self-verification and self-correction capabilities of recent advanced LLMs to overcome these limitations. SETS integrates sampling, self-verification, and self-correction into a unified framework, enabling efficient and scalable test-time computation for improved capabilities at complex tasks. Through extensive experiments on challenging planning and reasoning benchmarks, compared to the alternatives, we demonstrate that SETS achieves significant performance improvements and more favorable test-time scaling laws.
Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
Oct 09, 2024



Retrieval-Augmented Generation (RAG), while effective in integrating external knowledge to address the limitations of large language models (LLMs), can be undermined by imperfect retrieval, which may introduce irrelevant, misleading, or even malicious information. Despite its importance, previous studies have rarely explored the behavior of RAG through joint analysis on how errors from imperfect retrieval attribute and propagate, and how potential conflicts arise between the LLMs' internal knowledge and external sources. We find that imperfect retrieval augmentation might be inevitable and quite harmful, through controlled analysis under realistic conditions. We identify the knowledge conflicts between LLM-internal and external knowledge from retrieval as a bottleneck to overcome in the post-retrieval stage of RAG. To render LLMs resilient to imperfect retrieval, we propose Astute RAG, a novel RAG approach that adaptively elicits essential information from LLMs' internal knowledge, iteratively consolidates internal and external knowledge with source-awareness, and finalizes the answer according to information reliability. Our experiments using Gemini and Claude demonstrate that Astute RAG significantly outperforms previous robustness-enhanced RAG methods. Notably, Astute RAG is the only approach that matches or exceeds the performance of LLMs without RAG under worst-case scenarios. Further analysis reveals that Astute RAG effectively resolves knowledge conflicts, improving the reliability and trustworthiness of RAG systems.
Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs
Oct 18, 2023Large language models (LLMs) have recently shown great advances in a variety of tasks, including natural language understanding and generation. However, their use in high-stakes decision-making scenarios is still limited due to the potential for errors. Selective prediction is a technique that can be used to improve the reliability of the LLMs by allowing them to abstain from making predictions when they are unsure of the answer. In this work, we propose a novel framework for adaptation with self-evaluation to improve the selective prediction performance of LLMs. Our framework is based on the idea of using parameter-efficient tuning to adapt the LLM to the specific task at hand while improving its ability to perform self-evaluation. We evaluate our method on a variety of question-answering (QA) datasets and show that it outperforms state-of-the-art selective prediction methods. For example, on the CoQA benchmark, our method improves the AUACC from 91.23% to 92.63% and improves the AUROC from 74.61% to 80.25%.
Two Heads are Better than One: Towards Better Adversarial Robustness by Combining Transduction and Rejection
May 27, 2023


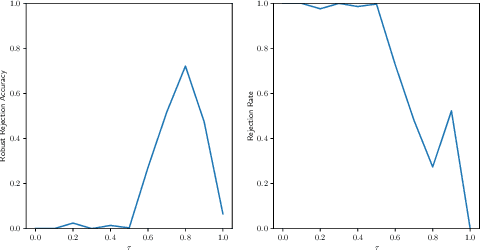
Both transduction and rejection have emerged as important techniques for defending against adversarial perturbations. A recent work by Tram\`er showed that, in the rejection-only case (no transduction), a strong rejection-solution can be turned into a strong (but computationally inefficient) non-rejection solution. This detector-to-classifier reduction has been mostly applied to give evidence that certain claims of strong selective-model solutions are susceptible, leaving the benefits of rejection unclear. On the other hand, a recent work by Goldwasser et al. showed that rejection combined with transduction can give provable guarantees (for certain problems) that cannot be achieved otherwise. Nevertheless, under recent strong adversarial attacks (GMSA, which has been shown to be much more effective than AutoAttack against transduction), Goldwasser et al.'s work was shown to have low performance in a practical deep-learning setting. In this paper, we take a step towards realizing the promise of transduction+rejection in more realistic scenarios. Theoretically, we show that a novel application of Tram\`er's classifier-to-detector technique in the transductive setting can give significantly improved sample-complexity for robust generalization. While our theoretical construction is computationally inefficient, it guides us to identify an efficient transductive algorithm to learn a selective model. Extensive experiments using state of the art attacks (AutoAttack, GMSA) show that our solutions provide significantly better robust accuracy.
Stratified Adversarial Robustness with Rejection
May 12, 2023



Recently, there is an emerging interest in adversarially training a classifier with a rejection option (also known as a selective classifier) for boosting adversarial robustness. While rejection can incur a cost in many applications, existing studies typically associate zero cost with rejecting perturbed inputs, which can result in the rejection of numerous slightly-perturbed inputs that could be correctly classified. In this work, we study adversarially-robust classification with rejection in the stratified rejection setting, where the rejection cost is modeled by rejection loss functions monotonically non-increasing in the perturbation magnitude. We theoretically analyze the stratified rejection setting and propose a novel defense method -- Adversarial Training with Consistent Prediction-based Rejection (CPR) -- for building a robust selective classifier. Experiments on image datasets demonstrate that the proposed method significantly outperforms existing methods under strong adaptive attacks. For instance, on CIFAR-10, CPR reduces the total robust loss (for different rejection losses) by at least 7.3% under both seen and unseen attacks.