 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCell Library Characterization for Composite Current Source Models Based on Gaussian Process Regression and Active Learning
May 16, 2025The composite current source (CCS) model has been adopted as an advanced timing model that represents the current behavior of cells for improved accuracy and better capability than traditional non-linear delay models (NLDM) to model complex dynamic effects and interactions under advanced process nodes. However, the high accuracy requirement, large amount of data and extensive simulation cost pose severe challenges to CCS characterization. To address these challenges, we introduce a novel Gaussian Process Regression(GPR) model with active learning(AL) to establish the characterization framework efficiently and accurately. Our approach significantly outperforms conventional commercial tools as well as learning based approaches by achieving an average absolute error of 2.05 ps and a relative error of 2.27% for current waveform of 57 cells under 9 process, voltage, temperature (PVT) corners with TSMC 22nm process. Additionally, our model drastically reduces the runtime to 27% and the storage by up to 19.5x compared with that required by commercial tools.
On the Adversarial Vulnerabilities of Transfer Learning in Remote Sensing
Jan 20, 2025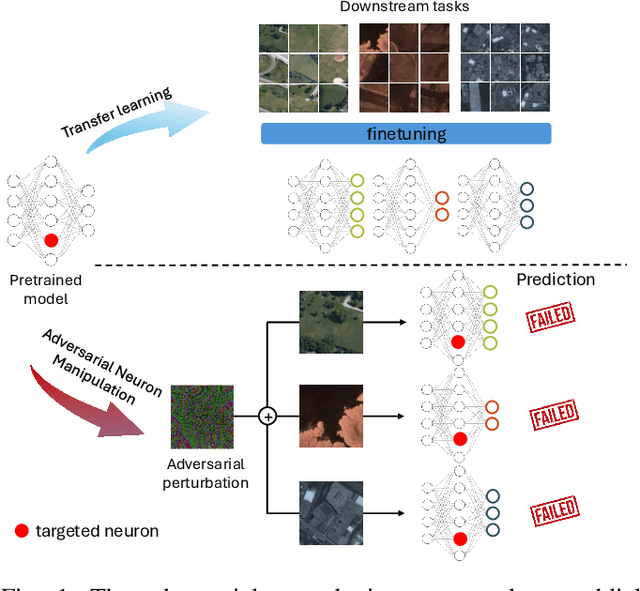
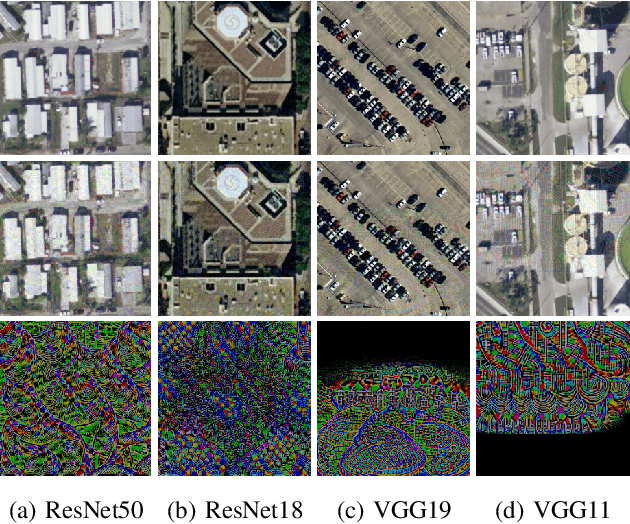
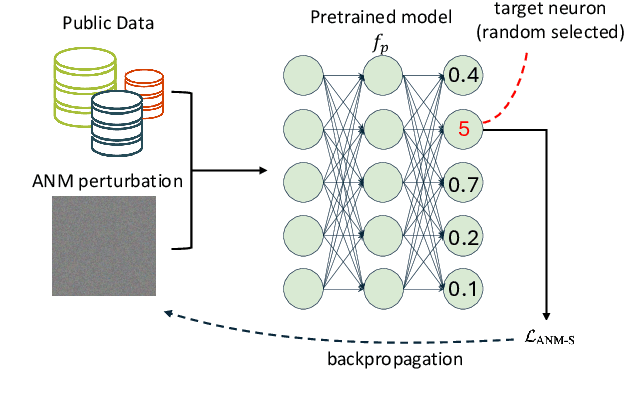
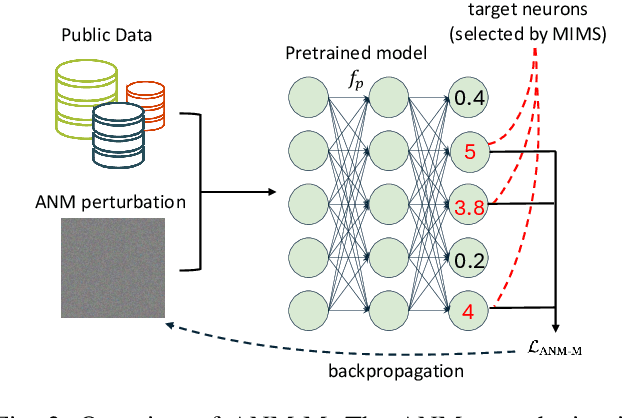
The use of pretrained models from general computer vision tasks is widespread in remote sensing, significantly reducing training costs and improving performance. However, this practice also introduces vulnerabilities to downstream tasks, where publicly available pretrained models can be used as a proxy to compromise downstream models. This paper presents a novel Adversarial Neuron Manipulation method, which generates transferable perturbations by selectively manipulating single or multiple neurons in pretrained models. Unlike existing attacks, this method eliminates the need for domain-specific information, making it more broadly applicable and efficient. By targeting multiple fragile neurons, the perturbations achieve superior attack performance, revealing critical vulnerabilities in deep learning models. Experiments on diverse models and remote sensing datasets validate the effectiveness of the proposed method. This low-access adversarial neuron manipulation technique highlights a significant security risk in transfer learning models, emphasizing the urgent need for more robust defenses in their design when addressing the safety-critical remote sensing tasks.
Towards Adversarially Robust Continual Learning
Mar 31, 2023
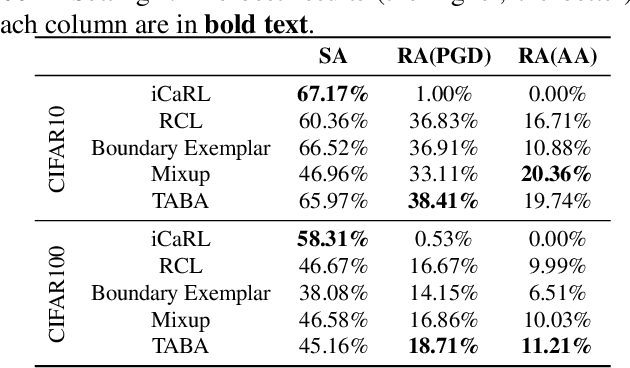


Recent studies show that models trained by continual learning can achieve the comparable performances as the standard supervised learning and the learning flexibility of continual learning models enables their wide applications in the real world. Deep learning models, however, are shown to be vulnerable to adversarial attacks. Though there are many studies on the model robustness in the context of standard supervised learning, protecting continual learning from adversarial attacks has not yet been investigated. To fill in this research gap, we are the first to study adversarial robustness in continual learning and propose a novel method called \textbf{T}ask-\textbf{A}ware \textbf{B}oundary \textbf{A}ugmentation (TABA) to boost the robustness of continual learning models. With extensive experiments on CIFAR-10 and CIFAR-100, we show the efficacy of adversarial training and TABA in defending adversarial attacks.
AI Security for Geoscience and Remote Sensing: Challenges and Future Trends
Dec 19, 2022Recent advances in artificial intelligence (AI) have significantly intensified research in the geoscience and remote sensing (RS) field. AI algorithms, especially deep learning-based ones, have been developed and applied widely to RS data analysis. The successful application of AI covers almost all aspects of Earth observation (EO) missions, from low-level vision tasks like super-resolution, denoising, and inpainting, to high-level vision tasks like scene classification, object detection, and semantic segmentation. While AI techniques enable researchers to observe and understand the Earth more accurately, the vulnerability and uncertainty of AI models deserve further attention, considering that many geoscience and RS tasks are highly safety-critical. This paper reviews the current development of AI security in the geoscience and RS field, covering the following five important aspects: adversarial attack, backdoor attack, federated learning, uncertainty, and explainability. Moreover, the potential opportunities and trends are discussed to provide insights for future research. To the best of the authors' knowledge, this paper is the first attempt to provide a systematic review of AI security-related research in the geoscience and RS community. Available code and datasets are also listed in the paper to move this vibrant field of research forward.
Memory-Based Label-Text Tuning for Few-Shot Class-Incremental Learning
Jul 03, 2022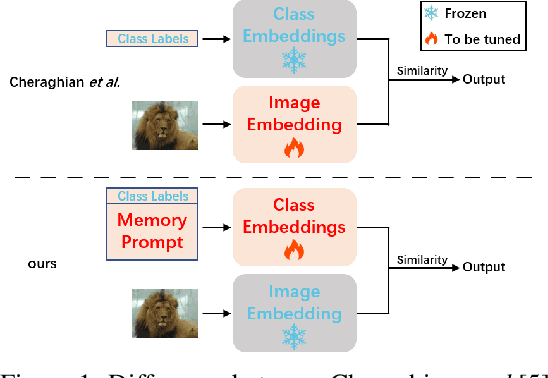
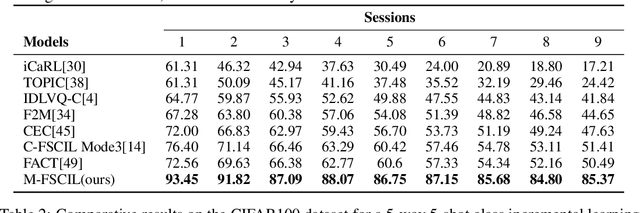
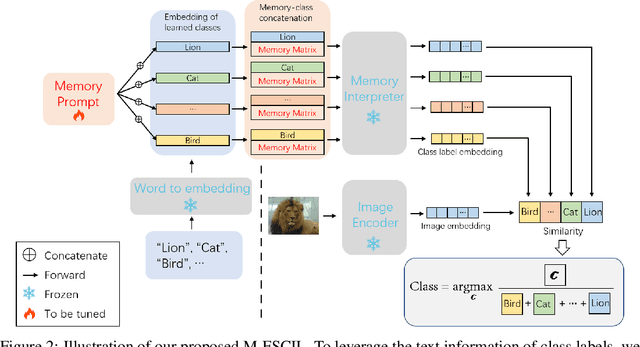
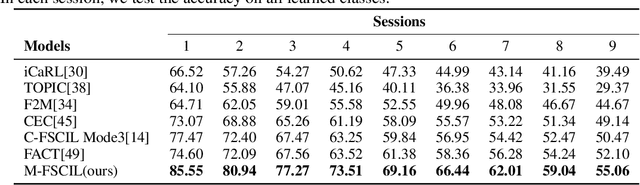
Few-shot class-incremental learning(FSCIL) focuses on designing learning algorithms that can continually learn a sequence of new tasks from a few samples without forgetting old ones. The difficulties are that training on a sequence of limited data from new tasks leads to severe overfitting issues and causes the well-known catastrophic forgetting problem. Existing researches mainly utilize the image information, such as storing the image knowledge of previous tasks or limiting classifiers updating. However, they ignore analyzing the informative and less noisy text information of class labels. In this work, we propose leveraging the label-text information by adopting the memory prompt. The memory prompt can learn new data sequentially, and meanwhile store the previous knowledge. Furthermore, to optimize the memory prompt without undermining the stored knowledge, we propose a stimulation-based training strategy. It optimizes the memory prompt depending on the image embedding stimulation, which is the distribution of the image embedding elements. Experiments show that our proposed method outperforms all prior state-of-the-art approaches, significantly mitigating the catastrophic forgetting and overfitting problems.
Switchable Representation Learning Framework with Self-compatibility
Jun 16, 2022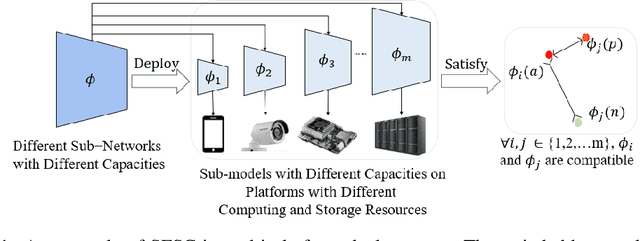

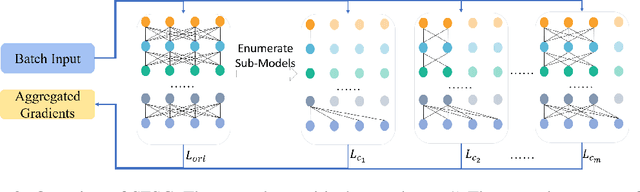
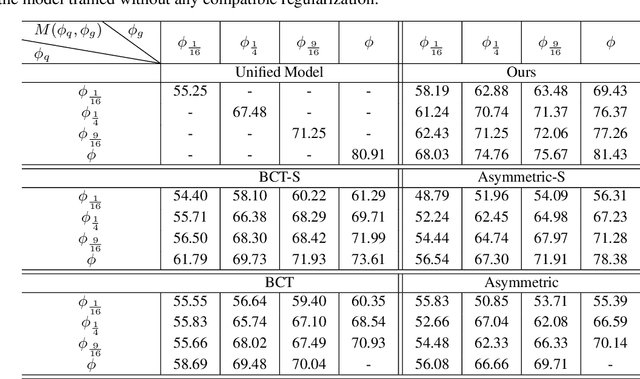
Real-world visual search systems involve deployments on multiple platforms with different computing and storage resources. Deploying a unified model that suits the minimal-constrain platforms leads to limited accuracy. It is expected to deploy models with different capacities adapting to the resource constraints, which requires features extracted by these models to be aligned in the metric space. The method to achieve feature alignments is called "compatible learning". Existing research mainly focuses on the one-to-one compatible paradigm, which is limited in learning compatibility among multiple models. We propose a Switchable representation learning Framework with Self-Compatibility (SFSC). SFSC generates a series of compatible sub-models with different capacities through one training process. The optimization of sub-models faces gradients conflict, and we mitigate it from the perspective of the magnitude and direction. We adjust the priorities of sub-models dynamically through uncertainty estimation to co-optimize sub-models properly. Besides, the gradients with conflicting directions are projected to avoid mutual interference. SFSC achieves state-of-art performance on the evaluated dataset.
Towards Efficiently Evaluating the Robustness of Deep Neural Networks in IoT Systems: A GAN-based Method
Nov 19, 2021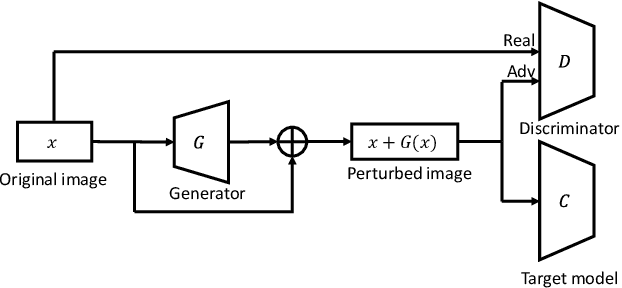
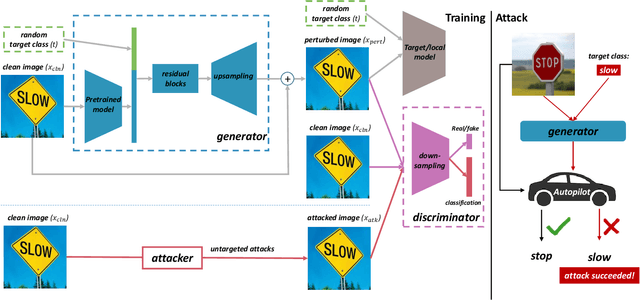

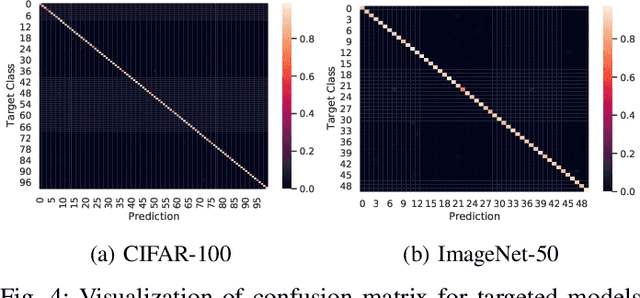
Intelligent Internet of Things (IoT) systems based on deep neural networks (DNNs) have been widely deployed in the real world. However, DNNs are found to be vulnerable to adversarial examples, which raises people's concerns about intelligent IoT systems' reliability and security. Testing and evaluating the robustness of IoT systems becomes necessary and essential. Recently various attacks and strategies have been proposed, but the efficiency problem remains unsolved properly. Existing methods are either computationally extensive or time-consuming, which is not applicable in practice. In this paper, we propose a novel framework called Attack-Inspired GAN (AI-GAN) to generate adversarial examples conditionally. Once trained, it can generate adversarial perturbations efficiently given input images and target classes. We apply AI-GAN on different datasets in white-box settings, black-box settings and targeted models protected by state-of-the-art defenses. Through extensive experiments, AI-GAN achieves high attack success rates, outperforming existing methods, and reduces generation time significantly. Moreover, for the first time, AI-GAN successfully scales to complex datasets e.g. CIFAR-100 and ImageNet, with about $90\%$ success rates among all classes.
Adversarial Purification through Representation Disentanglement
Oct 15, 2021
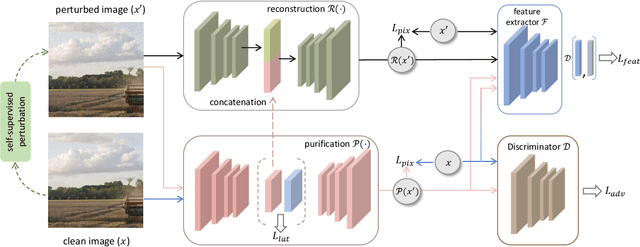


Deep learning models are vulnerable to adversarial examples and make incomprehensible mistakes, which puts a threat on their real-world deployment. Combined with the idea of adversarial training, preprocessing-based defenses are popular and convenient to use because of their task independence and good generalizability. Current defense methods, especially purification, tend to remove ``noise" by learning and recovering the natural images. However, different from random noise, the adversarial patterns are much easier to be overfitted during model training due to their strong correlation to the images. In this work, we propose a novel adversarial purification scheme by presenting disentanglement of natural images and adversarial perturbations as a preprocessing defense. With extensive experiments, our defense is shown to be generalizable and make significant protection against unseen strong adversarial attacks. It reduces the success rates of state-of-the-art \textbf{ensemble} attacks from \textbf{61.7\%} to \textbf{14.9\%} on average, superior to a number of existing methods. Notably, our defense restores the perturbed images perfectly and does not hurt the clean accuracy of backbone models, which is highly desirable in practice.
Neighborhood Consensus Contrastive Learning for Backward-Compatible Representation
Sep 09, 2021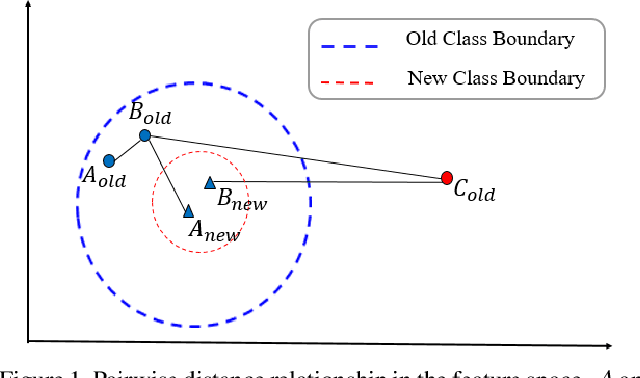
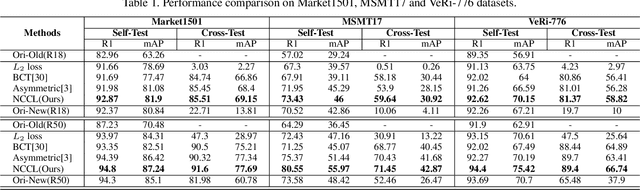
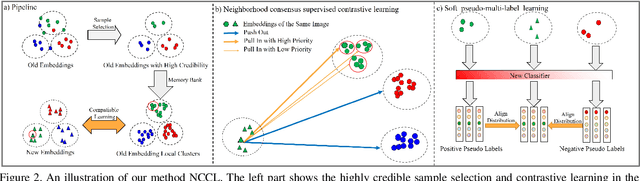
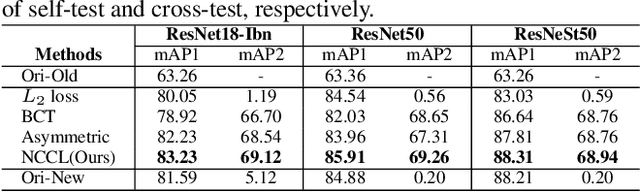
In object re-identification (ReID), the development of deep learning techniques often involves model updates and deployment. It is unbearable to re-embedding and re-index with the system suspended when deploying new models. Therefore, backward-compatible representation is proposed to enable "new" features to be compared with "old" features directly, which means that the database is active when there are both "new" and "old" features in it. Thus we can scroll-refresh the database or even do nothing on the database to update. The existing backward-compatible methods either require a strong overlap between old and new training data or simply conduct constraints at the instance level. Thus they are difficult in handling complicated cluster structures and are limited in eliminating the impact of outliers in old embeddings, resulting in a risk of damaging the discriminative capability of new features. In this work, we propose a Neighborhood Consensus Contrastive Learning (NCCL) method. With no assumptions about the new training data, we estimate the sub-cluster structures of old embeddings. A new embedding is constrained with multiple old embeddings in both embedding space and discrimination space at the sub-class level. The effect of outliers diminished, as the multiple samples serve as "mean teachers". Besides, we also propose a scheme to filter the old embeddings with low credibility, further improving the compatibility robustness. Our method ensures backward compatibility without impairing the accuracy of the new model. And it can even improve the new model's accuracy in most scenarios.
Inconspicuous Adversarial Patches for Fooling Image Recognition Systems on Mobile Devices
Jun 29, 2021



Deep learning based image recognition systems have been widely deployed on mobile devices in today's world. In recent studies, however, deep learning models are shown vulnerable to adversarial examples. One variant of adversarial examples, called adversarial patch, draws researchers' attention due to its strong attack abilities. Though adversarial patches achieve high attack success rates, they are easily being detected because of the visual inconsistency between the patches and the original images. Besides, it usually requires a large amount of data for adversarial patch generation in the literature, which is computationally expensive and time-consuming. To tackle these challenges, we propose an approach to generate inconspicuous adversarial patches with one single image. In our approach, we first decide the patch locations basing on the perceptual sensitivity of victim models, then produce adversarial patches in a coarse-to-fine way by utilizing multiple-scale generators and discriminators. The patches are encouraged to be consistent with the background images with adversarial training while preserving strong attack abilities. Our approach shows the strong attack abilities in white-box settings and the excellent transferability in black-box settings through extensive experiments on various models with different architectures and training methods. Compared to other adversarial patches, our adversarial patches hold the most negligible risks to be detected and can evade human observations, which is supported by the illustrations of saliency maps and results of user evaluations. Lastly, we show that our adversarial patches can be applied in the physical world.