 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Deep Network Balance Copy-Move Forgery Detection and Distinguishment?
May 17, 2023Copy-move forgery detection is a crucial research area within digital image forensics, as it focuses on identifying instances where objects in an image are duplicated and placed in different locations. The detection of such forgeries is particularly important in contexts where they can be exploited for malicious purposes. Recent years have witnessed an increased interest in distinguishing between the original and duplicated objects in copy-move forgeries, accompanied by the development of larger-scale datasets to facilitate this task. However, existing approaches to copy-move forgery detection and source/target differentiation often involve two separate steps or the design of individual end-to-end networks for each task. In this paper, we propose an innovative method that employs the transformer architecture in an end-to-end deep neural network. Our method aims to detect instances of copy-move forgery while simultaneously localizing the source and target regions. By utilizing this approach, we address the challenges posed by multi-object copy-move scenarios and report if there is a balance between the detection and differentiation tasks. To evaluate the performance of our proposed network, we conducted experiments on two publicly available copy-move datasets. The results and analysis aims to show the potential significance of our focus in balancing detection and distinguishment result and transferring the trained model in different datasets in the field.
Changes to Captions: An Attentive Network for Remote Sensing Change Captioning
Apr 03, 2023



In recent years, advanced research has focused on the direct learning and analysis of remote sensing images using natural language processing (NLP) techniques. The ability to accurately describe changes occurring in multi-temporal remote sensing images is becoming increasingly important for geospatial understanding and land planning. Unlike natural image change captioning tasks, remote sensing change captioning aims to capture the most significant changes, irrespective of various influential factors such as illumination, seasonal effects, and complex land covers. In this study, we highlight the significance of accurately describing changes in remote sensing images and present a comparison of the change captioning task for natural and synthetic images and remote sensing images. To address the challenge of generating accurate captions, we propose an attentive changes-to-captions network, called Chg2Cap for short, for bi-temporal remote sensing images. The network comprises three main components: 1) a Siamese CNN-based feature extractor to collect high-level representations for each image pair; 2) an attentive decoder that includes a hierarchical self-attention block to locate change-related features and a residual block to generate the image embedding; and 3) a transformer-based caption generator to decode the relationship between the image embedding and the word embedding into a description. The proposed Chg2Cap network is evaluated on two representative remote sensing datasets, and a comprehensive experimental analysis is provided. The code and pre-trained models will be available online at https://github.com/ShizhenChang/Chg2Cap.
Dsfer-Net: A Deep Supervision and Feature Retrieval Network for Bitemporal Change Detection Using Modern Hopfield Networks
Apr 03, 2023

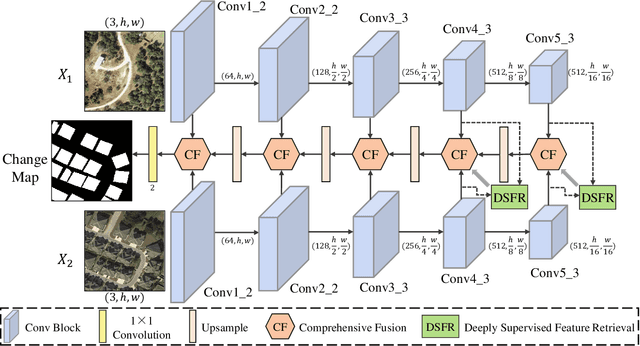

Change detection, as an important application for high-resolution remote sensing images, aims to monitor and analyze changes in the land surface over time. With the rapid growth in the quantity of high-resolution remote sensing data and the complexity of texture features, a number of quantitative deep learning-based methods have been proposed. Although these methods outperform traditional change detection methods by extracting deep features and combining spatial-temporal information, reasonable explanations about how deep features work on improving the detection performance are still lacking. In our investigations, we find that modern Hopfield network layers achieve considerable performance in semantic understandings. In this paper, we propose a Deep Supervision and FEature Retrieval network (Dsfer-Net) for bitemporal change detection. Specifically, the highly representative deep features of bitemporal images are jointly extracted through a fully convolutional Siamese network. Based on the sequential geo-information of the bitemporal images, we then design a feature retrieval module to retrieve the difference feature and leverage discriminative information in a deeply supervised manner. We also note that the deeply supervised feature retrieval module gives explainable proofs about the semantic understandings of the proposed network in its deep layers. Finally, this end-to-end network achieves a novel framework by aggregating the retrieved features and feature pairs from different layers. Experiments conducted on three public datasets (LEVIR-CD, WHU-CD, and CDD) confirm the superiority of the proposed Dsfer-Net over other state-of-the-art methods. Code will be available online (https://github.com/ShizhenChang/Dsfer-Net).
AI Security for Geoscience and Remote Sensing: Challenges and Future Trends
Dec 19, 2022Recent advances in artificial intelligence (AI) have significantly intensified research in the geoscience and remote sensing (RS) field. AI algorithms, especially deep learning-based ones, have been developed and applied widely to RS data analysis. The successful application of AI covers almost all aspects of Earth observation (EO) missions, from low-level vision tasks like super-resolution, denoising, and inpainting, to high-level vision tasks like scene classification, object detection, and semantic segmentation. While AI techniques enable researchers to observe and understand the Earth more accurately, the vulnerability and uncertainty of AI models deserve further attention, considering that many geoscience and RS tasks are highly safety-critical. This paper reviews the current development of AI security in the geoscience and RS field, covering the following five important aspects: adversarial attack, backdoor attack, federated learning, uncertainty, and explainability. Moreover, the potential opportunities and trends are discussed to provide insights for future research. To the best of the authors' knowledge, this paper is the first attempt to provide a systematic review of AI security-related research in the geoscience and RS community. Available code and datasets are also listed in the paper to move this vibrant field of research forward.
Sketched Multi-view Subspace Learning for Hyperspectral Anomalous Change Detection
Oct 09, 2022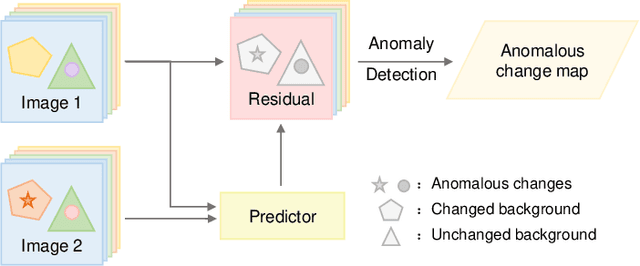
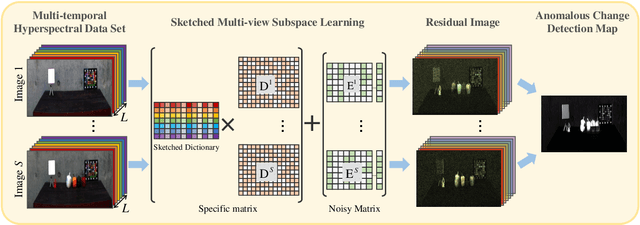
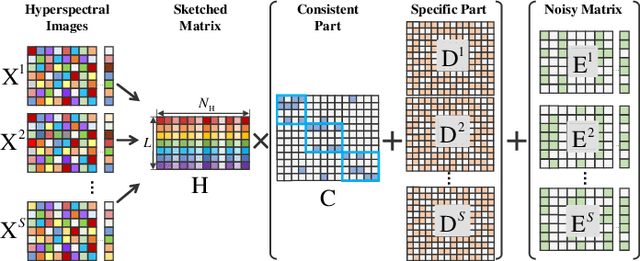

In recent years, multi-view subspace learning has been garnering increasing attention. It aims to capture the inner relationships of the data that are collected from multiple sources by learning a unified representation. In this way, comprehensive information from multiple views is shared and preserved for the generalization processes. As a special branch of temporal series hyperspectral image (HSI) processing, the anomalous change detection task focuses on detecting very small changes among different temporal images. However, when the volume of datasets is very large or the classes are relatively comprehensive, existing methods may fail to find those changes between the scenes, and end up with terrible detection results. In this paper, inspired by the sketched representation and multi-view subspace learning, a sketched multi-view subspace learning (SMSL) model is proposed for HSI anomalous change detection. The proposed model preserves major information from the image pairs and improves computational complexity by using a sketched representation matrix. Furthermore, the differences between scenes are extracted by utilizing the specific regularizer of the self-representation matrices. To evaluate the detection effectiveness of the proposed SMSL model, experiments are conducted on a benchmark hyperspectral remote sensing dataset and a natural hyperspectral dataset, and compared with other state-of-the art approaches.
Nonnegative-Constrained Joint Collaborative Representation with Union Dictionary for Hyperspectral Anomaly Detection
Mar 18, 2022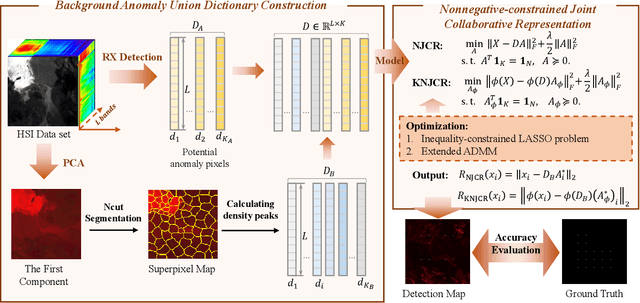
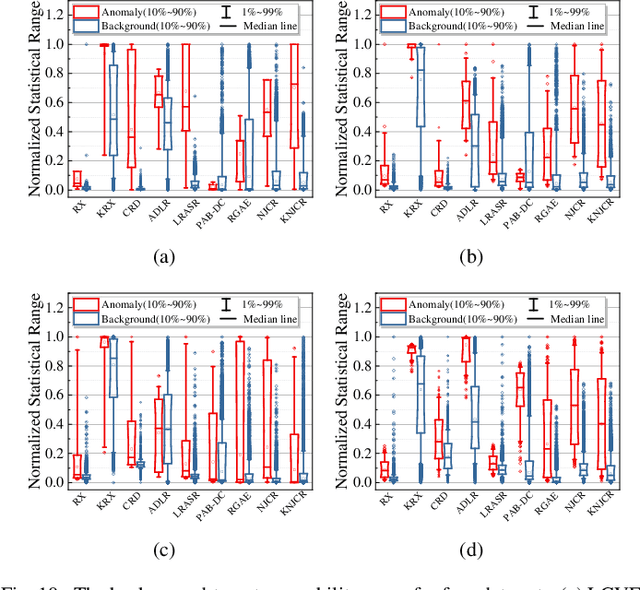
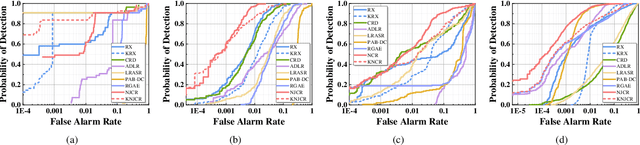
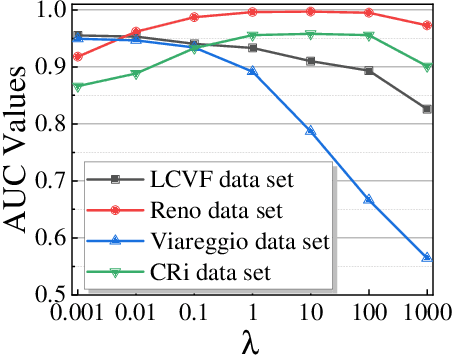
Recently, many collaborative representation-based (CR) algorithms have been proposed for hyperspectral anomaly detection. CR-based detectors approximate the image by a linear combination of background dictionaries and the coefficient matrix, and derive the detection map by utilizing recovery residuals. However, these CR-based detectors are often established on the premise of precise background features and strong image representation, which are very difficult to obtain. In addition, pursuing the coefficient matrix reinforced by the general $l_2$-min is very time consuming. To address these issues, a nonnegative-constrained joint collaborative representation model is proposed in this paper for the hyperspectral anomaly detection task. To extract reliable samples, a union dictionary consisting of background and anomaly sub-dictionaries is designed, where the background sub-dictionary is obtained at the superpixel level and the anomaly sub-dictionary is extracted by the pre-detection process. And the coefficient matrix is jointly optimized by the Frobenius norm regularization with a nonnegative constraint and a sum-to-one constraint. After the optimization process, the abnormal information is finally derived by calculating the residuals that exclude the assumed background information. To conduct comparable experiments, the proposed nonnegative-constrained joint collaborative representation (NJCR) model and its kernel version (KNJCR) are tested in four HSI data sets and achieve superior results compared with other state-of-the-art detectors.