 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChangeMinds: Multi-task Framework for Detecting and Describing Changes in Remote Sensing
Oct 15, 2024



Recent advancements in Remote Sensing (RS) for Change Detection (CD) and Change Captioning (CC) have seen substantial success by adopting deep learning techniques. Despite these advances, existing methods often handle CD and CC tasks independently, leading to inefficiencies from the absence of synergistic processing. In this paper, we present ChangeMinds, a novel unified multi-task framework that concurrently optimizes CD and CC processes within a single, end-to-end model. We propose the change-aware long short-term memory module (ChangeLSTM) to effectively capture complex spatiotemporal dynamics from extracted bi-temporal deep features, enabling the generation of universal change-aware representations that effectively serve both CC and CD tasks. Furthermore, we introduce a multi-task predictor with a cross-attention mechanism that enhances the interaction between image and text features, promoting efficient simultaneous learning and processing for both tasks. Extensive evaluations on the LEVIR-MCI dataset, alongside other standard benchmarks, show that ChangeMinds surpasses existing methods in multi-task learning settings and markedly improves performance in individual CD and CC tasks. Codes and pre-trained models will be available online.
xLSTM: Extended Long Short-Term Memory
May 07, 2024



In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they constituted the first Large Language Models (LLMs). However, the advent of the Transformer technology with parallelizable self-attention at its core marked the dawn of a new era, outpacing LSTMs at scale. We now raise a simple question: How far do we get in language modeling when scaling LSTMs to billions of parameters, leveraging the latest techniques from modern LLMs, but mitigating known limitations of LSTMs? Firstly, we introduce exponential gating with appropriate normalization and stabilization techniques. Secondly, we modify the LSTM memory structure, obtaining: (i) sLSTM with a scalar memory, a scalar update, and new memory mixing, (ii) mLSTM that is fully parallelizable with a matrix memory and a covariance update rule. Integrating these LSTM extensions into residual block backbones yields xLSTM blocks that are then residually stacked into xLSTM architectures. Exponential gating and modified memory structures boost xLSTM capabilities to perform favorably when compared to state-of-the-art Transformers and State Space Models, both in performance and scaling.
The impact of the AI revolution on asset management
Apr 24, 2023
Recent progress in deep learning, a special form of machine learning, has led to remarkable capabilities machines can now be endowed with: they can read and understand free flowing text, reason and bargain with human counterparts, translate texts between languages, learn how to take decisions to maximize certain outcomes, etc. Today, machines have revolutionized the detection of cancer, the prediction of protein structures, the design of drugs, the control of nuclear fusion reactors etc. Although these capabilities are still in their infancy, it seems clear that their continued refinement and application will result in a technological impact on nearly all social and economic areas of human activity, the likes of which we have not seen before. In this article, I will share my view as to how AI will likely impact asset management in general and I will provide a mental framework that will equip readers with a simple criterion to assess whether and to what degree a given fund really exploits deep learning and whether a large disruption risk from deep learning exist.
Dsfer-Net: A Deep Supervision and Feature Retrieval Network for Bitemporal Change Detection Using Modern Hopfield Networks
Apr 03, 2023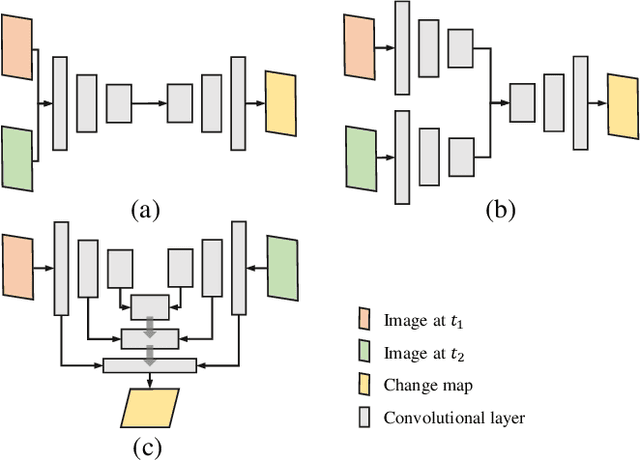

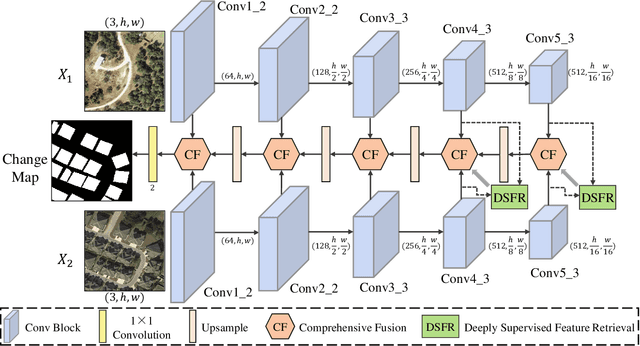

Change detection, as an important application for high-resolution remote sensing images, aims to monitor and analyze changes in the land surface over time. With the rapid growth in the quantity of high-resolution remote sensing data and the complexity of texture features, a number of quantitative deep learning-based methods have been proposed. Although these methods outperform traditional change detection methods by extracting deep features and combining spatial-temporal information, reasonable explanations about how deep features work on improving the detection performance are still lacking. In our investigations, we find that modern Hopfield network layers achieve considerable performance in semantic understandings. In this paper, we propose a Deep Supervision and FEature Retrieval network (Dsfer-Net) for bitemporal change detection. Specifically, the highly representative deep features of bitemporal images are jointly extracted through a fully convolutional Siamese network. Based on the sequential geo-information of the bitemporal images, we then design a feature retrieval module to retrieve the difference feature and leverage discriminative information in a deeply supervised manner. We also note that the deeply supervised feature retrieval module gives explainable proofs about the semantic understandings of the proposed network in its deep layers. Finally, this end-to-end network achieves a novel framework by aggregating the retrieved features and feature pairs from different layers. Experiments conducted on three public datasets (LEVIR-CD, WHU-CD, and CDD) confirm the superiority of the proposed Dsfer-Net over other state-of-the-art methods. Code will be available online (https://github.com/ShizhenChang/Dsfer-Net).
Traffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023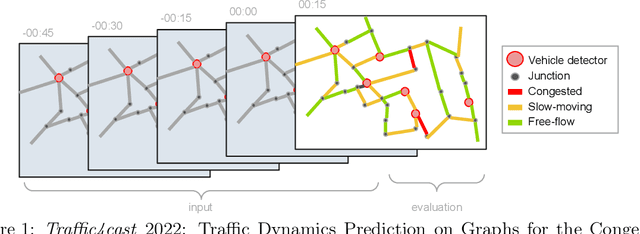
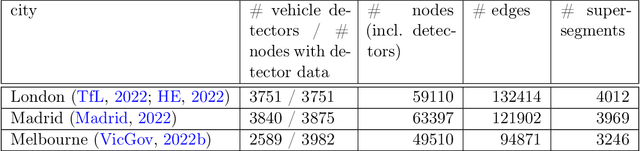
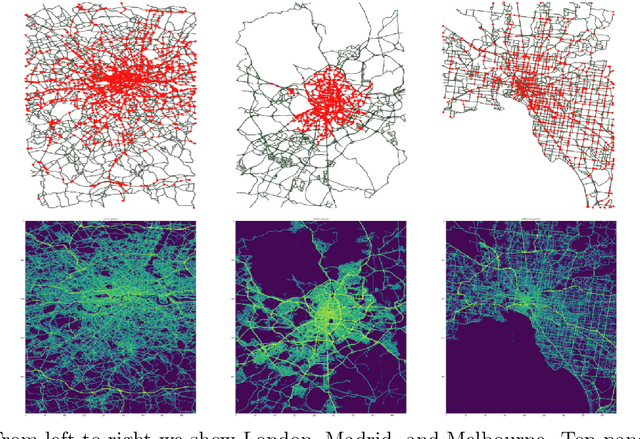
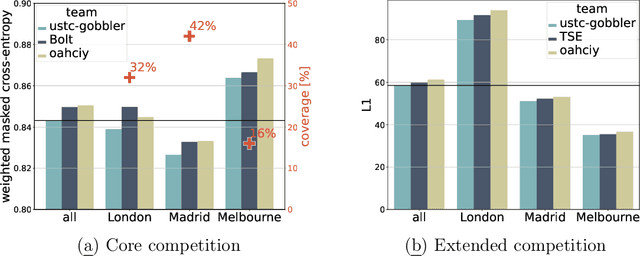
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
Metropolitan Segment Traffic Speeds from Massive Floating Car Data in 10 Cities
Feb 17, 2023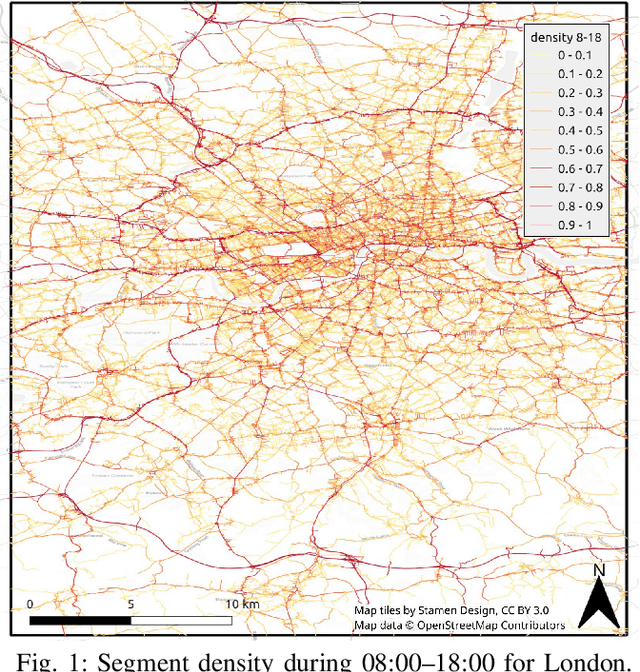
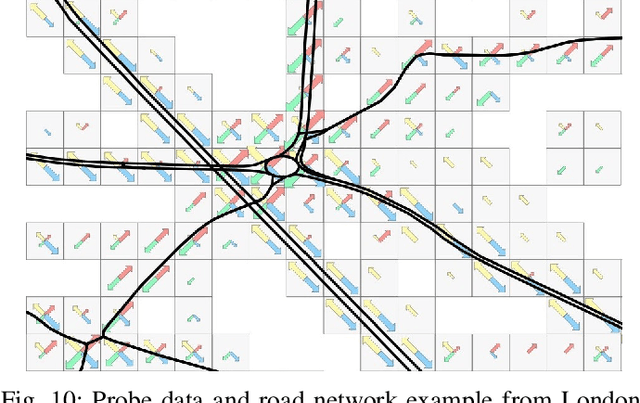
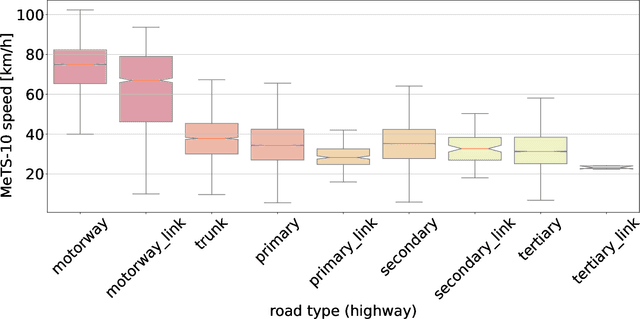
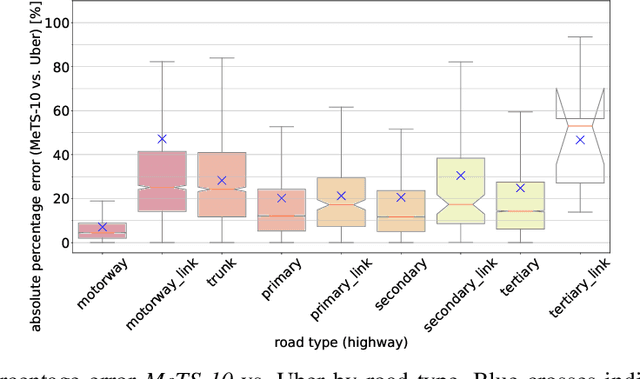
Traffic analysis is crucial for urban operations and planning, while the availability of dense urban traffic data beyond loop detectors is still scarce. We present a large-scale floating vehicle dataset of per-street segment traffic information, Metropolitan Segment Traffic Speeds from Massive Floating Car Data in 10 Cities (MeTS-10), available for 10 global cities with a 15-minute resolution for collection periods ranging between 108 and 361 days in 2019-2021 and covering more than 1500 square kilometers per metropolitan area. MeTS-10 features traffic speed information at all street levels from main arterials to local streets for Antwerp, Bangkok, Barcelona, Berlin, Chicago, Istanbul, London, Madrid, Melbourne and Moscow. The dataset leverages the industrial-scale floating vehicle Traffic4cast data with speeds and vehicle counts provided in a privacy-preserving spatio-temporal aggregation. We detail the efficient matching approach mapping the data to the OpenStreetMap road graph. We evaluate the dataset by comparing it with publicly available stationary vehicle detector data (for Berlin, London, and Madrid) and the Uber traffic speed dataset (for Barcelona, Berlin, and London). The comparison highlights the differences across datasets in spatio-temporal coverage and variations in the reported traffic caused by the binning method. MeTS-10 enables novel, city-wide analysis of mobility and traffic patterns for ten major world cities, overcoming current limitations of spatially sparse vehicle detector data. The large spatial and temporal coverage offers an opportunity for joining the MeTS-10 with other datasets, such as traffic surveys in traffic planning studies or vehicle detector data in traffic control settings.
Profiling and Improving the PyTorch Dataloader for high-latency Storage: A Technical Report
Nov 09, 2022
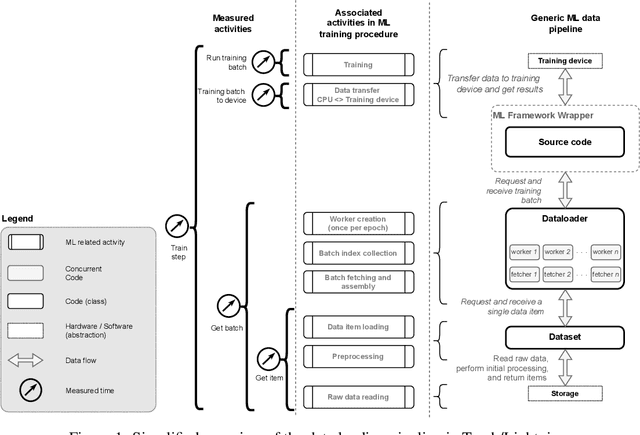


A growing number of Machine Learning Frameworks recently made Deep Learning accessible to a wider audience of engineers, scientists, and practitioners, by allowing straightforward use of complex neural network architectures and algorithms. However, since deep learning is rapidly evolving, not only through theoretical advancements but also with respect to hardware and software engineering, ML frameworks often lose backward compatibility and introduce technical debt that can lead to bottlenecks and sub-optimal resource utilization. Moreover, the focus is in most cases not on deep learning engineering, but rather on new models and theoretical advancements. In this work, however, we focus on engineering, more specifically on the data loading pipeline in the PyTorch Framework. We designed a series of benchmarks that outline performance issues of certain steps in the data loading process. Our findings show that for classification tasks that involve loading many files, like images, the training wall-time can be significantly improved. With our new, modified ConcurrentDataloader we can reach improvements in GPU utilization and significantly reduce batch loading time, up to 12X. This allows for the use of the cloud-based, S3-like object storage for datasets, and have comparable training time as if datasets are stored on local drives.
Sketched Multi-view Subspace Learning for Hyperspectral Anomalous Change Detection
Oct 09, 2022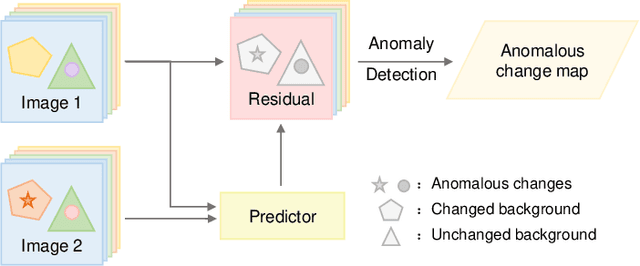
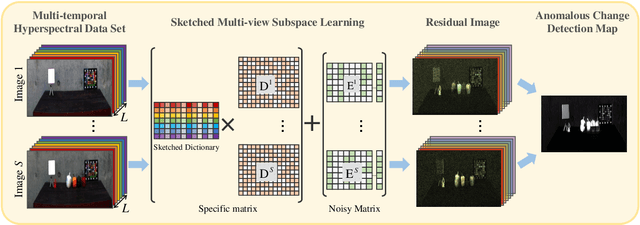
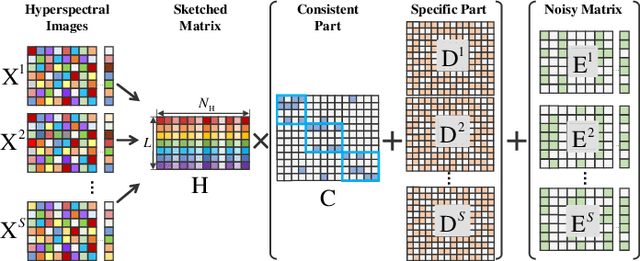

In recent years, multi-view subspace learning has been garnering increasing attention. It aims to capture the inner relationships of the data that are collected from multiple sources by learning a unified representation. In this way, comprehensive information from multiple views is shared and preserved for the generalization processes. As a special branch of temporal series hyperspectral image (HSI) processing, the anomalous change detection task focuses on detecting very small changes among different temporal images. However, when the volume of datasets is very large or the classes are relatively comprehensive, existing methods may fail to find those changes between the scenes, and end up with terrible detection results. In this paper, inspired by the sketched representation and multi-view subspace learning, a sketched multi-view subspace learning (SMSL) model is proposed for HSI anomalous change detection. The proposed model preserves major information from the image pairs and improves computational complexity by using a sketched representation matrix. Furthermore, the differences between scenes are extracted by utilizing the specific regularizer of the self-representation matrices. To evaluate the detection effectiveness of the proposed SMSL model, experiments are conducted on a benchmark hyperspectral remote sensing dataset and a natural hyperspectral dataset, and compared with other state-of-the art approaches.
Predicting the Future of AI with AI: High-quality link prediction in an exponentially growing knowledge network
Sep 23, 2022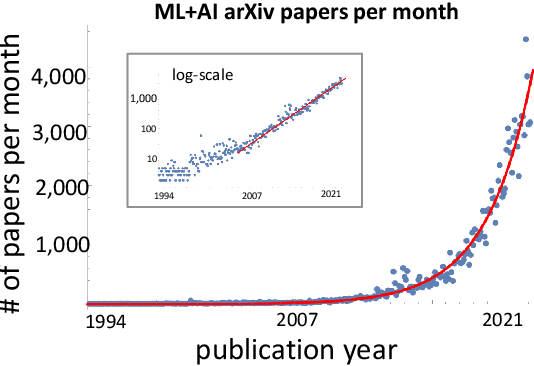
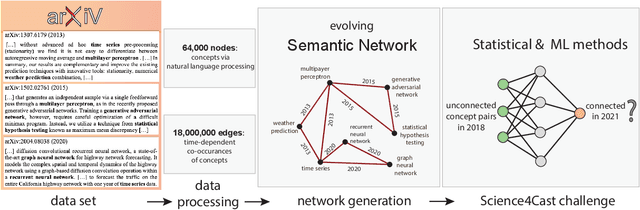
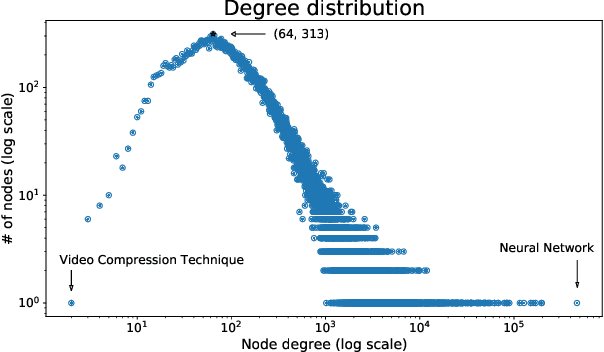
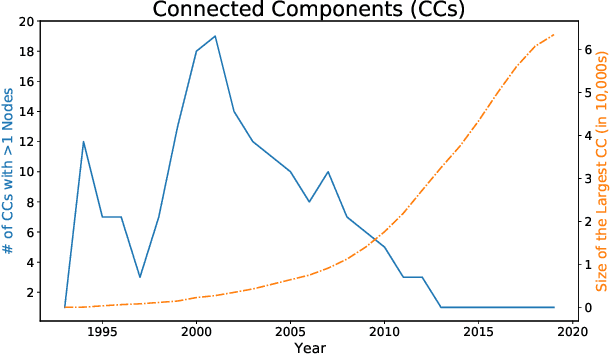
A tool that could suggest new personalized research directions and ideas by taking insights from the scientific literature could significantly accelerate the progress of science. A field that might benefit from such an approach is artificial intelligence (AI) research, where the number of scientific publications has been growing exponentially over the last years, making it challenging for human researchers to keep track of the progress. Here, we use AI techniques to predict the future research directions of AI itself. We develop a new graph-based benchmark based on real-world data -- the Science4Cast benchmark, which aims to predict the future state of an evolving semantic network of AI. For that, we use more than 100,000 research papers and build up a knowledge network with more than 64,000 concept nodes. We then present ten diverse methods to tackle this task, ranging from pure statistical to pure learning methods. Surprisingly, the most powerful methods use a carefully curated set of network features, rather than an end-to-end AI approach. It indicates a great potential that can be unleashed for purely ML approaches without human knowledge. Ultimately, better predictions of new future research directions will be a crucial component of more advanced research suggestion tools.
Txt2Img-MHN: Remote Sensing Image Generation from Text Using Modern Hopfield Networks
Aug 08, 2022
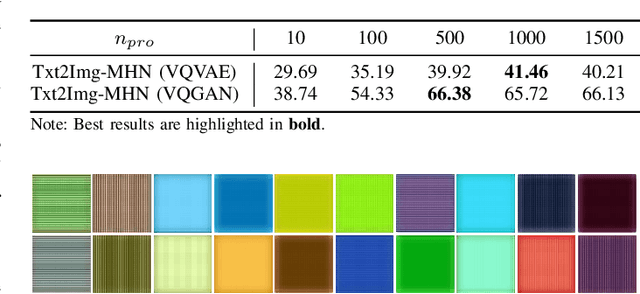
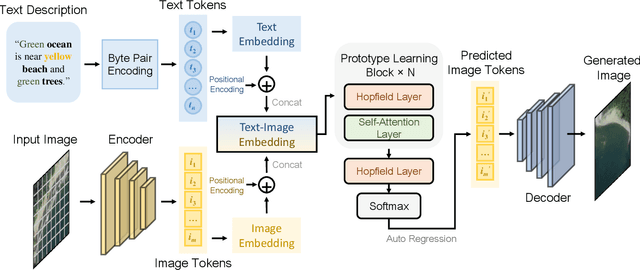
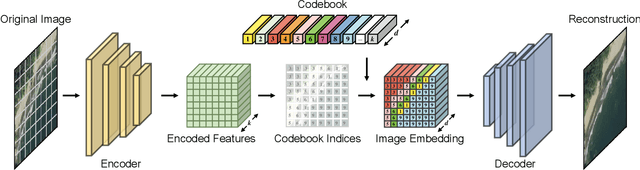
The synthesis of high-resolution remote sensing images based on text descriptions has great potential in many practical application scenarios. Although deep neural networks have achieved great success in many important remote sensing tasks, generating realistic remote sensing images from text descriptions is still very difficult. To address this challenge, we propose a novel text-to-image modern Hopfield network (Txt2Img-MHN). The main idea of Txt2Img-MHN is to conduct hierarchical prototype learning on both text and image embeddings with modern Hopfield layers. Instead of directly learning concrete but highly diverse text-image joint feature representations for different semantics, Txt2Img-MHN aims to learn the most representative prototypes from text-image embeddings, achieving a coarse-to-fine learning strategy. These learned prototypes can then be utilized to represent more complex semantics in the text-to-image generation task. To better evaluate the realism and semantic consistency of the generated images, we further conduct zero-shot classification on real remote sensing data using the classification model trained on synthesized images. Despite its simplicity, we find that the overall accuracy in the zero-shot classification may serve as a good metric to evaluate the ability to generate an image from text. Extensive experiments on the benchmark remote sensing text-image dataset demonstrate that the proposed Txt2Img-MHN can generate more realistic remote sensing images than existing methods. Code and pre-trained models are available online (https://github.com/YonghaoXu/Txt2Img-MHN).