 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiling and Improving the PyTorch Dataloader for high-latency Storage: A Technical Report
Paper and Code

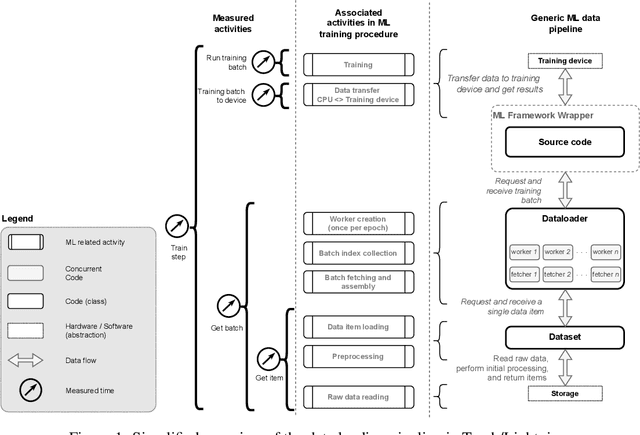


A growing number of Machine Learning Frameworks recently made Deep Learning accessible to a wider audience of engineers, scientists, and practitioners, by allowing straightforward use of complex neural network architectures and algorithms. However, since deep learning is rapidly evolving, not only through theoretical advancements but also with respect to hardware and software engineering, ML frameworks often lose backward compatibility and introduce technical debt that can lead to bottlenecks and sub-optimal resource utilization. Moreover, the focus is in most cases not on deep learning engineering, but rather on new models and theoretical advancements. In this work, however, we focus on engineering, more specifically on the data loading pipeline in the PyTorch Framework. We designed a series of benchmarks that outline performance issues of certain steps in the data loading process. Our findings show that for classification tasks that involve loading many files, like images, the training wall-time can be significantly improved. With our new, modified ConcurrentDataloader we can reach improvements in GPU utilization and significantly reduce batch loading time, up to 12X. This allows for the use of the cloud-based, S3-like object storage for datasets, and have comparable training time as if datasets are stored on local drives.