 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Distillation to Hybrid xLSTM Architectures
Mar 16, 2026There have been numerous attempts to distill quadratic attention-based large language models (LLMs) into sub-quadratic linearized architectures. However, despite extensive research, such distilled models often fail to match the performance of their teacher LLMs on various downstream tasks. We set out the goal of lossless distillation, which we define in terms of tolerance-corrected Win-and-Tie rates between student and teacher on sets of tasks. To this end, we introduce an effective distillation pipeline for xLSTM-based students. We propose an additional merging stage, where individually linearized experts are combined into a single model. We show the effectiveness of this pipeline by distilling base and instruction-tuned models from the Llama, Qwen, and Olmo families. In many settings, our xLSTM-based students recover most of the teacher's performance, and even exceed it on some downstream tasks. Our contributions are an important step towards more energy-efficient and cost-effective replacements for transformer-based LLMs.
Towards a Neural Debugger for Python
Mar 10, 2026Training large language models (LLMs) on Python execution traces grounds them in code execution and enables the line-by-line execution prediction of whole Python programs, effectively turning them into neural interpreters (FAIR CodeGen Team et al., 2025). However, developers rarely execute programs step by step; instead, they use debuggers to stop execution at certain breakpoints and step through relevant portions only while inspecting or modifying program variables. Existing neural interpreter approaches lack such interactive control. To address this limitation, we introduce neural debuggers: language models that emulate traditional debuggers, supporting operations such as stepping into, over, or out of functions, as well as setting breakpoints at specific source lines. We show that neural debuggers -- obtained via fine-tuning large LLMs or pre-training smaller models from scratch -- can reliably model both forward execution (predicting future states and outputs) and inverse execution (inferring prior states or inputs) conditioned on debugger actions. Evaluated on CruxEval, our models achieve strong performance on both output and input prediction tasks, demonstrating robust conditional execution modeling. Our work takes first steps towards future agentic coding systems in which neural debuggers serve as a world model for simulated debugging environments, providing execution feedback or enabling agents to interact with real debugging tools. This capability lays the foundation for more powerful code generation, program understanding, and automated debugging.
PointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Oct 23, 2025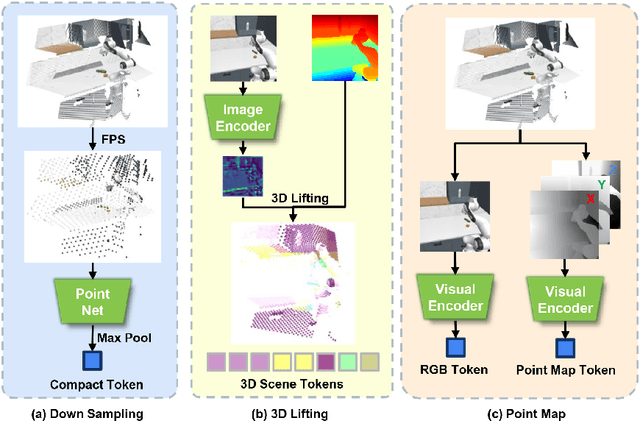
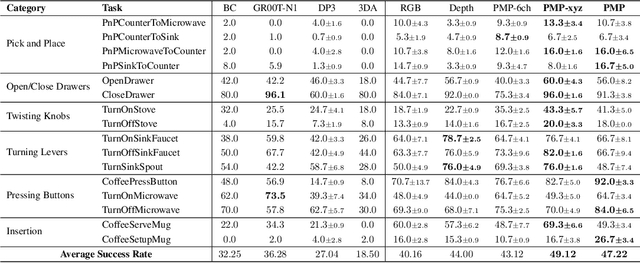
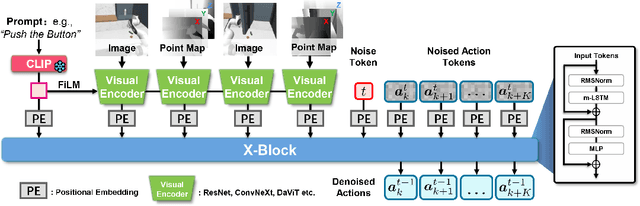
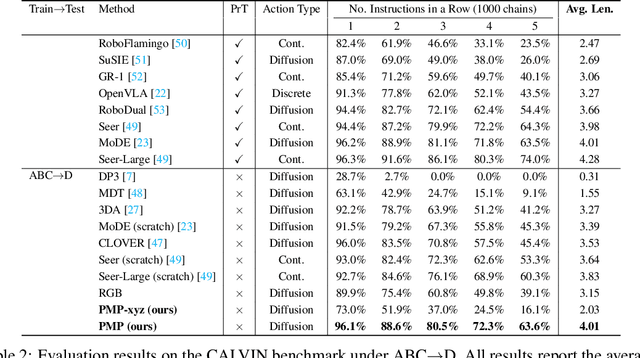
Robotic manipulation systems benefit from complementary sensing modalities, where each provides unique environmental information. Point clouds capture detailed geometric structure, while RGB images provide rich semantic context. Current point cloud methods struggle to capture fine-grained detail, especially for complex tasks, which RGB methods lack geometric awareness, which hinders their precision and generalization. We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling. The resulting data type makes it easier to extract shape and spatial relationships from observations, and can be transformed between reference frames. Yet due to their structure in a regular grid, we enable the use of established computer vision techniques directly to 3D data. Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception. Through extensive experiments on the RoboCasa and CALVIN benchmarks and real robot evaluations, we demonstrate that our method achieves state-of-the-art performance across diverse manipulation tasks. The overview and demos are available on our project page: https://point-map.github.io/Point-Map/
xLSTM Scaling Laws: Competitive Performance with Linear Time-Complexity
Oct 02, 2025Scaling laws play a central role in the success of Large Language Models (LLMs), enabling the prediction of model performance relative to compute budgets prior to training. While Transformers have been the dominant architecture, recent alternatives such as xLSTM offer linear complexity with respect to context length while remaining competitive in the billion-parameter regime. We conduct a comparative investigation on the scaling behavior of Transformers and xLSTM along the following lines, providing insights to guide future model design and deployment. First, we study the scaling behavior for xLSTM in compute-optimal and over-training regimes using both IsoFLOP and parametric fit approaches on a wide range of model sizes (80M-7B) and number of training tokens (2B-2T). Second, we examine the dependence of optimal model sizes on context length, a pivotal aspect that was largely ignored in previous work. Finally, we analyze inference-time scaling characteristics. Our findings reveal that in typical LLM training and inference scenarios, xLSTM scales favorably compared to Transformers. Importantly, xLSTM's advantage widens as training and inference contexts grow.
Tiled Flash Linear Attention: More Efficient Linear RNN and xLSTM Kernels
Mar 18, 2025Linear RNNs with gating recently demonstrated competitive performance compared to Transformers in language modeling. Although their linear compute scaling in sequence length offers theoretical runtime advantages over Transformers, realizing these benefits in practice requires optimized custom kernels, as Transformers rely on the highly efficient Flash Attention kernels. Leveraging the chunkwise-parallel formulation of linear RNNs, Flash Linear Attention (FLA) shows that linear RNN kernels are faster than Flash Attention, by parallelizing over chunks of the input sequence. However, since the chunk size of FLA is limited, many intermediate states must be materialized in GPU memory. This leads to low arithmetic intensity and causes high memory consumption and IO cost, especially for long-context pre-training. In this work, we present Tiled Flash Linear Attention (TFLA), a novel kernel algorithm for linear RNNs, that enables arbitrary large chunk sizes by introducing an additional level of sequence parallelization within each chunk. First, we apply TFLA to the xLSTM with matrix memory, the mLSTM. Second, we propose an mLSTM variant with sigmoid input gate and reduced computation for even faster kernel runtimes at equal language modeling performance. In our speed benchmarks, we show that our new mLSTM kernels based on TFLA outperform highly optimized Flash Attention, Linear Attention and Mamba kernels, setting a new state of the art for efficient long-context sequence modeling primitives.
xLSTM 7B: A Recurrent LLM for Fast and Efficient Inference
Mar 17, 2025Recent breakthroughs in solving reasoning, math and coding problems with Large Language Models (LLMs) have been enabled by investing substantial computation budgets at inference time. Therefore, inference speed is one of the most critical properties of LLM architectures, and there is a growing need for LLMs that are efficient and fast at inference. Recently, LLMs built on the xLSTM architecture have emerged as a powerful alternative to Transformers, offering linear compute scaling with sequence length and constant memory usage, both highly desirable properties for efficient inference. However, such xLSTM-based LLMs have yet to be scaled to larger models and assessed and compared with respect to inference speed and efficiency. In this work, we introduce xLSTM 7B, a 7-billion-parameter LLM that combines xLSTM's architectural benefits with targeted optimizations for fast and efficient inference. Our experiments demonstrate that xLSTM 7B achieves performance on downstream tasks comparable to other similar-sized LLMs, while providing significantly faster inference speeds and greater efficiency compared to Llama- and Mamba-based LLMs. These results establish xLSTM 7B as the fastest and most efficient 7B LLM, offering a solution for tasks that require large amounts of test-time computation. Our work highlights xLSTM's potential as a foundational architecture for methods building on heavy use of LLM inference. Our model weights, model code and training code are open-source.
FlashRNN: Optimizing Traditional RNNs on Modern Hardware
Dec 10, 2024



While Transformers and other sequence-parallelizable neural network architectures seem like the current state of the art in sequence modeling, they specifically lack state-tracking capabilities. These are important for time-series tasks and logical reasoning. Traditional RNNs like LSTMs and GRUs, as well as modern variants like sLSTM do have these capabilities at the cost of strictly sequential processing. While this is often seen as a strong limitation, we show how fast these networks can get with our hardware-optimization FlashRNN in Triton and CUDA, optimizing kernels to the register level on modern GPUs. We extend traditional RNNs with a parallelization variant that processes multiple RNNs of smaller hidden state in parallel, similar to the head-wise processing in Transformers. To enable flexibility on different GPU variants, we introduce a new optimization framework for hardware-internal cache sizes, memory and compute handling. It models the hardware in a setting using polyhedral-like constraints, including the notion of divisibility. This speeds up the solution process in our ConstrINT library for general integer constraint satisfaction problems (integer CSPs). We show that our kernels can achieve 50x speed-ups over a vanilla PyTorch implementation and allow 40x larger hidden sizes compared to our Triton implementation. Our open-source kernels and the optimization library are released here to boost research in the direction of state-tracking enabled RNNs and sequence modeling: \url{https://github.com/NX-AI/flashrnn}
A Large Recurrent Action Model: xLSTM enables Fast Inference for Robotics Tasks
Oct 29, 2024In recent years, there has been a trend in the field of Reinforcement Learning (RL) towards large action models trained offline on large-scale datasets via sequence modeling. Existing models are primarily based on the Transformer architecture, which result in powerful agents. However, due to slow inference times, Transformer-based approaches are impractical for real-time applications, such as robotics. Recently, modern recurrent architectures, such as xLSTM and Mamba, have been proposed that exhibit parallelization benefits during training similar to the Transformer architecture while offering fast inference. In this work, we study the aptitude of these modern recurrent architectures for large action models. Consequently, we propose a Large Recurrent Action Model (LRAM) with an xLSTM at its core that comes with linear-time inference complexity and natural sequence length extrapolation abilities. Experiments on 432 tasks from 6 domains show that LRAM compares favorably to Transformers in terms of performance and speed.
Vision-LSTM: xLSTM as Generic Vision Backbone
Jun 06, 2024Transformers are widely used as generic backbones in computer vision, despite initially introduced for natural language processing. Recently, the Long Short-Term Memory (LSTM) has been extended to a scalable and performant architecture - the xLSTM - which overcomes long-standing LSTM limitations via exponential gating and parallelizable matrix memory structure. In this report, we introduce Vision-LSTM (ViL), an adaption of the xLSTM building blocks to computer vision. ViL comprises a stack of xLSTM blocks where odd blocks process the sequence of patch tokens from top to bottom while even blocks go from bottom to top. Experiments show that ViL holds promise to be further deployed as new generic backbone for computer vision architectures.
xLSTM: Extended Long Short-Term Memory
May 07, 2024



In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM). Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they constituted the first Large Language Models (LLMs). However, the advent of the Transformer technology with parallelizable self-attention at its core marked the dawn of a new era, outpacing LSTMs at scale. We now raise a simple question: How far do we get in language modeling when scaling LSTMs to billions of parameters, leveraging the latest techniques from modern LLMs, but mitigating known limitations of LSTMs? Firstly, we introduce exponential gating with appropriate normalization and stabilization techniques. Secondly, we modify the LSTM memory structure, obtaining: (i) sLSTM with a scalar memory, a scalar update, and new memory mixing, (ii) mLSTM that is fully parallelizable with a matrix memory and a covariance update rule. Integrating these LSTM extensions into residual block backbones yields xLSTM blocks that are then residually stacked into xLSTM architectures. Exponential gating and modified memory structures boost xLSTM capabilities to perform favorably when compared to state-of-the-art Transformers and State Space Models, both in performance and scaling.