 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive deep learning for real-time simulation of soft tissue dynamics during virtual neurosurgery
Jan 20, 2026Accurate simulation of brain deformation is a key component for developing realistic, interactive neurosurgical simulators, as complex nonlinear deformations must be captured to ensure realistic tool-tissue interactions. However, traditional numerical solvers often fall short in meeting real-time performance requirements. To overcome this, we introduce a deep learning-based surrogate model that efficiently simulates transient brain deformation caused by continuous interactions between surgical instruments and the virtual brain geometry. Building on Universal Physics Transformers, our approach operates directly on large-scale mesh data and is trained on an extensive dataset generated from nonlinear finite element simulations, covering a broad spectrum of temporal instrument-tissue interaction scenarios. To reduce the accumulation of errors in autoregressive inference, we propose a stochastic teacher forcing strategy applied during model training. Specifically, training consists of short stochastic rollouts in which the proportion of ground truth inputs is gradually decreased in favor of model-generated predictions. Our results show that the proposed surrogate model achieves accurate and efficient predictions across a range of transient brain deformation scenarios, scaling to meshes with up to 150,000 nodes. The introduced stochastic teacher forcing technique substantially improves long-term rollout stability, reducing the maximum prediction error from 6.7 mm to 3.5 mm. We further integrate the trained surrogate model into an interactive neurosurgical simulation environment, achieving runtimes below 10 ms per simulation step on consumer-grade inference hardware. Our proposed deep learning framework enables rapid, smooth and accurate biomechanical simulations of dynamic brain tissue deformation, laying the foundation for realistic surgical training environments.
NeuralDEM -- Real-time Simulation of Industrial Particulate Flows
Nov 14, 2024Advancements in computing power have made it possible to numerically simulate large-scale fluid-mechanical and/or particulate systems, many of which are integral to core industrial processes. Among the different numerical methods available, the discrete element method (DEM) provides one of the most accurate representations of a wide range of physical systems involving granular and discontinuous materials. Consequently, DEM has become a widely accepted approach for tackling engineering problems connected to granular flows and powder mechanics. Additionally, DEM can be integrated with grid-based computational fluid dynamics (CFD) methods, enabling the simulation of chemical processes taking place, e.g., in fluidized beds. However, DEM is computationally intensive because of the intrinsic multiscale nature of particulate systems, restricting simulation duration or number of particles. Towards this end, NeuralDEM presents an end-to-end approach to replace slow numerical DEM routines with fast, adaptable deep learning surrogates. NeuralDEM is capable of picturing long-term transport processes across different regimes using macroscopic observables without any reference to microscopic model parameters. First, NeuralDEM treats the Lagrangian discretization of DEM as an underlying continuous field, while simultaneously modeling macroscopic behavior directly as additional auxiliary fields. Second, NeuralDEM introduces multi-branch neural operators scalable to real-time modeling of industrially-sized scenarios - from slow and pseudo-steady to fast and transient. Such scenarios have previously posed insurmountable challenges for deep learning models. Notably, NeuralDEM faithfully models coupled CFD-DEM fluidized bed reactors of 160k CFD cells and 500k DEM particles for trajectories of 28s. NeuralDEM will open many new doors to advanced engineering and much faster process cycles.
One Initialization to Rule them All: Fine-tuning via Explained Variance Adaptation
Oct 09, 2024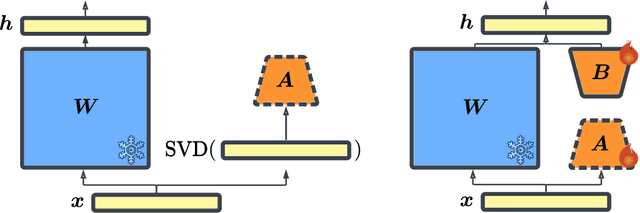
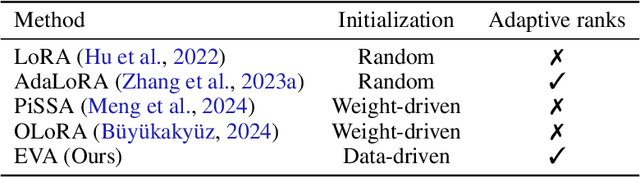
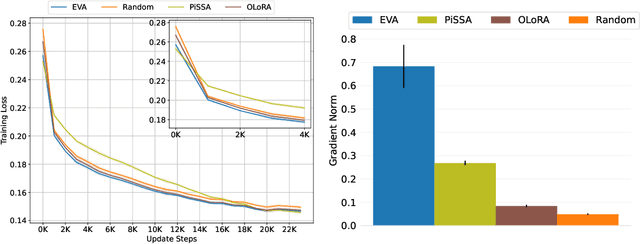
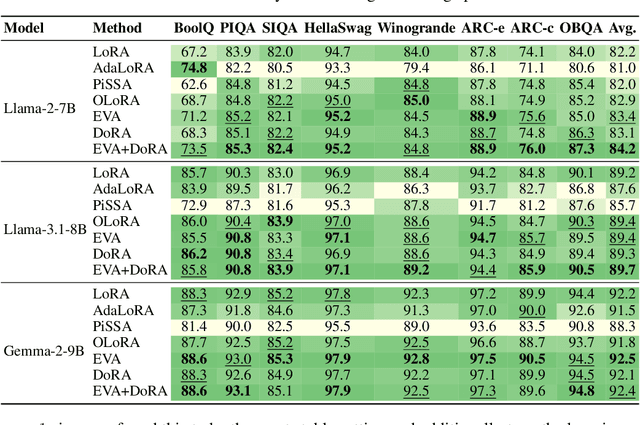
Foundation models (FMs) are pre-trained on large-scale datasets and then fine-tuned on a downstream task for a specific application. The most successful and most commonly used fine-tuning method is to update the pre-trained weights via a low-rank adaptation (LoRA). LoRA introduces new weight matrices that are usually initialized at random with a uniform rank distribution across model weights. Recent works focus on weight-driven initialization or learning of adaptive ranks during training. Both approaches have only been investigated in isolation, resulting in slow convergence or a uniform rank distribution, in turn leading to sub-optimal performance. We propose to enhance LoRA by initializing the new weights in a data-driven manner by computing singular value decomposition on minibatches of activation vectors. Then, we initialize the LoRA matrices with the obtained right-singular vectors and re-distribute ranks among all weight matrices to explain the maximal amount of variance and continue the standard LoRA fine-tuning procedure. This results in our new method Explained Variance Adaptation (EVA). We apply EVA to a variety of fine-tuning tasks ranging from language generation and understanding to image classification and reinforcement learning. EVA exhibits faster convergence than competitors and attains the highest average score across a multitude of tasks per domain.
Vision-LSTM: xLSTM as Generic Vision Backbone
Jun 06, 2024Transformers are widely used as generic backbones in computer vision, despite initially introduced for natural language processing. Recently, the Long Short-Term Memory (LSTM) has been extended to a scalable and performant architecture - the xLSTM - which overcomes long-standing LSTM limitations via exponential gating and parallelizable matrix memory structure. In this report, we introduce Vision-LSTM (ViL), an adaption of the xLSTM building blocks to computer vision. ViL comprises a stack of xLSTM blocks where odd blocks process the sequence of patch tokens from top to bottom while even blocks go from bottom to top. Experiments show that ViL holds promise to be further deployed as new generic backbone for computer vision architectures.
Universal Physics Transformers
Feb 19, 2024



Deep neural network based surrogates for partial differential equations have recently gained increased interest. However, akin to their numerical counterparts, different techniques are used across applications, even if the underlying dynamics of the systems are similar. A prominent example is the Lagrangian and Eulerian specification in computational fluid dynamics, posing a challenge for neural networks to effectively model particle- as opposed to grid-based dynamics. We introduce Universal Physics Transformers (UPTs), a novel learning paradigm which models a wide range of spatio-temporal problems - both for Lagrangian and Eulerian discretization schemes. UPTs operate without grid- or particle-based latent structures, enabling flexibility across meshes and particles. UPTs efficiently propagate dynamics in the latent space, emphasized by inverse encoding and decoding techniques. Finally, UPTs allow for queries of the latent space representation at any point in space-time. We demonstrate the efficacy of UPTs in mesh-based fluid simulations, steady-state Reynolds averaged Navier-Stokes simulations, and Lagrangian-based dynamics. Project page: https://ml-jku.github.io/UPT
MIM-Refiner: A Contrastive Learning Boost from Intermediate Pre-Trained Representations
Feb 15, 2024We introduce MIM (Masked Image Modeling)-Refiner, a contrastive learning boost for pre-trained MIM models. The motivation behind MIM-Refiner is rooted in the insight that optimal representations within MIM models generally reside in intermediate layers. Accordingly, MIM-Refiner leverages multiple contrastive heads that are connected to diverse intermediate layers. In each head, a modified nearest neighbor objective helps to construct respective semantic clusters. The refinement process is short but effective. Within a few epochs, we refine the features of MIM models from subpar to state-of-the-art, off-the-shelf features. Refining a ViT-H, pre-trained with data2vec 2.0 on ImageNet-1K, achieves new state-of-the-art results in linear probing (84.7%) and low-shot classification among models that are pre-trained on ImageNet-1K. In ImageNet-1K 1-shot classification, MIM-Refiner sets a new state-of-the-art of 64.2%, outperforming larger models that were trained on up to 2000x more data such as DINOv2-g, OpenCLIP-G and MAWS-6.5B. Project page: https://ml-jku.github.io/MIM-Refiner
Contrastive Tuning: A Little Help to Make Masked Autoencoders Forget
Apr 20, 2023



Masked Image Modeling (MIM) methods, like Masked Autoencoders (MAE), efficiently learn a rich representation of the input. However, for adapting to downstream tasks, they require a sufficient amount of labeled data since their rich features capture not only objects but also less relevant image background. In contrast, Instance Discrimination (ID) methods focus on objects. In this work, we study how to combine the efficiency and scalability of MIM with the ability of ID to perform downstream classification in the absence of large amounts of labeled data. To this end, we introduce Masked Autoencoder Contrastive Tuning (MAE-CT), a sequential approach that applies Nearest Neighbor Contrastive Learning (NNCLR) to a pre-trained MAE. MAE-CT tunes the rich features such that they form semantic clusters of objects without using any labels. Applied to large and huge Vision Transformer (ViT) models, MAE-CT matches or excels previous self-supervised methods trained on ImageNet in linear probing, k-NN and low-shot classification accuracy as well as in unsupervised clustering accuracy. Notably, similar results can be achieved without additional image augmentations. While ID methods generally rely on hand-crafted augmentations to avoid shortcut learning, we find that nearest neighbor lookup is sufficient and that this data-driven augmentation effect improves with model size. MAE-CT is compute efficient. For instance, starting from a MAE pre-trained ViT-L/16, MAE-CT increases the ImageNet 1% low-shot accuracy from 67.7% to 72.6%, linear probing accuracy from 76.0% to 80.2% and k-NN accuracy from 60.6% to 79.1% in just five hours using eight A100 GPUs.