 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWIND: Weather Inverse Diffusion for Zero-Shot Atmospheric Modeling
Feb 03, 2026Deep learning has revolutionized weather and climate modeling, yet the current landscape remains fragmented: highly specialized models are typically trained individually for distinct tasks. To unify this landscape, we introduce WIND, a single pre-trained foundation model capable of replacing specialized baselines across a vast array of tasks. Crucially, in contrast to previous atmospheric foundation models, we achieve this without any task-specific fine-tuning. To learn a robust, task-agnostic prior of the atmosphere, we pre-train WIND with a self-supervised video reconstruction objective, utilizing an unconditional video diffusion model to iteratively reconstruct atmospheric dynamics from a noisy state. At inference, we frame diverse domain-specific problems strictly as inverse problems and solve them via posterior sampling. This unified approach allows us to tackle highly relevant weather and climate problems, including probabilistic forecasting, spatial and temporal downscaling, sparse reconstruction and enforcing conservation laws purely with our pre-trained model. We further demonstrate the model's capacity to generate physically consistent counterfactual storylines of extreme weather events under global warming scenarios. By combining generative video modeling with inverse problem solving, WIND offers a computationally efficient paradigm shift in AI-based atmospheric modeling.
LaM-SLidE: Latent Space Modeling of Spatial Dynamical Systems via Linked Entities
Feb 17, 2025Generative models are spearheading recent progress in deep learning, showing strong promise for trajectory sampling in dynamical systems as well. However, while latent space modeling paradigms have transformed image and video generation, similar approaches are more difficult for most dynamical systems. Such systems -- from chemical molecule structures to collective human behavior -- are described by interactions of entities, making them inherently linked to connectivity patterns and the traceability of entities over time. Our approach, LaM-SLidE (Latent Space Modeling of Spatial Dynamical Systems via Linked Entities), combines the advantages of graph neural networks, i.e., the traceability of entities across time-steps, with the efficiency and scalability of recent advances in image and video generation, where pre-trained encoder and decoder are frozen to enable generative modeling in the latent space. The core idea of LaM-SLidE is to introduce identifier representations (IDs) to allow for retrieval of entity properties, e.g., entity coordinates, from latent system representations and thus enables traceability. Experimentally, across different domains, we show that LaM-SLidE performs favorably in terms of speed, accuracy, and generalizability. (Code is available at https://github.com/ml-jku/LaM-SLidE)
Universal Physics Transformers
Feb 19, 2024



Deep neural network based surrogates for partial differential equations have recently gained increased interest. However, akin to their numerical counterparts, different techniques are used across applications, even if the underlying dynamics of the systems are similar. A prominent example is the Lagrangian and Eulerian specification in computational fluid dynamics, posing a challenge for neural networks to effectively model particle- as opposed to grid-based dynamics. We introduce Universal Physics Transformers (UPTs), a novel learning paradigm which models a wide range of spatio-temporal problems - both for Lagrangian and Eulerian discretization schemes. UPTs operate without grid- or particle-based latent structures, enabling flexibility across meshes and particles. UPTs efficiently propagate dynamics in the latent space, emphasized by inverse encoding and decoding techniques. Finally, UPTs allow for queries of the latent space representation at any point in space-time. We demonstrate the efficacy of UPTs in mesh-based fluid simulations, steady-state Reynolds averaged Navier-Stokes simulations, and Lagrangian-based dynamics. Project page: https://ml-jku.github.io/UPT
Contrastive Tuning: A Little Help to Make Masked Autoencoders Forget
Apr 20, 2023



Masked Image Modeling (MIM) methods, like Masked Autoencoders (MAE), efficiently learn a rich representation of the input. However, for adapting to downstream tasks, they require a sufficient amount of labeled data since their rich features capture not only objects but also less relevant image background. In contrast, Instance Discrimination (ID) methods focus on objects. In this work, we study how to combine the efficiency and scalability of MIM with the ability of ID to perform downstream classification in the absence of large amounts of labeled data. To this end, we introduce Masked Autoencoder Contrastive Tuning (MAE-CT), a sequential approach that applies Nearest Neighbor Contrastive Learning (NNCLR) to a pre-trained MAE. MAE-CT tunes the rich features such that they form semantic clusters of objects without using any labels. Applied to large and huge Vision Transformer (ViT) models, MAE-CT matches or excels previous self-supervised methods trained on ImageNet in linear probing, k-NN and low-shot classification accuracy as well as in unsupervised clustering accuracy. Notably, similar results can be achieved without additional image augmentations. While ID methods generally rely on hand-crafted augmentations to avoid shortcut learning, we find that nearest neighbor lookup is sufficient and that this data-driven augmentation effect improves with model size. MAE-CT is compute efficient. For instance, starting from a MAE pre-trained ViT-L/16, MAE-CT increases the ImageNet 1% low-shot accuracy from 67.7% to 72.6%, linear probing accuracy from 76.0% to 80.2% and k-NN accuracy from 60.6% to 79.1% in just five hours using eight A100 GPUs.
CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP
Oct 21, 2021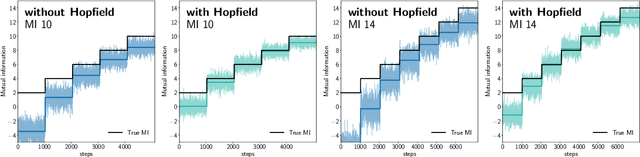
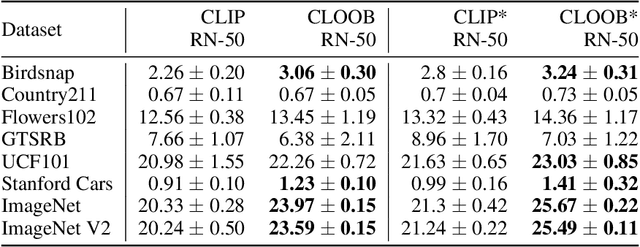
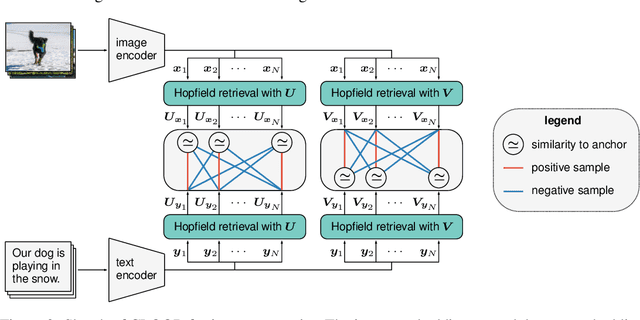
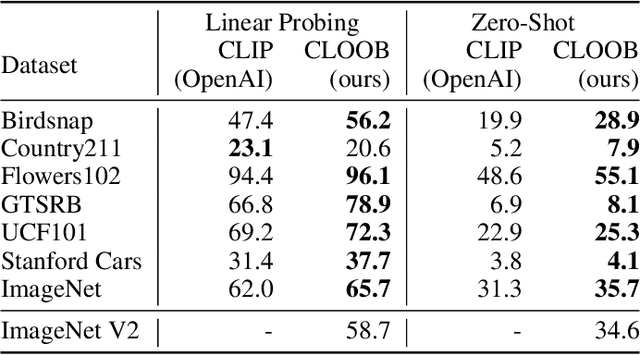
Contrastive learning with the InfoNCE objective is exceptionally successful in various self-supervised learning tasks. Recently, the CLIP model yielded impressive results on zero-shot transfer learning when using InfoNCE for learning visual representations from natural language supervision. However, InfoNCE as a lower bound on the mutual information has been shown to perform poorly for high mutual information. In contrast, the InfoLOOB upper bound (leave one out bound) works well for high mutual information but suffers from large variance and instabilities. We introduce "Contrastive Leave One Out Boost" (CLOOB), where modern Hopfield networks boost learning with the InfoLOOB objective. Modern Hopfield networks replace the original embeddings by retrieved embeddings in the InfoLOOB objective. The retrieved embeddings give InfoLOOB two assets. Firstly, the retrieved embeddings stabilize InfoLOOB, since they are less noisy and more similar to one another than the original embeddings. Secondly, they are enriched by correlations, since the covariance structure of embeddings is reinforced through retrievals. We compare CLOOB to CLIP after learning on the Conceptual Captions and the YFCC dataset with respect to their zero-shot transfer learning performance on other datasets. CLOOB consistently outperforms CLIP at zero-shot transfer learning across all considered architectures and datasets.