 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Exploration to Cope with Non-Stationarity in Lifelong Reinforcement Learning
Jul 12, 2022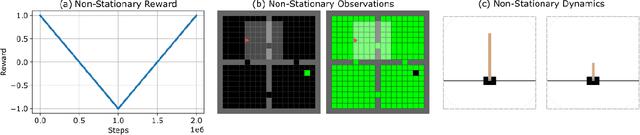
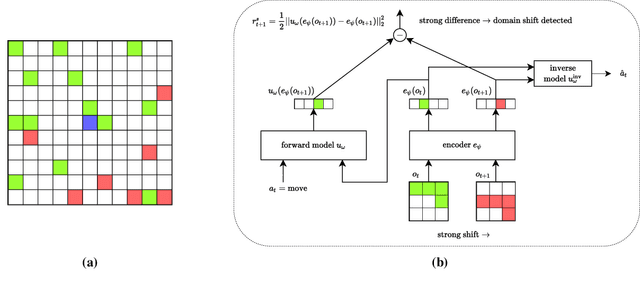
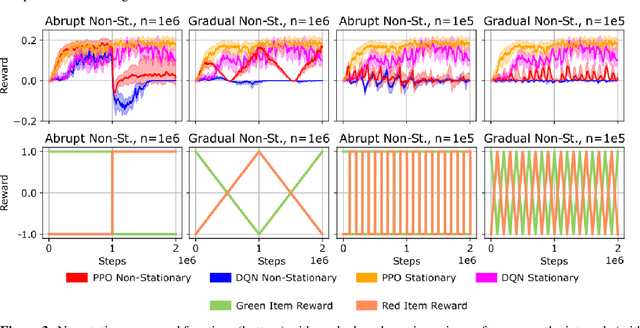
In lifelong learning, an agent learns throughout its entire life without resets, in a constantly changing environment, as we humans do. Consequently, lifelong learning comes with a plethora of research problems such as continual domain shifts, which result in non-stationary rewards and environment dynamics. These non-stationarities are difficult to detect and cope with due to their continuous nature. Therefore, exploration strategies and learning methods are required that are capable of tracking the steady domain shifts, and adapting to them. We propose Reactive Exploration to track and react to continual domain shifts in lifelong reinforcement learning, and to update the policy correspondingly. To this end, we conduct experiments in order to investigate different exploration strategies. We empirically show that representatives of the policy-gradient family are better suited for lifelong learning, as they adapt more quickly to distribution shifts than Q-learning. Thereby, policy-gradient methods profit the most from Reactive Exploration and show good results in lifelong learning with continual domain shifts. Our code is available at: https://github.com/ml-jku/reactive-exploration.
Hopular: Modern Hopfield Networks for Tabular Data
Jun 01, 2022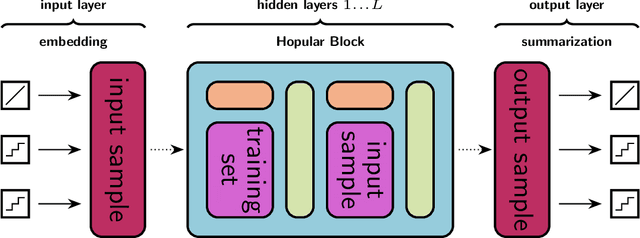
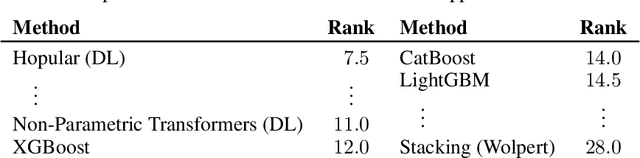
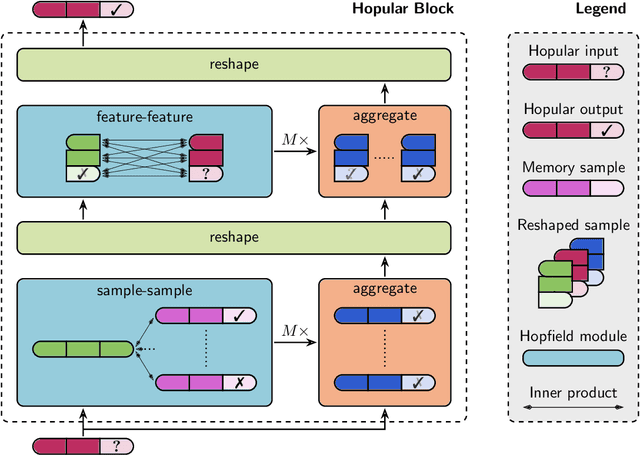
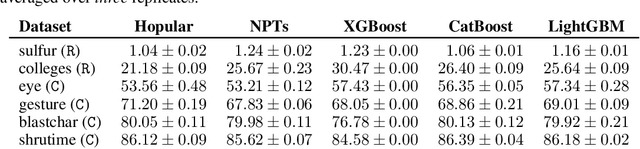
While Deep Learning excels in structured data as encountered in vision and natural language processing, it failed to meet its expectations on tabular data. For tabular data, Support Vector Machines (SVMs), Random Forests, and Gradient Boosting are the best performing techniques with Gradient Boosting in the lead. Recently, we saw a surge of Deep Learning methods that were tailored to tabular data but still underperform compared to Gradient Boosting on small-sized datasets. We suggest "Hopular", a novel Deep Learning architecture for medium- and small-sized datasets, where each layer is equipped with continuous modern Hopfield networks. The modern Hopfield networks use stored data to identify feature-feature, feature-target, and sample-sample dependencies. Hopular's novelty is that every layer can directly access the original input as well as the whole training set via stored data in the Hopfield networks. Therefore, Hopular can step-wise update its current model and the resulting prediction at every layer like standard iterative learning algorithms. In experiments on small-sized tabular datasets with less than 1,000 samples, Hopular surpasses Gradient Boosting, Random Forests, SVMs, and in particular several Deep Learning methods. In experiments on medium-sized tabular data with about 10,000 samples, Hopular outperforms XGBoost, CatBoost, LightGBM and a state-of-the art Deep Learning method designed for tabular data. Thus, Hopular is a strong alternative to these methods on tabular data.
History Compression via Language Models in Reinforcement Learning
May 24, 2022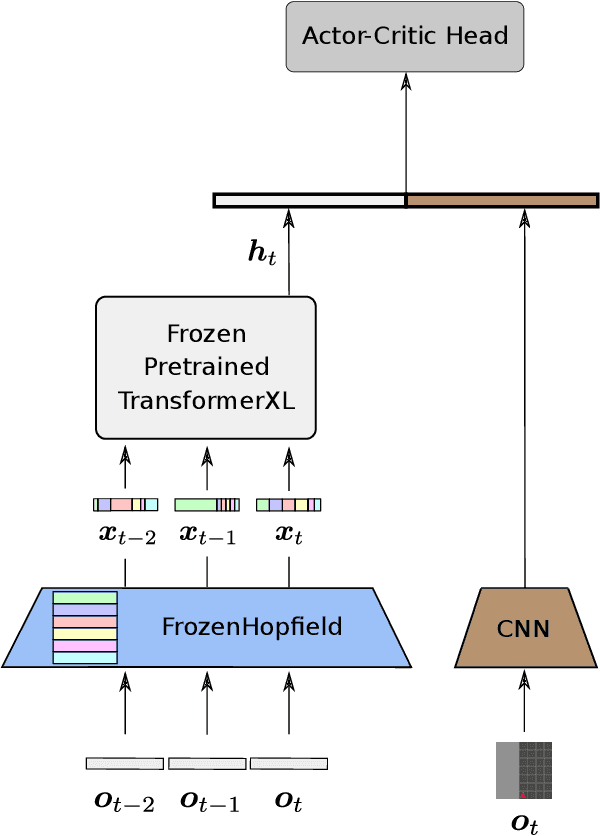

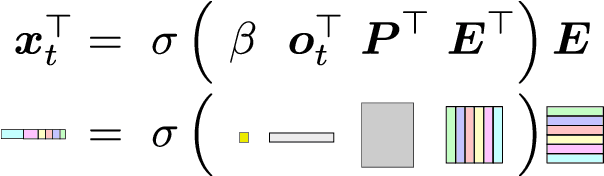

In a partially observable Markov decision process (POMDP), an agent typically uses a representation of the past to approximate the underlying MDP. We propose to utilize a frozen Pretrained Language Transformer (PLT) for history representation and compression to improve sample efficiency. To avoid training of the Transformer, we introduce FrozenHopfield, which automatically associates observations with original token embeddings. To form these associations, a modern Hopfield network stores the original token embeddings, which are retrieved by queries that are obtained by a random but fixed projection of observations. Our new method, HELM, enables actor-critic network architectures that contain a pretrained language Transformer for history representation as a memory module. Since a representation of the past need not be learned, HELM is much more sample efficient than competitors. On Minigrid and Procgen environments HELM achieves new state-of-the-art results. Our code is available at https://github.com/ml-jku/helm.
Understanding the Effects of Dataset Characteristics on Offline Reinforcement Learning
Nov 08, 2021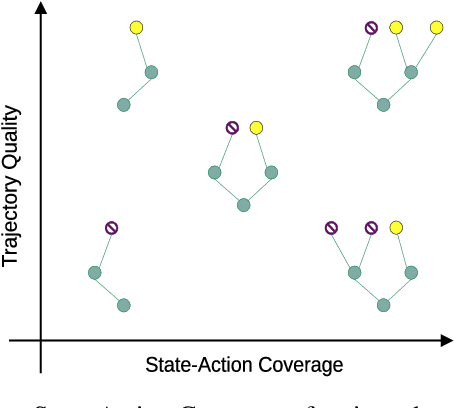
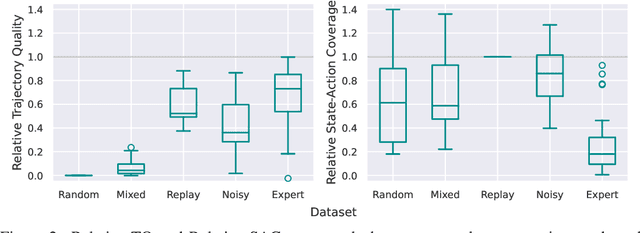
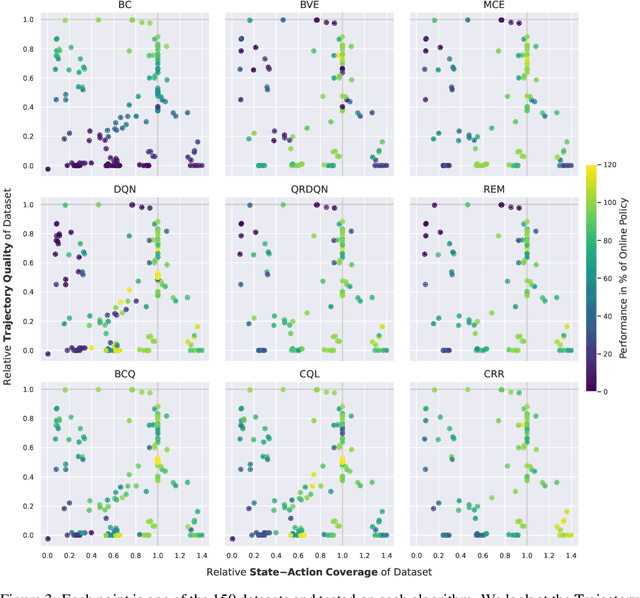

In real world, affecting the environment by a weak policy can be expensive or very risky, therefore hampers real world applications of reinforcement learning. Offline Reinforcement Learning (RL) can learn policies from a given dataset without interacting with the environment. However, the dataset is the only source of information for an Offline RL algorithm and determines the performance of the learned policy. We still lack studies on how dataset characteristics influence different Offline RL algorithms. Therefore, we conducted a comprehensive empirical analysis of how dataset characteristics effect the performance of Offline RL algorithms for discrete action environments. A dataset is characterized by two metrics: (1) the average dataset return measured by the Trajectory Quality (TQ) and (2) the coverage measured by the State-Action Coverage (SACo). We found that variants of the off-policy Deep Q-Network family require datasets with high SACo to perform well. Algorithms that constrain the learned policy towards the given dataset perform well for datasets with high TQ or SACo. For datasets with high TQ, Behavior Cloning outperforms or performs similarly to the best Offline RL algorithms.
CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP
Oct 21, 2021
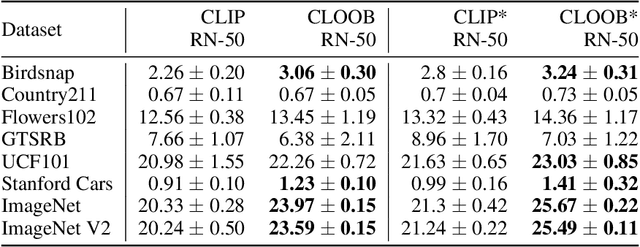
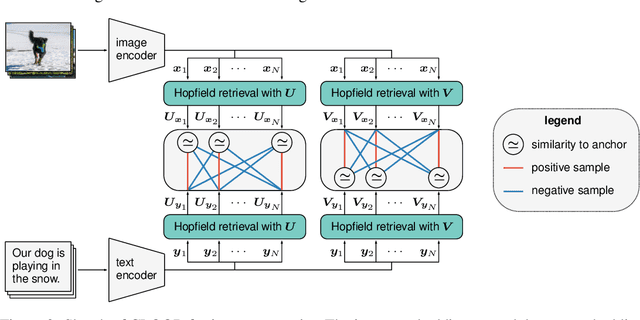
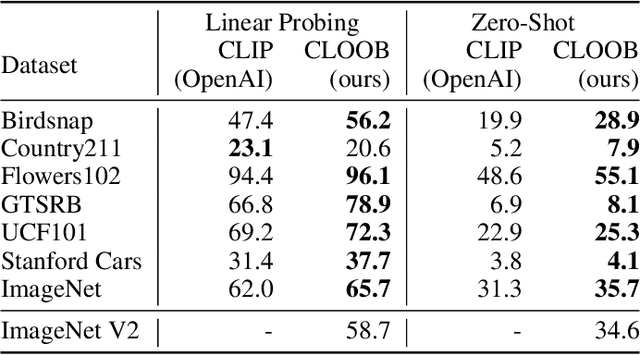
Contrastive learning with the InfoNCE objective is exceptionally successful in various self-supervised learning tasks. Recently, the CLIP model yielded impressive results on zero-shot transfer learning when using InfoNCE for learning visual representations from natural language supervision. However, InfoNCE as a lower bound on the mutual information has been shown to perform poorly for high mutual information. In contrast, the InfoLOOB upper bound (leave one out bound) works well for high mutual information but suffers from large variance and instabilities. We introduce "Contrastive Leave One Out Boost" (CLOOB), where modern Hopfield networks boost learning with the InfoLOOB objective. Modern Hopfield networks replace the original embeddings by retrieved embeddings in the InfoLOOB objective. The retrieved embeddings give InfoLOOB two assets. Firstly, the retrieved embeddings stabilize InfoLOOB, since they are less noisy and more similar to one another than the original embeddings. Secondly, they are enriched by correlations, since the covariance structure of embeddings is reinforced through retrievals. We compare CLOOB to CLIP after learning on the Conceptual Captions and the YFCC dataset with respect to their zero-shot transfer learning performance on other datasets. CLOOB consistently outperforms CLIP at zero-shot transfer learning across all considered architectures and datasets.