 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Abstraction for Reinforcement Learning
Oct 01, 2024



Learning agents with reinforcement learning is difficult when dealing with long trajectories that involve a large number of states. To address these learning problems effectively, the number of states can be reduced by abstract representations that cluster states. In principle, deep reinforcement learning can find abstract states, but end-to-end learning is unstable. We propose contrastive abstraction learning to find abstract states, where we assume that successive states in a trajectory belong to the same abstract state. Such abstract states may be basic locations, achieved subgoals, inventory, or health conditions. Contrastive abstraction learning first constructs clusters of state representations by contrastive learning and then applies modern Hopfield networks to determine the abstract states. The first phase of contrastive abstraction learning is self-supervised learning, where contrastive learning forces states with sequential proximity to have similar representations. The second phase uses modern Hopfield networks to map similar state representations to the same fixed point, i.e.\ to an abstract state. The level of abstraction can be adjusted by determining the number of fixed points of the modern Hopfield network. Furthermore, \textit{contrastive abstraction learning} does not require rewards and facilitates efficient reinforcement learning for a wide range of downstream tasks. Our experiments demonstrate the effectiveness of contrastive abstraction learning for reinforcement learning.
Contrastive Tuning: A Little Help to Make Masked Autoencoders Forget
Apr 20, 2023



Masked Image Modeling (MIM) methods, like Masked Autoencoders (MAE), efficiently learn a rich representation of the input. However, for adapting to downstream tasks, they require a sufficient amount of labeled data since their rich features capture not only objects but also less relevant image background. In contrast, Instance Discrimination (ID) methods focus on objects. In this work, we study how to combine the efficiency and scalability of MIM with the ability of ID to perform downstream classification in the absence of large amounts of labeled data. To this end, we introduce Masked Autoencoder Contrastive Tuning (MAE-CT), a sequential approach that applies Nearest Neighbor Contrastive Learning (NNCLR) to a pre-trained MAE. MAE-CT tunes the rich features such that they form semantic clusters of objects without using any labels. Applied to large and huge Vision Transformer (ViT) models, MAE-CT matches or excels previous self-supervised methods trained on ImageNet in linear probing, k-NN and low-shot classification accuracy as well as in unsupervised clustering accuracy. Notably, similar results can be achieved without additional image augmentations. While ID methods generally rely on hand-crafted augmentations to avoid shortcut learning, we find that nearest neighbor lookup is sufficient and that this data-driven augmentation effect improves with model size. MAE-CT is compute efficient. For instance, starting from a MAE pre-trained ViT-L/16, MAE-CT increases the ImageNet 1% low-shot accuracy from 67.7% to 72.6%, linear probing accuracy from 76.0% to 80.2% and k-NN accuracy from 60.6% to 79.1% in just five hours using eight A100 GPUs.
CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP
Oct 21, 2021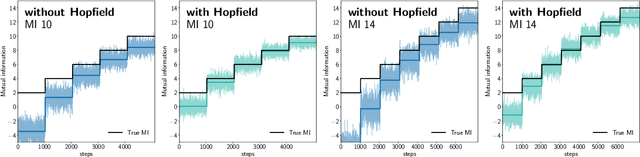
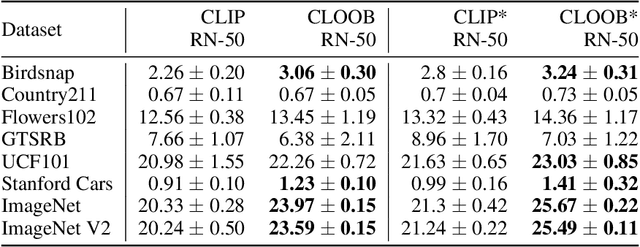
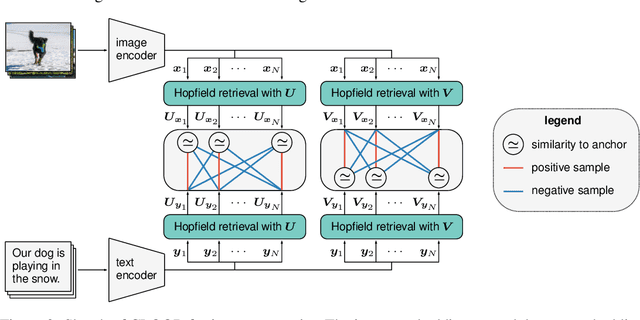
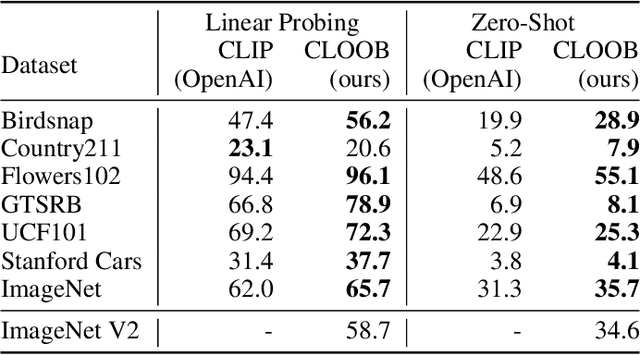
Contrastive learning with the InfoNCE objective is exceptionally successful in various self-supervised learning tasks. Recently, the CLIP model yielded impressive results on zero-shot transfer learning when using InfoNCE for learning visual representations from natural language supervision. However, InfoNCE as a lower bound on the mutual information has been shown to perform poorly for high mutual information. In contrast, the InfoLOOB upper bound (leave one out bound) works well for high mutual information but suffers from large variance and instabilities. We introduce "Contrastive Leave One Out Boost" (CLOOB), where modern Hopfield networks boost learning with the InfoLOOB objective. Modern Hopfield networks replace the original embeddings by retrieved embeddings in the InfoLOOB objective. The retrieved embeddings give InfoLOOB two assets. Firstly, the retrieved embeddings stabilize InfoLOOB, since they are less noisy and more similar to one another than the original embeddings. Secondly, they are enriched by correlations, since the covariance structure of embeddings is reinforced through retrievals. We compare CLOOB to CLIP after learning on the Conceptual Captions and the YFCC dataset with respect to their zero-shot transfer learning performance on other datasets. CLOOB consistently outperforms CLIP at zero-shot transfer learning across all considered architectures and datasets.
Large-scale ligand-based virtual screening for SARS-CoV-2 inhibitors using deep neural networks
Apr 03, 2020
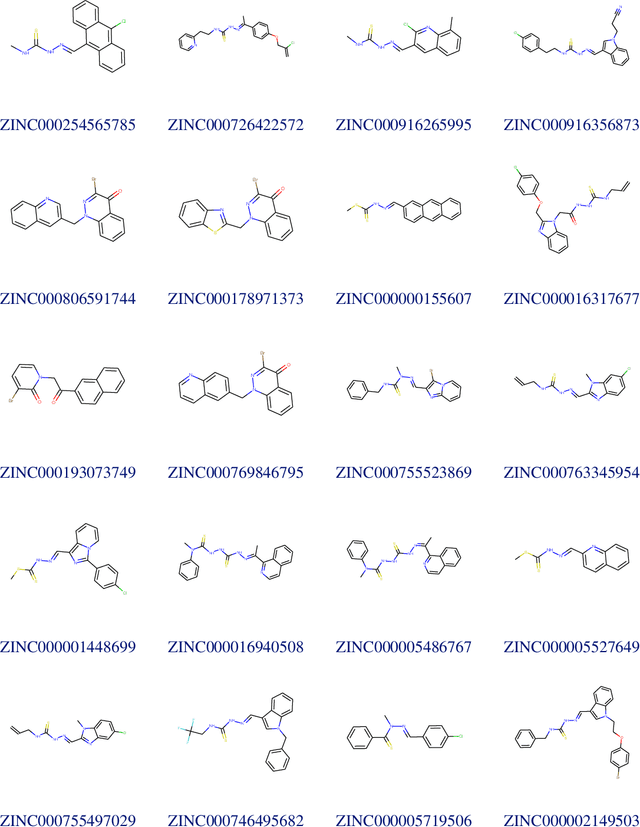


Due to the current severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) pandemic, there is an urgent need for novel therapies and drugs. We conducted a large-scale virtual screening for small molecules that are potential CoV-2 inhibitors. To this end, we utilized "ChemAI", a deep neural network trained on more than 220M data points across 3.6M molecules from three public drug-discovery databases. With ChemAI, we screened and ranked one billion molecules from the ZINC database for favourable effects against CoV-2. We then reduced the result to the 30,000 top-ranked compounds, which are readily accessible and purchasable via the ZINC database. Additionally, we screened the DrugBank using ChemAI to allow for drug repurposing, which would be a fast way towards a therapy. We provide these top-ranked compounds of ZINC and DrugBank as a library for further screening with bioassays at https://github.com/ml-jku/sars-cov-inhibitors-chemai.
Detecting cutaneous basal cell carcinomas in ultra-high resolution and weakly labelled histopathological images
Dec 02, 2019

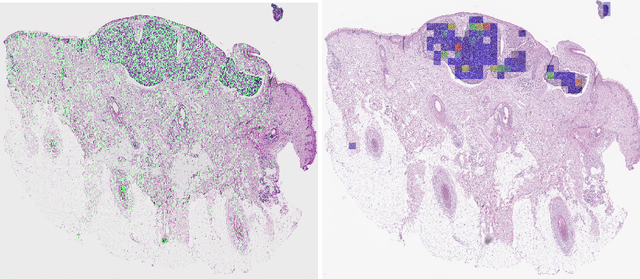
Diagnosing basal cell carcinomas (BCC), one of the most common cutaneous malignancies in humans, is a task regularly performed by pathologists and dermato-pathologists. Improving histological diagnosis by providing diagnosis suggestions, i.e. computer-assisted diagnoses is actively researched to improve safety, quality and efficiency. Increasingly, machine learning methods are applied due to their superior performance. However, typical images obtained by scanning histological sections often have a resolution that is prohibitive for processing with current state-of-the-art neural networks. Furthermore, the data pose a problem of weak labels, since only a tiny fraction of the image is indicative of the disease class, whereas a large fraction of the image is highly similar to the non-disease class. The aim of this study is to evaluate whether it is possible to detect basal cell carcinomas in histological sections using attention-based deep learning models and to overcome the ultra-high resolution and the weak labels of whole slide images. We demonstrate that attention-based models can indeed yield almost perfect classification performance with an AUC of 0.99.