 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI4EOSC: a Federated Cloud Platform for Artificial Intelligence in Scientific Research
Dec 18, 2025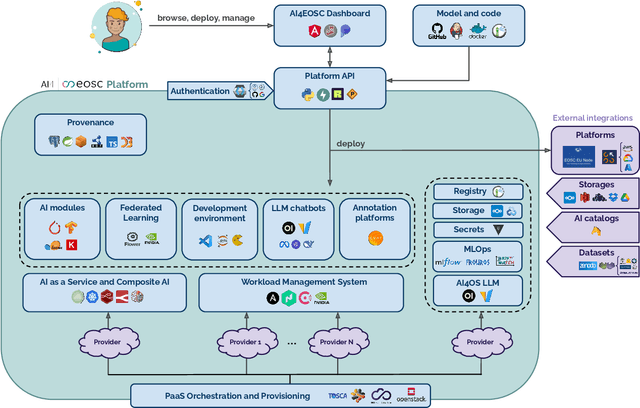
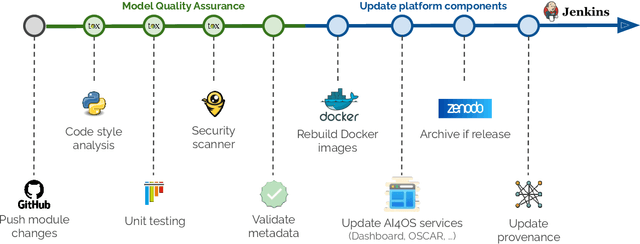
In this paper, we describe a federated compute platform dedicated to support Artificial Intelligence in scientific workloads. Putting the effort into reproducible deployments, it delivers consistent, transparent access to a federation of physically distributed e-Infrastructures. Through a comprehensive service catalogue, the platform is able to offer an integrated user experience covering the full Machine Learning lifecycle, including model development (with dedicated interactive development environments), training (with GPU resources, annotation tools, experiment tracking, and federated learning support) and deployment (covering a wide range of deployment options all along the Cloud Continuum). The platform also provides tools for traceability and reproducibility of AI models, integrates with different Artificial Intelligence model providers, datasets and storage resources, allowing users to interact with the broader Machine Learning ecosystem. Finally, it is easily customizable to lower the adoption barrier by external communities.
Intervention Efficiency and Perturbation Validation Framework: Capacity-Aware and Robust Clinical Model Selection under the Rashomon Effect
Nov 18, 2025In clinical machine learning, the coexistence of multiple models with comparable performance -- a manifestation of the Rashomon Effect -- poses fundamental challenges for trustworthy deployment and evaluation. Small, imbalanced, and noisy datasets, coupled with high-dimensional and weakly identified clinical features, amplify this multiplicity and make conventional validation schemes unreliable. As a result, selecting among equally performing models becomes uncertain, particularly when resource constraints and operational priorities are not considered by conventional metrics like F1 score. To address these issues, we propose two complementary tools for robust model assessment and selection: Intervention Efficiency (IE) and the Perturbation Validation Framework (PVF). IE is a capacity-aware metric that quantifies how efficiently a model identifies actionable true positives when only limited interventions are feasible, thereby linking predictive performance with clinical utility. PVF introduces a structured approach to assess the stability of models under data perturbations, identifying models whose performance remains most invariant across noisy or shifted validation sets. Empirical results on synthetic and real-world healthcare datasets show that using these tools facilitates the selection of models that generalize more robustly and align with capacity constraints, offering a new direction for tackling the Rashomon Effect in clinical settings.
An Effective Deep Network for Head Pose Estimation without Keypoints
Oct 25, 2022



Human head pose estimation is an essential problem in facial analysis in recent years that has a lot of computer vision applications such as gaze estimation, virtual reality, and driver assistance. Because of the importance of the head pose estimation problem, it is necessary to design a compact model to resolve this task in order to reduce the computational cost when deploying on facial analysis-based applications such as large camera surveillance systems, AI cameras while maintaining accuracy. In this work, we propose a lightweight model that effectively addresses the head pose estimation problem. Our approach has two main steps. 1) We first train many teacher models on the synthesis dataset - 300W-LPA to get the head pose pseudo labels. 2) We design an architecture with the ResNet18 backbone and train our proposed model with the ensemble of these pseudo labels via the knowledge distillation process. To evaluate the effectiveness of our model, we use AFLW-2000 and BIWI - two real-world head pose datasets. Experimental results show that our proposed model significantly improves the accuracy in comparison with the state-of-the-art head pose estimation methods. Furthermore, our model has the real-time speed of $\sim$300 FPS when inferring on Tesla V100.
CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP
Oct 21, 2021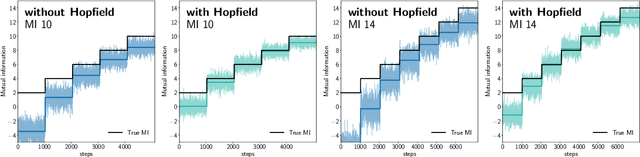
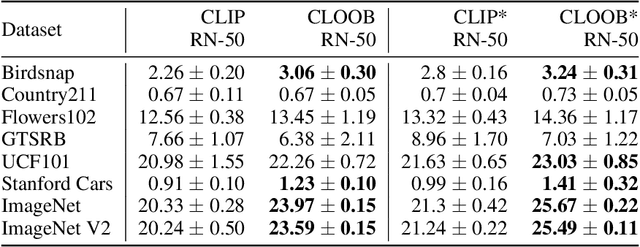
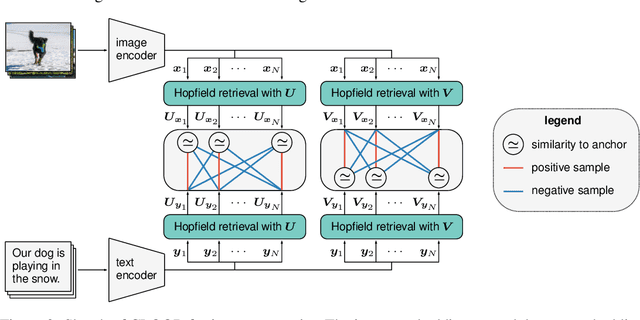
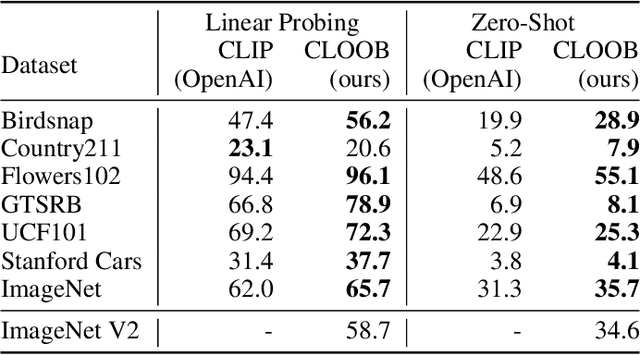
Contrastive learning with the InfoNCE objective is exceptionally successful in various self-supervised learning tasks. Recently, the CLIP model yielded impressive results on zero-shot transfer learning when using InfoNCE for learning visual representations from natural language supervision. However, InfoNCE as a lower bound on the mutual information has been shown to perform poorly for high mutual information. In contrast, the InfoLOOB upper bound (leave one out bound) works well for high mutual information but suffers from large variance and instabilities. We introduce "Contrastive Leave One Out Boost" (CLOOB), where modern Hopfield networks boost learning with the InfoLOOB objective. Modern Hopfield networks replace the original embeddings by retrieved embeddings in the InfoLOOB objective. The retrieved embeddings give InfoLOOB two assets. Firstly, the retrieved embeddings stabilize InfoLOOB, since they are less noisy and more similar to one another than the original embeddings. Secondly, they are enriched by correlations, since the covariance structure of embeddings is reinforced through retrievals. We compare CLOOB to CLIP after learning on the Conceptual Captions and the YFCC dataset with respect to their zero-shot transfer learning performance on other datasets. CLOOB consistently outperforms CLIP at zero-shot transfer learning across all considered architectures and datasets.
Unsupervised Anomaly Detection for X-Ray Images
Jan 29, 2020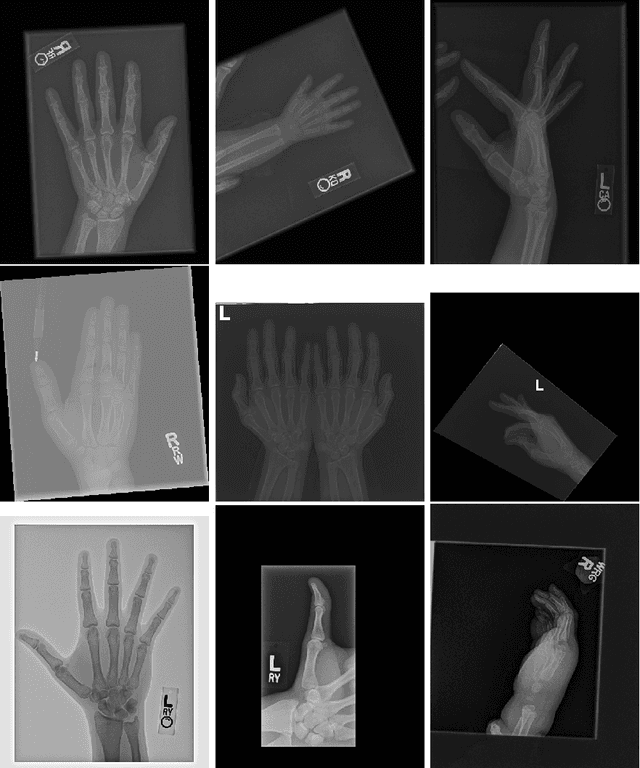
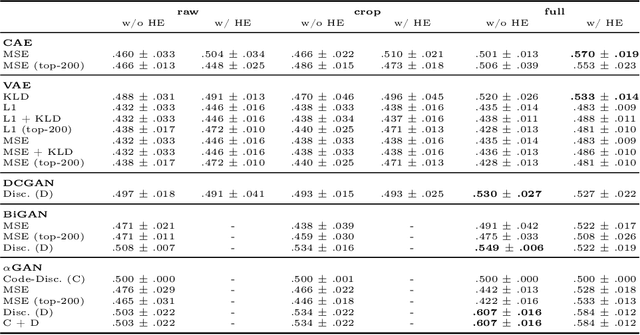

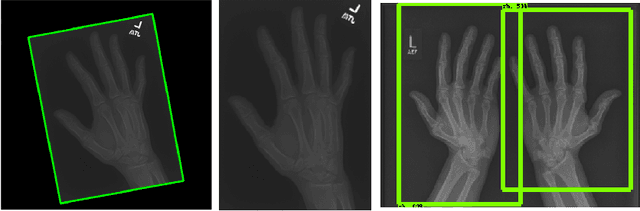
Obtaining labels for medical (image) data requires scarce and expensive experts. Moreover, due to ambiguous symptoms, single images rarely suffice to correctly diagnose a medical condition. Instead, it often requires to take additional background information such as the patient's medical history or test results into account. Hence, instead of focusing on uninterpretable black-box systems delivering an uncertain final diagnosis in an end-to-end-fashion, we investigate how unsupervised methods trained on images without anomalies can be used to assist doctors in evaluating X-ray images of hands. Our method increases the efficiency of making a diagnosis and reduces the risk of missing important regions. Therefore, we adopt state-of-the-art approaches for unsupervised learning to detect anomalies and show how the outputs of these methods can be explained. To reduce the effect of noise, which often can be mistaken for an anomaly, we introduce a powerful preprocessing pipeline. We provide an extensive evaluation of different approaches and demonstrate empirically that even without labels it is possible to achieve satisfying results on a real-world dataset of X-ray images of hands. We also evaluate the importance of preprocessing and one of our main findings is that without it, most of our approaches perform not better than random. To foster reproducibility and accelerate research we make our code publicly available at https://github.com/Valentyn1997/xray