 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Holistic View on Argument Quality Prediction
May 19, 2022
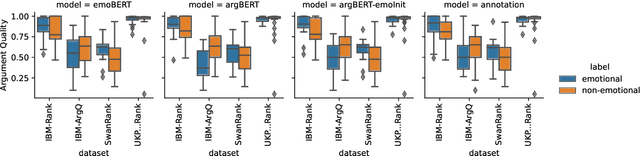
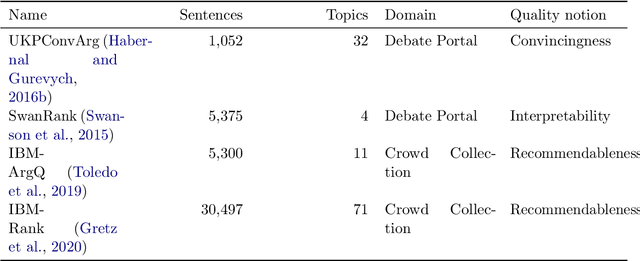

Argumentation is one of society's foundational pillars, and, sparked by advances in NLP and the vast availability of text data, automated mining of arguments receives increasing attention. A decisive property of arguments is their strength or quality. While there are works on the automated estimation of argument strength, their scope is narrow: they focus on isolated datasets and neglect the interactions with related argument mining tasks, such as argument identification, evidence detection, or emotional appeal. In this work, we close this gap by approaching argument quality estimation from multiple different angles: Grounded on rich results from thorough empirical evaluations, we assess the generalization capabilities of argument quality estimation across diverse domains, the interplay with related argument mining tasks, and the impact of emotions on perceived argument strength. We find that generalization depends on a sufficient representation of different domains in the training part. In zero-shot transfer and multi-task experiments, we reveal that argument quality is among the more challenging tasks but can improve others. Finally, we show that emotions play a minor role in argument quality than is often assumed.
Active Learning for Argument Strength Estimation
Sep 23, 2021
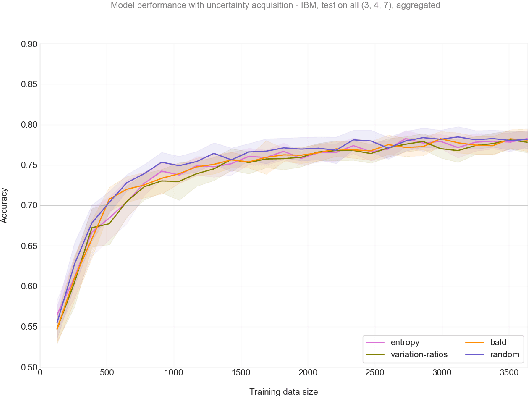

High-quality arguments are an essential part of decision-making. Automatically predicting the quality of an argument is a complex task that recently got much attention in argument mining. However, the annotation effort for this task is exceptionally high. Therefore, we test uncertainty-based active learning (AL) methods on two popular argument-strength data sets to estimate whether sample-efficient learning can be enabled. Our extensive empirical evaluation shows that uncertainty-based acquisition functions can not surpass the accuracy reached with the random acquisition on these data sets.
Prediction of soft proton intensities in the near-Earth space using machine learning
May 11, 2021
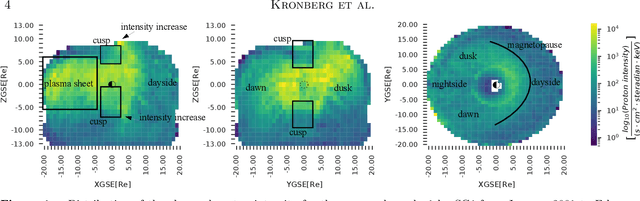
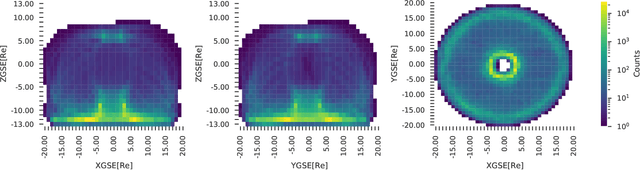

The spatial distribution of energetic protons contributes towards the understanding of magnetospheric dynamics. Based upon 17 years of the Cluster/RAPID observations, we have derived machine learning-based models to predict the proton intensities at energies from 28 to 1,885 keV in the 3D terrestrial magnetosphere at radial distances between 6 and 22 RE. We used the satellite location and indices for solar, solar wind and geomagnetic activity as predictors. The results demonstrate that the neural network (multi-layer perceptron regressor) outperforms baseline models based on the k-Nearest Neighbors and historical binning on average by ~80% and ~33\%, respectively. The average correlation between the observed and predicted data is about 56%, which is reasonable in light of the complex dynamics of fast-moving energetic protons in the magnetosphere. In addition to a quantitative analysis of the prediction results, we also investigate parameter importance in our model. The most decisive parameters for predicting proton intensities are related to the location: ZGSE direction and the radial distance. Among the activity indices, the solar wind dynamic pressure is the most important. The results have a direct practical application, for instance, for assessing the contamination particle background in the X-Ray telescopes for X-ray astronomy orbiting above the radiation belts. To foster reproducible research and to enable the community to build upon our work we publish our complete code, the data, as well as weights of trained models. Further description can be found in the GitHub project at https://github.com/Tanveer81/deep_horizon.
Argument Mining Driven Analysis of Peer-Reviews
Dec 10, 2020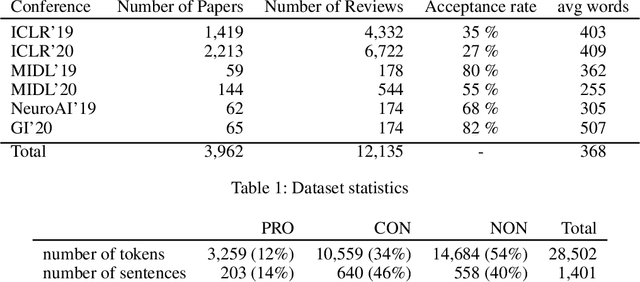
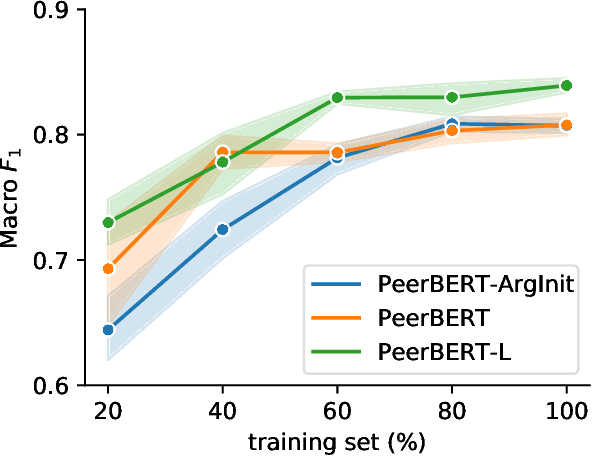

Peer reviewing is a central process in modern research and essential for ensuring high quality and reliability of published work. At the same time, it is a time-consuming process and increasing interest in emerging fields often results in a high review workload, especially for senior researchers in this area. How to cope with this problem is an open question and it is vividly discussed across all major conferences. In this work, we propose an Argument Mining based approach for the assistance of editors, meta-reviewers, and reviewers. We demonstrate that the decision process in the field of scientific publications is driven by arguments and automatic argument identification is helpful in various use-cases. One of our findings is that arguments used in the peer-review process differ from arguments in other domains making the transfer of pre-trained models difficult. Therefore, we provide the community with a new peer-review dataset from different computer science conferences with annotated arguments. In our extensive empirical evaluation, we show that Argument Mining can be used to efficiently extract the most relevant parts from reviews, which are paramount for the publication decision. The process remains interpretable since the extracted arguments can be highlighted in a review without detaching them from their context.
Diversity Aware Relevance Learning for Argument Search
Nov 11, 2020
In this work, we focus on the problem of retrieving relevant arguments for a query claim covering diverse aspects. State-of-the-art methods rely on explicit mappings between claims and premises, and thus are unable to utilize large available collections of premises without laborious and costly manual annotation. Their diversity approach relies on removing duplicates via clustering which does not directly ensure that the selected premises cover all aspects. This work introduces a new multi-step approach for the argument retrieval problem. Rather than relying on ground-truth assignments, our approach employs a machine learning model to capture semantic relationships between arguments. Beyond that, it aims to cover diverse facets of the query, instead of trying to identify duplicates explicitly. Our empirical evaluation demonstrates that our approach leads to a significant improvement in the argument retrieval task even though it requires less data.
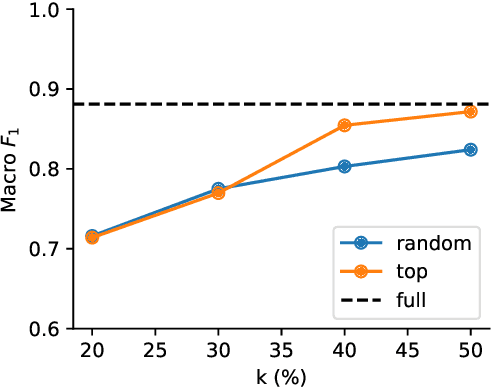
A Critical Assessment of State-of-the-Art in Entity Alignment
Oct 30, 2020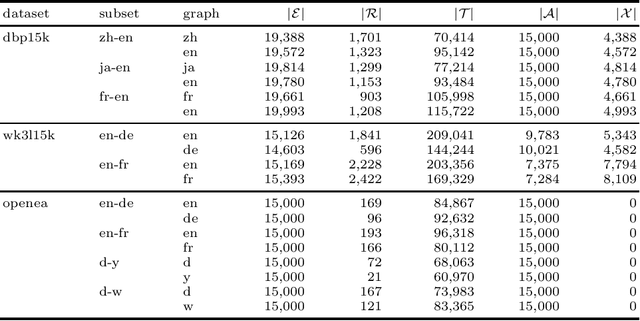

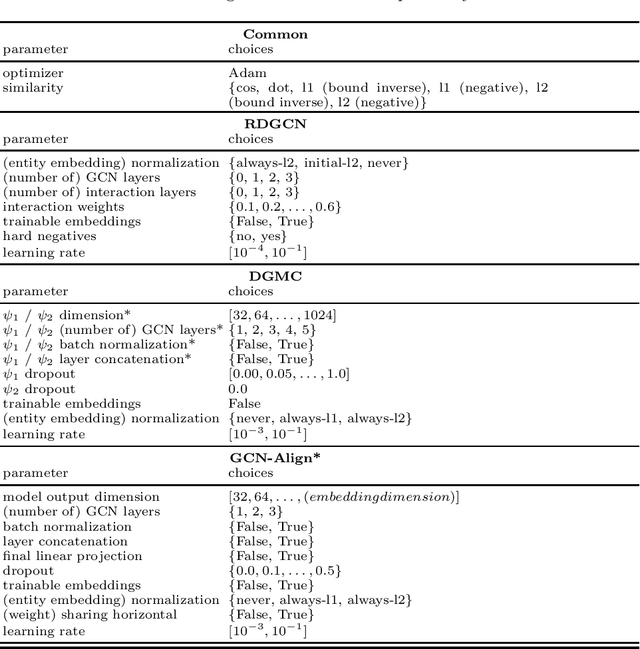
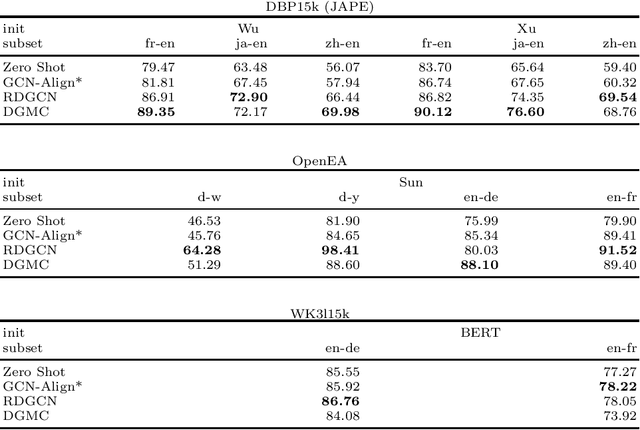
In this work, we perform an extensive investigation of two state-of-the-art (SotA) methods for the task of Entity Alignment in Knowledge Graphs. Therefore, we first carefully examine the benchmarking process and identify several shortcomings, which make the results reported in the original works not always comparable. Furthermore, we suspect that it is a common practice in the community to make the hyperparameter optimization directly on a test set, reducing the informative value of reported performance. Thus, we select a representative sample of benchmarking datasets and describe their properties. We also examine different initializations for entity representations since they are a decisive factor for model performance. Furthermore, we use a shared train/validation/test split for a fair evaluation setting in which we evaluate all methods on all datasets. In our evaluation, we make several interesting findings. While we observe that most of the time SotA approaches perform better than baselines, they have difficulties when the dataset contains noise, which is the case in most real-life applications. Moreover, we find out in our ablation study that often different features of SotA methods are crucial for good performance than previously assumed. The code is available at https://github.com/mberr/ea-sota-comparison.
Matching the Clinical Reality: Accurate OCT-Based Diagnosis From Few Labels
Oct 23, 2020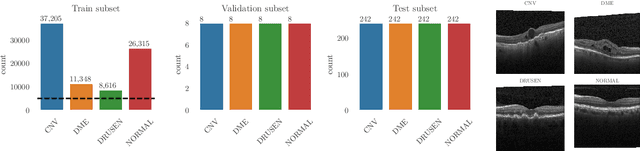
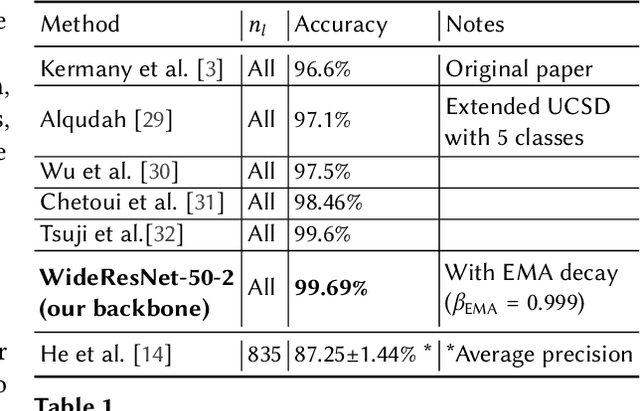

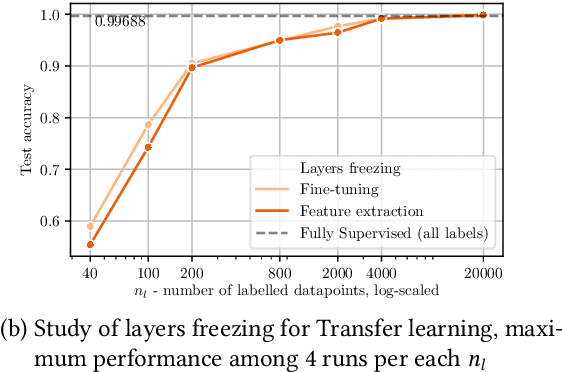
Unlabeled data is often abundant in the clinic, making machine learning methods based on semi-supervised learning a good match for this setting. Despite this, they are currently receiving relatively little attention in medical image analysis literature. Instead, most practitioners and researchers focus on supervised or transfer learning approaches. The recently proposed MixMatch and FixMatch algorithms have demonstrated promising results in extracting useful representations while requiring very few labels. Motivated by these recent successes, we apply MixMatch and FixMatch in an ophthalmological diagnostic setting and investigate how they fare against standard transfer learning. We find that both algorithms outperform the transfer learning baseline on all fractions of labelled data. Furthermore, our experiments show that exponential moving average (EMA) of model parameters, which is a component of both algorithms, is not needed for our classification problem, as disabling it leaves the outcome unchanged. Our code is available online: https://github.com/Valentyn1997/oct-diagn-semi-supervised
Learning Self-Expression Metrics for Scalable and Inductive Subspace Clustering
Sep 27, 2020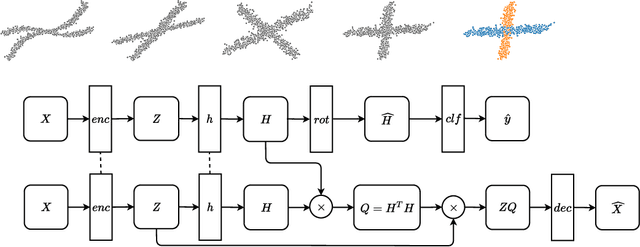

Subspace clustering has established itself as a state-of-the-art approach to clustering high-dimensional data. In particular, methods relying on the self-expressiveness property have recently proved especially successful. However, they suffer from two major shortcomings: First, a quadratic-size coefficient matrix is learned directly, preventing these methods from scaling beyond small datasets. Secondly, the trained models are transductive and thus cannot be used to cluster out-of-sample data unseen during training. Instead of learning self-expression coefficients directly, we propose a novel metric learning approach to learn instead a subspace affinity function using a siamese neural network architecture. Consequently, our model benefits from a constant number of parameters and a constant-size memory footprint, allowing it to scale to considerably larger datasets. In addition, we can formally show that out model is still able to exactly recover subspace clusters given an independence assumption. The siamese architecture in combination with a novel geometric classifier further makes our model inductive, allowing it to cluster out-of-sample data. Additionally, non-linear clusters can be detected by simply adding an auto-encoder module to the architecture. The whole model can then be trained end-to-end in a self-supervised manner. This work in progress reports promising preliminary results on the MNIST dataset. In the spirit of reproducible research, me make all code publicly available. In future work we plan to investigate several extensions of our model and to expand experimental evaluation.
Interpretable and Fair Comparison of Link Prediction or Entity Alignment Methods with Adjusted Mean Rank
Feb 17, 2020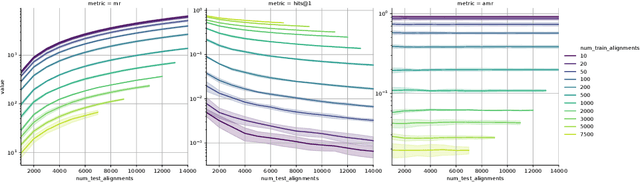
In this work, we take a closer look at the evaluation of two families of methods for enriching information from knowledge graphs: Link Prediction and Entity Alignment. In the current experimental setting, multiple different scores are employed to assess different aspects of model performance. We analyze the informative value of these evaluation measures and identify several shortcomings. In particular, we demonstrate that all existing scores can hardly be used to compare results across different datasets. Moreover, this problem may also arise when comparing different train/test splits for the same dataset. We show that this leads to various problems in the interpretation of results, which may support misleading conclusions. Therefore, we propose a different evaluation and demonstrate empirically how this helps for fair, comparable and interpretable assessment of model performance.
Unsupervised Anomaly Detection for X-Ray Images
Jan 29, 2020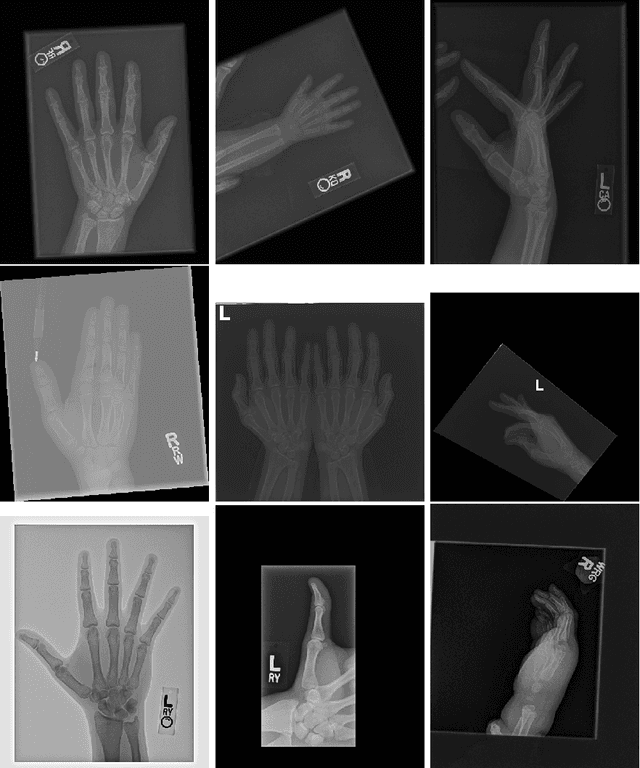
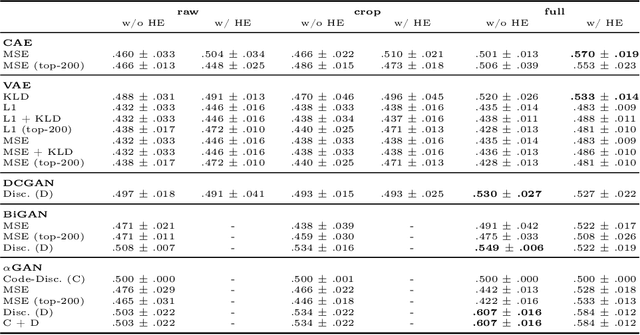

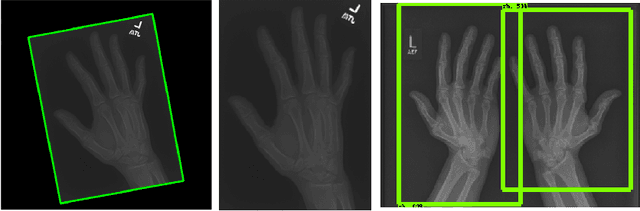
Obtaining labels for medical (image) data requires scarce and expensive experts. Moreover, due to ambiguous symptoms, single images rarely suffice to correctly diagnose a medical condition. Instead, it often requires to take additional background information such as the patient's medical history or test results into account. Hence, instead of focusing on uninterpretable black-box systems delivering an uncertain final diagnosis in an end-to-end-fashion, we investigate how unsupervised methods trained on images without anomalies can be used to assist doctors in evaluating X-ray images of hands. Our method increases the efficiency of making a diagnosis and reduces the risk of missing important regions. Therefore, we adopt state-of-the-art approaches for unsupervised learning to detect anomalies and show how the outputs of these methods can be explained. To reduce the effect of noise, which often can be mistaken for an anomaly, we introduce a powerful preprocessing pipeline. We provide an extensive evaluation of different approaches and demonstrate empirically that even without labels it is possible to achieve satisfying results on a real-world dataset of X-ray images of hands. We also evaluate the importance of preprocessing and one of our main findings is that without it, most of our approaches perform not better than random. To foster reproducibility and accelerate research we make our code publicly available at https://github.com/Valentyn1997/xray