 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable and Fair Comparison of Link Prediction or Entity Alignment Methods with Adjusted Mean Rank
Paper and Code
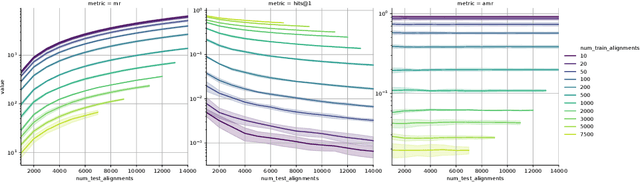
In this work, we take a closer look at the evaluation of two families of methods for enriching information from knowledge graphs: Link Prediction and Entity Alignment. In the current experimental setting, multiple different scores are employed to assess different aspects of model performance. We analyze the informative value of these evaluation measures and identify several shortcomings. In particular, we demonstrate that all existing scores can hardly be used to compare results across different datasets. Moreover, this problem may also arise when comparing different train/test splits for the same dataset. We show that this leads to various problems in the interpretation of results, which may support misleading conclusions. Therefore, we propose a different evaluation and demonstrate empirically how this helps for fair, comparable and interpretable assessment of model performance.