 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Answering of Graph Queries
Aug 12, 2023Knowledge graphs (KGs) are inherently incomplete because of incomplete world knowledge and bias in what is the input to the KG. Additionally, world knowledge constantly expands and evolves, making existing facts deprecated or introducing new ones. However, we would still want to be able to answer queries as if the graph were complete. In this chapter, we will give an overview of several methods which have been proposed to answer queries in such a setting. We will first provide an overview of the different query types which can be supported by these methods and datasets typically used for evaluation, as well as an insight into their limitations. Then, we give an overview of the different approaches and describe them in terms of expressiveness, supported graph types, and inference capabilities.
Towards a Holistic View on Argument Quality Prediction
May 19, 2022
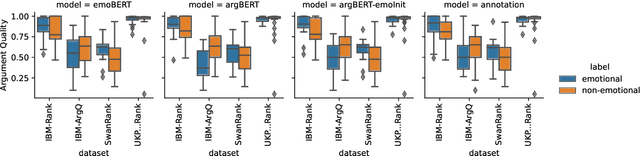
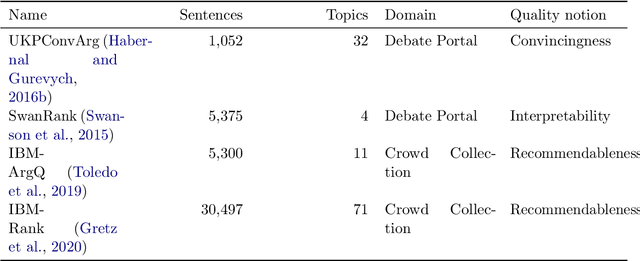

Argumentation is one of society's foundational pillars, and, sparked by advances in NLP and the vast availability of text data, automated mining of arguments receives increasing attention. A decisive property of arguments is their strength or quality. While there are works on the automated estimation of argument strength, their scope is narrow: they focus on isolated datasets and neglect the interactions with related argument mining tasks, such as argument identification, evidence detection, or emotional appeal. In this work, we close this gap by approaching argument quality estimation from multiple different angles: Grounded on rich results from thorough empirical evaluations, we assess the generalization capabilities of argument quality estimation across diverse domains, the interplay with related argument mining tasks, and the impact of emotions on perceived argument strength. We find that generalization depends on a sufficient representation of different domains in the training part. In zero-shot transfer and multi-task experiments, we reveal that argument quality is among the more challenging tasks but can improve others. Finally, we show that emotions play a minor role in argument quality than is often assumed.
A Unified Framework for Rank-based Evaluation Metrics for Link Prediction in Knowledge Graphs
Mar 14, 2022

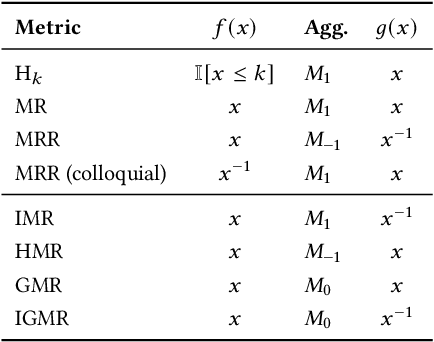
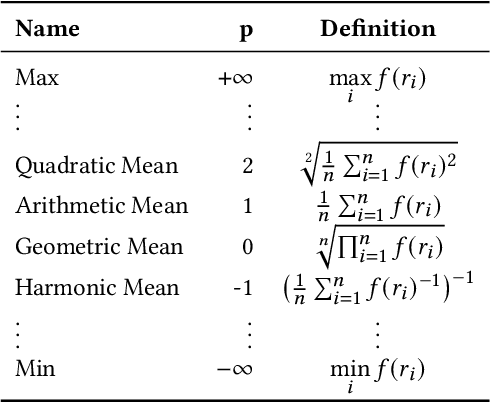
The link prediction task on knowledge graphs without explicit negative triples in the training data motivates the usage of rank-based metrics. Here, we review existing rank-based metrics and propose desiderata for improved metrics to address lack of interpretability and comparability of existing metrics to datasets of different sizes and properties. We introduce a simple theoretical framework for rank-based metrics upon which we investigate two avenues for improvements to existing metrics via alternative aggregation functions and concepts from probability theory. We finally propose several new rank-based metrics that are more easily interpreted and compared accompanied by a demonstration of their usage in a benchmarking of knowledge graph embedding models.
An Open Challenge for Inductive Link Prediction on Knowledge Graphs
Mar 03, 2022
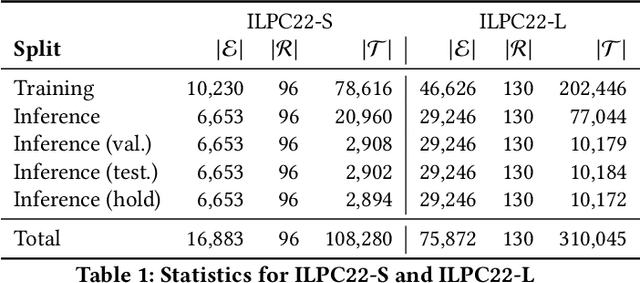
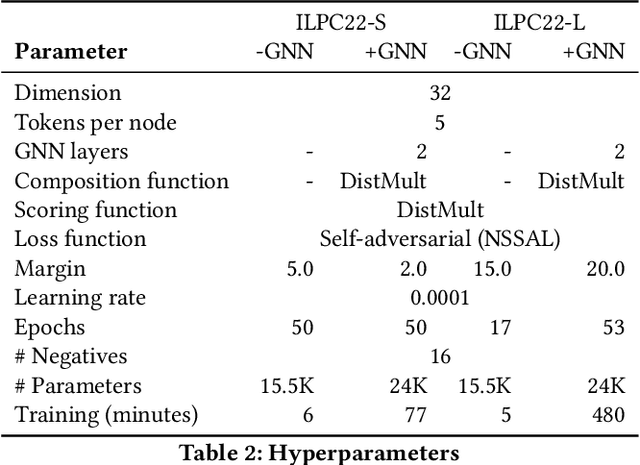
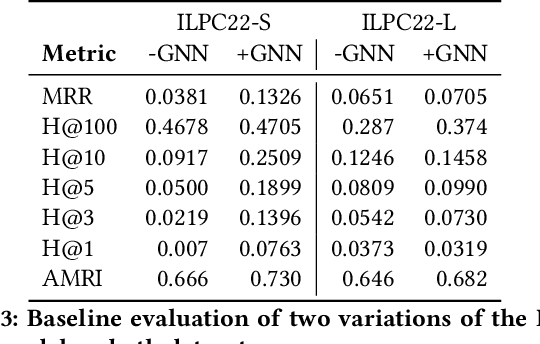
An emerging trend in representation learning over knowledge graphs (KGs) moves beyond transductive link prediction tasks over a fixed set of known entities in favor of inductive tasks that imply training on one graph and performing inference over a new graph with unseen entities. In inductive setups, node features are often not available and training shallow entity embedding matrices is meaningless as they cannot be used at inference time with unseen entities. Despite the growing interest, there are not enough benchmarks for evaluating inductive representation learning methods. In this work, we introduce ILPC 2022, a novel open challenge on KG inductive link prediction. To this end, we constructed two new datasets based on Wikidata with various sizes of training and inference graphs that are much larger than existing inductive benchmarks. We also provide two strong baselines leveraging recently proposed inductive methods. We hope this challenge helps to streamline community efforts in the inductive graph representation learning area. ILPC 2022 follows best practices on evaluation fairness and reproducibility, and is available at https://github.com/pykeen/ilpc2022.
On the Generalization of Agricultural Drought Classification from Climate Data
Nov 30, 2021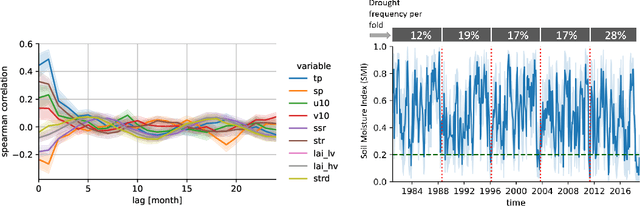
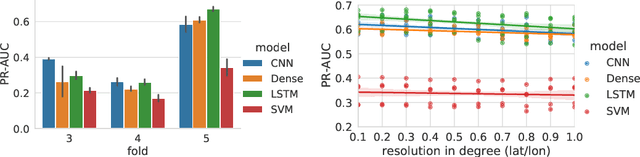
Climate change is expected to increase the likelihood of drought events, with severe implications for food security. Unlike other natural disasters, droughts have a slow onset and depend on various external factors, making drought detection in climate data difficult. In contrast to existing works that rely on simple relative drought indices as ground-truth data, we build upon soil moisture index (SMI) obtained from a hydrological model. This index is directly related to insufficiently available water to vegetation. Given ERA5-Land climate input data of six months with land use information from MODIS satellite observation, we compare different models with and without sequential inductive bias in classifying droughts based on SMI. We use PR-AUC as the evaluation measure to account for the class imbalance and obtain promising results despite a challenging time-based split. We further show in an ablation study that the models retain their predictive capabilities given input data of coarser resolutions, as frequently encountered in climate models.
Improving Inductive Link Prediction Using Hyper-Relational Facts
Jul 10, 2021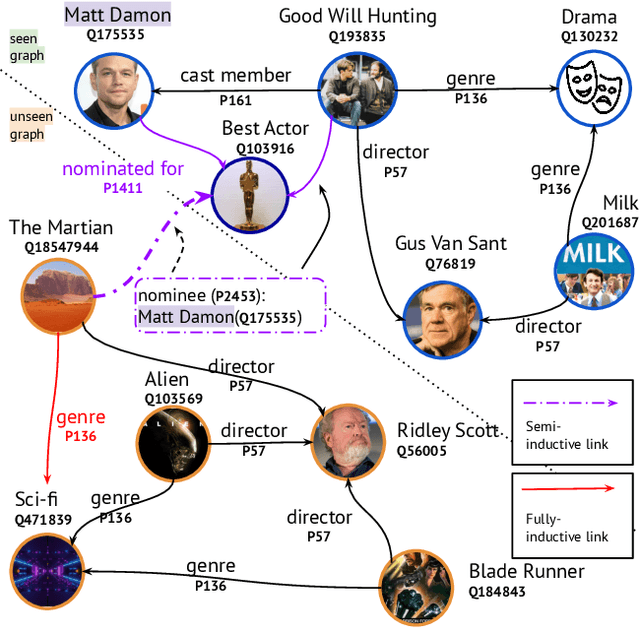

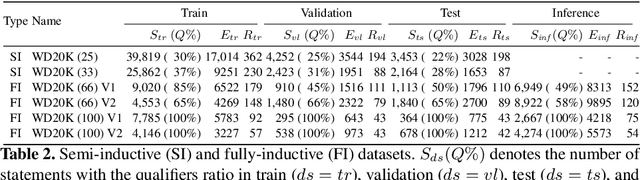
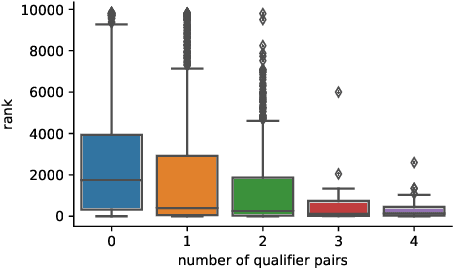
For many years, link prediction on knowledge graphs (KGs) has been a purely transductive task, not allowing for reasoning on unseen entities. Recently, increasing efforts are put into exploring semi- and fully inductive scenarios, enabling inference over unseen and emerging entities. Still, all these approaches only consider triple-based \glspl{kg}, whereas their richer counterparts, hyper-relational KGs (e.g., Wikidata), have not yet been properly studied. In this work, we classify different inductive settings and study the benefits of employing hyper-relational KGs on a wide range of semi- and fully inductive link prediction tasks powered by recent advancements in graph neural networks. Our experiments on a novel set of benchmarks show that qualifiers over typed edges can lead to performance improvements of 6% of absolute gains (for the Hits@10 metric) compared to triple-only baselines. Our code is available at \url{https://github.com/mali-git/hyper_relational_ilp}.
Query Embedding on Hyper-relational Knowledge Graphs
Jun 17, 2021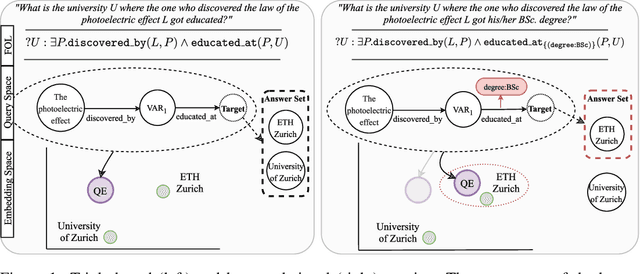
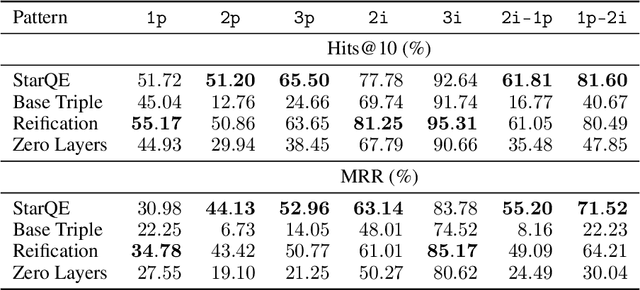

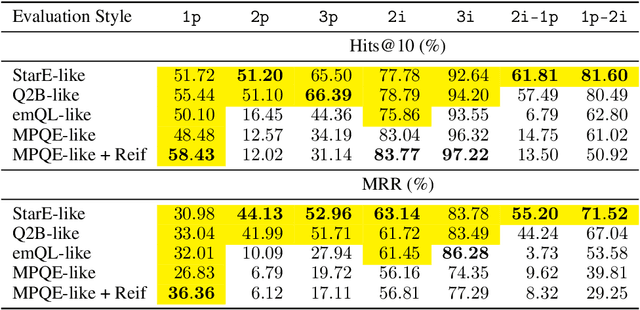
Multi-hop logical reasoning is an established problem in the field of representation learning on knowledge graphs (KGs). It subsumes both one-hop link prediction as well as other more complex types of logical queries. Existing algorithms operate only on classical, triple-based graphs, whereas modern KGs often employ a hyper-relational modeling paradigm. In this paradigm, typed edges may have several key-value pairs known as qualifiers that provide fine-grained context for facts. In queries, this context modifies the meaning of relations, and usually reduces the answer set. Hyper-relational queries are often observed in real-world KG applications, and existing approaches for approximate query answering cannot make use of qualifier pairs. In this work, we bridge this gap and extend the multi-hop reasoning problem to hyper-relational KGs allowing to tackle this new type of complex queries. Building upon recent advancements in Graph Neural Networks and query embedding techniques, we study how to embed and answer hyper-relational conjunctive queries. Besides that, we propose a method to answer such queries and demonstrate in our experiments that qualifiers improve query answering on a diverse set of query patterns.
Prediction of soft proton intensities in the near-Earth space using machine learning
May 11, 2021
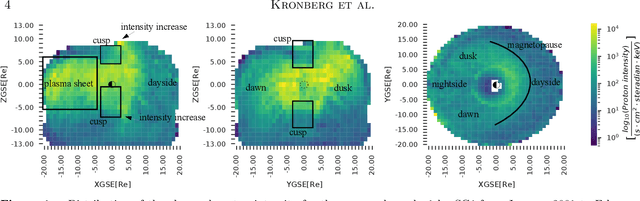
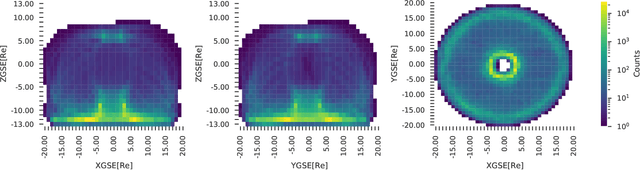

The spatial distribution of energetic protons contributes towards the understanding of magnetospheric dynamics. Based upon 17 years of the Cluster/RAPID observations, we have derived machine learning-based models to predict the proton intensities at energies from 28 to 1,885 keV in the 3D terrestrial magnetosphere at radial distances between 6 and 22 RE. We used the satellite location and indices for solar, solar wind and geomagnetic activity as predictors. The results demonstrate that the neural network (multi-layer perceptron regressor) outperforms baseline models based on the k-Nearest Neighbors and historical binning on average by ~80% and ~33\%, respectively. The average correlation between the observed and predicted data is about 56%, which is reasonable in light of the complex dynamics of fast-moving energetic protons in the magnetosphere. In addition to a quantitative analysis of the prediction results, we also investigate parameter importance in our model. The most decisive parameters for predicting proton intensities are related to the location: ZGSE direction and the radial distance. Among the activity indices, the solar wind dynamic pressure is the most important. The results have a direct practical application, for instance, for assessing the contamination particle background in the X-Ray telescopes for X-ray astronomy orbiting above the radiation belts. To foster reproducible research and to enable the community to build upon our work we publish our complete code, the data, as well as weights of trained models. Further description can be found in the GitHub project at https://github.com/Tanveer81/deep_horizon.
Argument Mining Driven Analysis of Peer-Reviews
Dec 10, 2020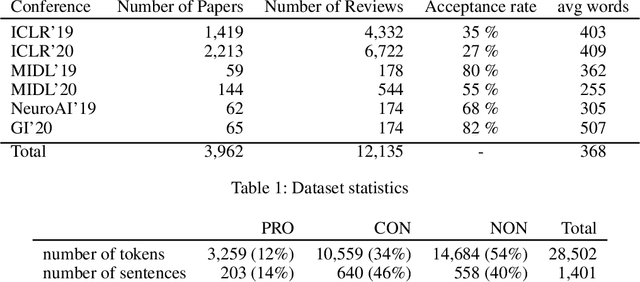
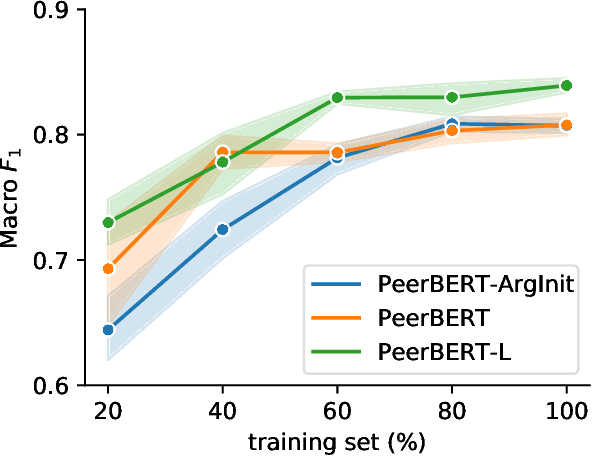

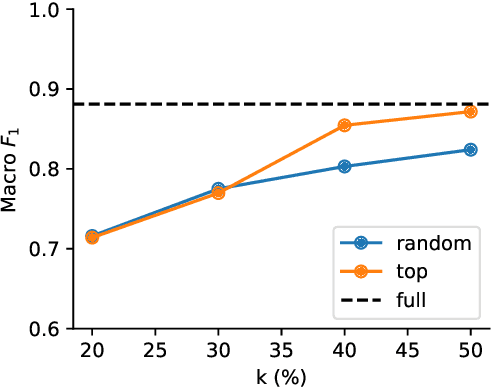
Peer reviewing is a central process in modern research and essential for ensuring high quality and reliability of published work. At the same time, it is a time-consuming process and increasing interest in emerging fields often results in a high review workload, especially for senior researchers in this area. How to cope with this problem is an open question and it is vividly discussed across all major conferences. In this work, we propose an Argument Mining based approach for the assistance of editors, meta-reviewers, and reviewers. We demonstrate that the decision process in the field of scientific publications is driven by arguments and automatic argument identification is helpful in various use-cases. One of our findings is that arguments used in the peer-review process differ from arguments in other domains making the transfer of pre-trained models difficult. Therefore, we provide the community with a new peer-review dataset from different computer science conferences with annotated arguments. In our extensive empirical evaluation, we show that Argument Mining can be used to efficiently extract the most relevant parts from reviews, which are paramount for the publication decision. The process remains interpretable since the extracted arguments can be highlighted in a review without detaching them from their context.
A Critical Assessment of State-of-the-Art in Entity Alignment
Oct 30, 2020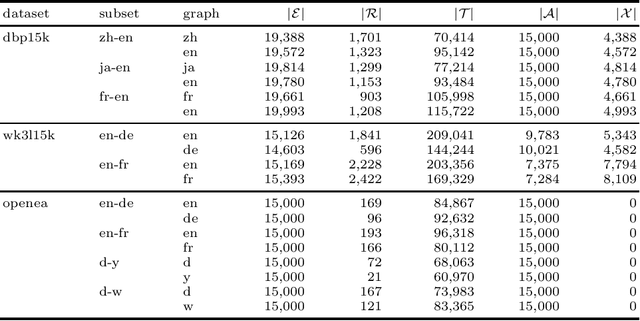

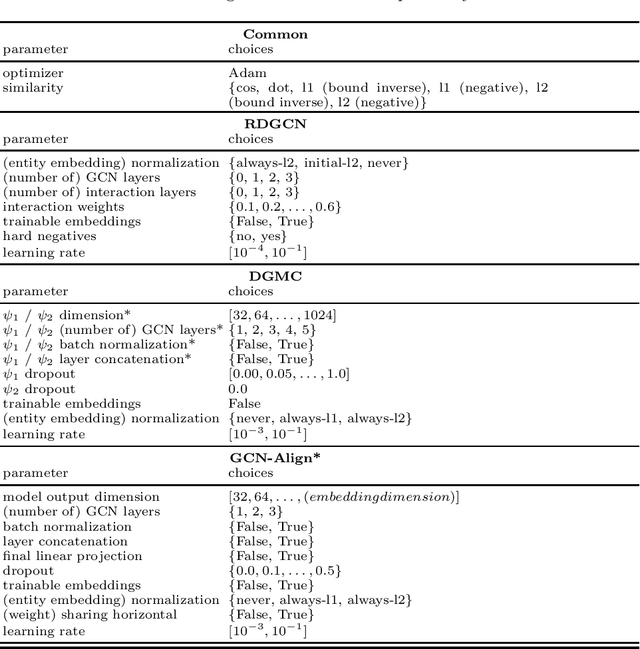
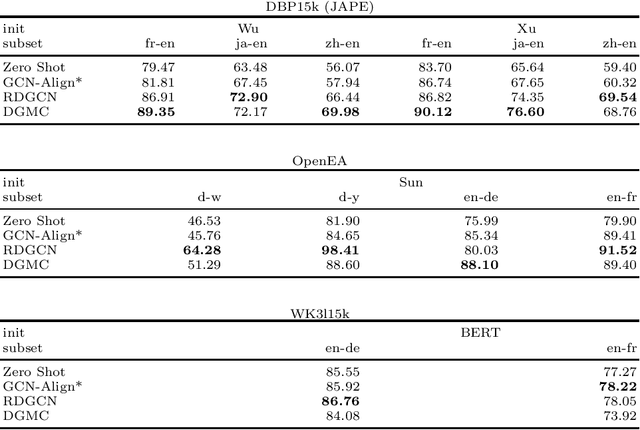
In this work, we perform an extensive investigation of two state-of-the-art (SotA) methods for the task of Entity Alignment in Knowledge Graphs. Therefore, we first carefully examine the benchmarking process and identify several shortcomings, which make the results reported in the original works not always comparable. Furthermore, we suspect that it is a common practice in the community to make the hyperparameter optimization directly on a test set, reducing the informative value of reported performance. Thus, we select a representative sample of benchmarking datasets and describe their properties. We also examine different initializations for entity representations since they are a decisive factor for model performance. Furthermore, we use a shared train/validation/test split for a fair evaluation setting in which we evaluate all methods on all datasets. In our evaluation, we make several interesting findings. While we observe that most of the time SotA approaches perform better than baselines, they have difficulties when the dataset contains noise, which is the case in most real-life applications. Moreover, we find out in our ablation study that often different features of SotA methods are crucial for good performance than previously assumed. The code is available at https://github.com/mberr/ea-sota-comparison.