 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ARC of Progress towards AGI: A Living Survey of Abstraction and Reasoning
Mar 09, 2026The Abstraction and Reasoning Corpus (ARC-AGI) has become a key benchmark for fluid intelligence in AI. This survey presents the first cross-generation analysis of 82 approaches across three benchmark versions and the ARC Prize 2024-2025 competitions. Our central finding is that performance degradation across versions is consistent across all paradigms: program synthesis, neuro-symbolic, and neural approaches all exhibit 2-3x drops from ARC-AGI-1 to ARC-AGI-2, indicating fundamental limitations in compositional generalization. While systems now reach 93.0% on ARC-AGI-1 (Opus 4.6), performance falls to 68.8% on ARC-AGI-2 and 13% on ARC-AGI-3, as humans maintain near-perfect accuracy across all versions. Cost fell 390x in one year (o3's $4,500/task to GPT-5.2's $12/task), although this largely reflects reduced test-time parallelism. Trillion-scale models vary widely in score and cost, while Kaggle-constrained entries (660M-8B) achieve competitive results, aligning with Chollet's thesis that intelligence is skill-acquisition efficiency. Test-time adaptation and refinement loops emerge as critical success factors, while compositional reasoning and interactive learning remain unsolved. ARC Prize 2025 winners needed hundreds of thousands of synthetic examples to reach 24% on ARC-AGI-2, confirming that reasoning remains knowledge-bound. This first release of the ARC-AGI Living Survey captures the field as of February 2026, with updates at https://nimi-ai.com/arc-survey/
ARC-TGI: Human-Validated Task Generators with Reasoning Chain Templates for ARC-AGI
Mar 05, 2026The Abstraction and Reasoning Corpus (ARC-AGI) probes few-shot abstraction and rule induction on small visual grids, but progress is difficult to measure on static collections of hand-authored puzzles due to overfitting, dataset leakage, and memorisation. We introduce ARC-TGI (ARC Task Generators Inventory), an open-source framework for task-family generators: compact Python programs that sample diverse ARC-AGI tasks while preserving a latent rule. ARC-TGI is built around a solver-facing representation: each generated task is paired with natural-language input and transformation reasoning chains and partially evaluated Python code implementing sampling, transformation, and episode construction. Crucially, ARC-TGI supports task-level constraints so that training examples collectively expose the variations needed to infer the underlying rule, a requirement for human-solvable ARC tasks that independent per-example sampling often fails to guarantee. All generators undergo human refinement and local verification to keep both grids and reasoning traces natural and consistent under variation. We release 461 generators covering 180 ARC-Mini tasks, 215 ARC-AGI-1 tasks (200 train, 15 test), and 66 ARC-AGI-2 tasks (55 train, 11 test), enabling scalable dataset sampling and controlled benchmarking.
ReFactX: Scalable Reasoning with Reliable Facts via Constrained Generation
Aug 23, 2025Knowledge gaps and hallucinations are persistent challenges for Large Language Models (LLMs), which generate unreliable responses when lacking the necessary information to fulfill user instructions. Existing approaches, such as Retrieval-Augmented Generation (RAG) and tool use, aim to address these issues by incorporating external knowledge. Yet, they rely on additional models or services, resulting in complex pipelines, potential error propagation, and often requiring the model to process a large number of tokens. In this paper, we present a scalable method that enables LLMs to access external knowledge without depending on retrievers or auxiliary models. Our approach uses constrained generation with a pre-built prefix-tree index. Triples from a Knowledge Graph are verbalized in textual facts, tokenized, and indexed in a prefix tree for efficient access. During inference, to acquire external knowledge, the LLM generates facts with constrained generation which allows only sequences of tokens that form an existing fact. We evaluate our proposal on Question Answering and show that it scales to large knowledge bases (800 million facts), adapts to domain-specific data, and achieves effective results. These gains come with minimal generation-time overhead. ReFactX code is available at https://github.com/rpo19/ReFactX.
SMART: Relation-Aware Learning of Geometric Representations for Knowledge Graphs
Jul 17, 2025Knowledge graph representation learning approaches provide a mapping between symbolic knowledge in the form of triples in a knowledge graph (KG) and their feature vectors. Knowledge graph embedding (KGE) models often represent relations in a KG as geometric transformations. Most state-of-the-art (SOTA) KGE models are derived from elementary geometric transformations (EGTs), such as translation, scaling, rotation, and reflection, or their combinations. These geometric transformations enable the models to effectively preserve specific structural and relational patterns of the KG. However, the current use of EGTs by KGEs remains insufficient without considering relation-specific transformations. Although recent models attempted to address this problem by ensembling SOTA baseline models in different ways, only a single or composite version of geometric transformations are used by such baselines to represent all the relations. In this paper, we propose a framework that evaluates how well each relation fits with different geometric transformations. Based on this ranking, the model can: (1) assign the best-matching transformation to each relation, or (2) use majority voting to choose one transformation type to apply across all relations. That is, the model learns a single relation-specific EGT in low dimensional vector space through an attention mechanism. Furthermore, we use the correlation between relations and EGTs, which are learned in a low dimension, for relation embeddings in a high dimensional vector space. The effectiveness of our models is demonstrated through comprehensive evaluations on three benchmark KGs as well as a real-world financial KG, witnessing a performance comparable to leading models
IntelliLung: Advancing Safe Mechanical Ventilation using Offline RL with Hybrid Actions and Clinically Aligned Rewards
Jun 17, 2025Invasive mechanical ventilation (MV) is a life-sustaining therapy for critically ill patients in the intensive care unit (ICU). However, optimizing its settings remains a complex and error-prone process due to patient-specific variability. While Offline Reinforcement Learning (RL) shows promise for MV control, current stateof-the-art (SOTA) methods struggle with the hybrid (continuous and discrete) nature of MV actions. Discretizing the action space limits available actions due to exponential growth in combinations and introduces distribution shifts that can compromise safety. In this paper, we propose optimizations that build upon prior work in action space reduction to address the challenges of discrete action spaces. We also adapt SOTA offline RL algorithms (IQL and EDAC) to operate directly on hybrid action spaces, thereby avoiding the pitfalls of discretization. Additionally, we introduce a clinically grounded reward function based on ventilator-free days and physiological targets, which provides a more meaningful optimization objective compared to traditional sparse mortality-based rewards. Our findings demonstrate that AI-assisted MV optimization may enhance patient safety and enable individualized lung support, representing a significant advancement toward intelligent, data-driven critical care solutions.
BanglaQuAD: A Bengali Open-domain Question Answering Dataset
Oct 14, 2024Bengali is the seventh most spoken language on earth, yet considered a low-resource language in the field of natural language processing (NLP). Question answering over unstructured text is a challenging NLP task as it requires understanding both question and passage. Very few researchers attempted to perform question answering over Bengali (natively pronounced as Bangla) text. Typically, existing approaches construct the dataset by directly translating them from English to Bengali, which produces noisy and improper sentence structures. Furthermore, they lack topics and terminologies related to the Bengali language and people. This paper introduces BanglaQuAD, a Bengali question answering dataset, containing 30,808 question-answer pairs constructed from Bengali Wikipedia articles by native speakers. Additionally, we propose an annotation tool that facilitates question-answering dataset construction on a local machine. A qualitative analysis demonstrates the quality of our proposed dataset.
MATTER: Memory-Augmented Transformer Using Heterogeneous Knowledge Sources
Jun 07, 2024



Leveraging external knowledge is crucial for achieving high performance in knowledge-intensive tasks, such as question answering. The retrieve-and-read approach is widely adopted for integrating external knowledge into a language model. However, this approach suffers from increased computational cost and latency due to the long context length, which grows proportionally with the number of retrieved knowledge. Furthermore, existing retrieval-augmented models typically retrieve information from a single type of knowledge source, limiting their scalability to diverse knowledge sources with varying structures. In this work, we introduce an efficient memory-augmented transformer called MATTER, designed to retrieve relevant knowledge from multiple heterogeneous knowledge sources. Specifically, our model retrieves and reads from both unstructured sources (paragraphs) and semi-structured sources (QA pairs) in the form of fixed-length neural memories. We demonstrate that our model outperforms existing efficient retrieval-augmented models on popular QA benchmarks in terms of both accuracy and speed. Furthermore, MATTER achieves competitive results compared to conventional read-and-retrieve models while having 100x throughput during inference.
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
May 04, 2024Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
REXEL: An End-to-end Model for Document-Level Relation Extraction and Entity Linking
Apr 19, 2024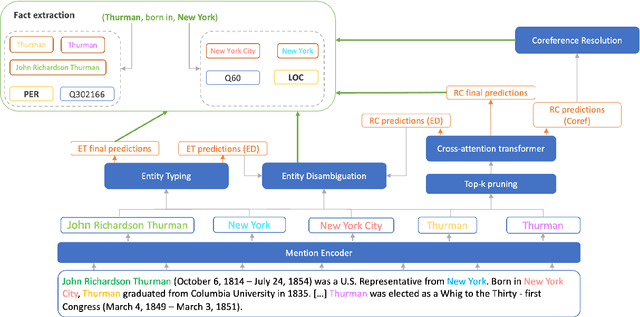
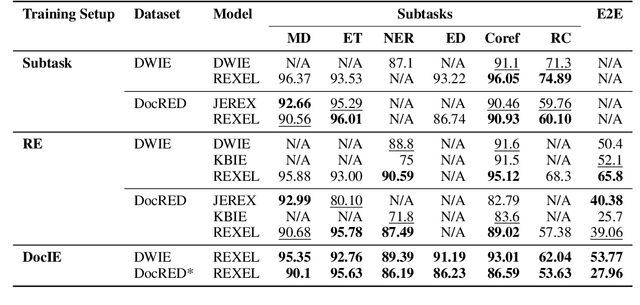
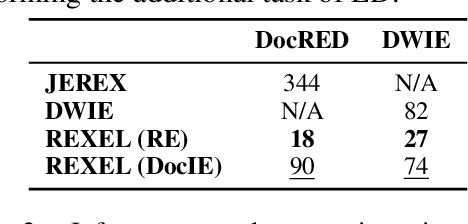
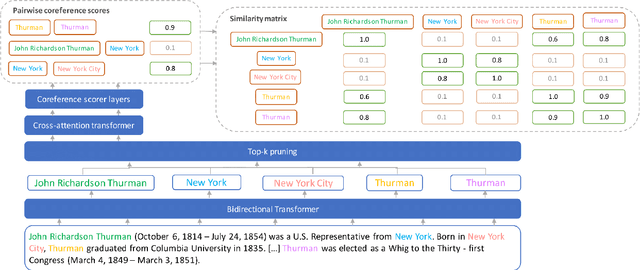
Extracting structured information from unstructured text is critical for many downstream NLP applications and is traditionally achieved by closed information extraction (cIE). However, existing approaches for cIE suffer from two limitations: (i) they are often pipelines which makes them prone to error propagation, and/or (ii) they are restricted to sentence level which prevents them from capturing long-range dependencies and results in expensive inference time. We address these limitations by proposing REXEL, a highly efficient and accurate model for the joint task of document level cIE (DocIE). REXEL performs mention detection, entity typing, entity disambiguation, coreference resolution and document-level relation classification in a single forward pass to yield facts fully linked to a reference knowledge graph. It is on average 11 times faster than competitive existing approaches in a similar setting and performs competitively both when optimised for any of the individual subtasks and a variety of combinations of different joint tasks, surpassing the baselines by an average of more than 6 F1 points. The combination of speed and accuracy makes REXEL an accurate cost-efficient system for extracting structured information at web-scale. We also release an extension of the DocRED dataset to enable benchmarking of future work on DocIE, which is available at https://github.com/amazon-science/e2e-docie.
Investigating Multilingual Instruction-Tuning: Do Polyglot Models Demand for Multilingual Instructions?
Feb 21, 2024The adaption of multilingual pre-trained Large Language Models (LLMs) into eloquent and helpful assistants is essential to facilitate their use across different language regions. In that spirit, we are the first to conduct an extensive study of the performance of multilingual models on parallel, multi-turn instruction-tuning benchmarks across a selection of the most-spoken Indo-European languages. We systematically examine the effects of language and instruction dataset size on a mid-sized, multilingual LLM by instruction-tuning it on parallel instruction-tuning datasets. Our results demonstrate that instruction-tuning on parallel instead of monolingual corpora benefits cross-lingual instruction following capabilities by up to 4.6%. Furthermore, we show that the Superficial Alignment Hypothesis does not hold in general, as the investigated multilingual 7B parameter model presents a counter-example requiring large-scale instruction-tuning datasets. Finally, we conduct a human annotation study to understand the alignment between human-based and GPT-4-based evaluation within multilingual chat scenarios.