 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference Gap in Domain Expertise and Machine Intelligence in Named Entity Recognition: Creation of and Insights from a Substance Use-related Dataset
Aug 26, 2025Nonmedical opioid use is an urgent public health challenge, with far-reaching clinical and social consequences that are often underreported in traditional healthcare settings. Social media platforms, where individuals candidly share first-person experiences, offer a valuable yet underutilized source of insight into these impacts. In this study, we present a named entity recognition (NER) framework to extract two categories of self-reported consequences from social media narratives related to opioid use: ClinicalImpacts (e.g., withdrawal, depression) and SocialImpacts (e.g., job loss). To support this task, we introduce RedditImpacts 2.0, a high-quality dataset with refined annotation guidelines and a focus on first-person disclosures, addressing key limitations of prior work. We evaluate both fine-tuned encoder-based models and state-of-the-art large language models (LLMs) under zero- and few-shot in-context learning settings. Our fine-tuned DeBERTa-large model achieves a relaxed token-level F1 of 0.61 [95% CI: 0.43-0.62], consistently outperforming LLMs in precision, span accuracy, and adherence to task-specific guidelines. Furthermore, we show that strong NER performance can be achieved with substantially less labeled data, emphasizing the feasibility of deploying robust models in resource-limited settings. Our findings underscore the value of domain-specific fine-tuning for clinical NLP tasks and contribute to the responsible development of AI tools that may enhance addiction surveillance, improve interpretability, and support real-world healthcare decision-making. The best performing model, however, still significantly underperforms compared to inter-expert agreement (Cohen's kappa: 0.81), demonstrating that a gap persists between expert intelligence and current state-of-the-art NER/AI capabilities for tasks requiring deep domain knowledge.
BanglaQuAD: A Bengali Open-domain Question Answering Dataset
Oct 14, 2024Bengali is the seventh most spoken language on earth, yet considered a low-resource language in the field of natural language processing (NLP). Question answering over unstructured text is a challenging NLP task as it requires understanding both question and passage. Very few researchers attempted to perform question answering over Bengali (natively pronounced as Bangla) text. Typically, existing approaches construct the dataset by directly translating them from English to Bengali, which produces noisy and improper sentence structures. Furthermore, they lack topics and terminologies related to the Bengali language and people. This paper introduces BanglaQuAD, a Bengali question answering dataset, containing 30,808 question-answer pairs constructed from Bengali Wikipedia articles by native speakers. Additionally, we propose an annotation tool that facilitates question-answering dataset construction on a local machine. A qualitative analysis demonstrates the quality of our proposed dataset.
Multimodal Hate Speech Detection from Bengali Memes and Texts
Apr 19, 2022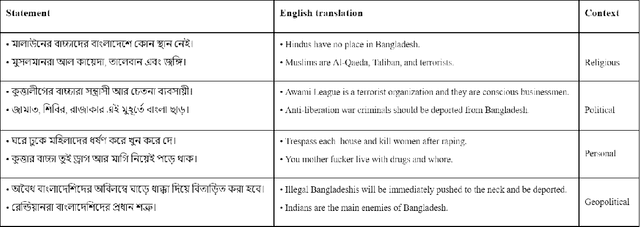
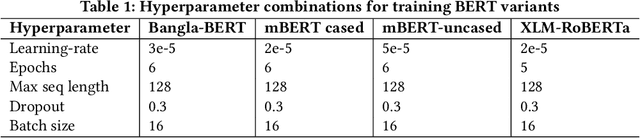
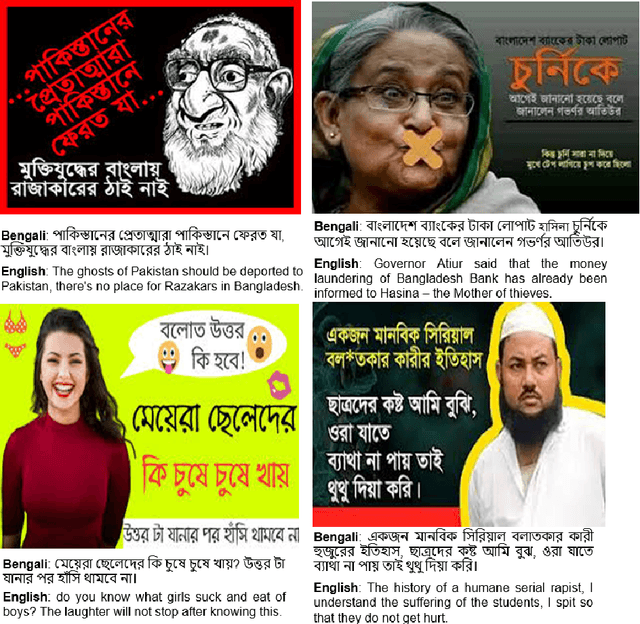
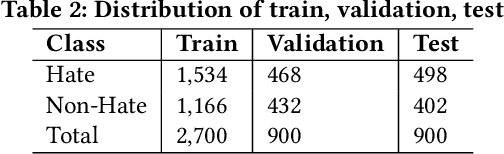
Numerous works have been proposed to employ machine learning (ML) and deep learning (DL) techniques to utilize textual data from social media for anti-social behavior analysis such as cyberbullying, fake news propagation, and hate speech mainly for highly resourced languages like English. However, despite having a lot of diversity and millions of native speakers, some languages such as Bengali are under-resourced, which is due to a lack of computational resources for natural language processing (NLP). Like English, Bengali social media content also includes images along with texts (e.g., multimodal contents are posted by embedding short texts into images on Facebook), only the textual data is not enough to judge them (e.g., to determine they are hate speech). In those cases, images might give extra context to properly judge. This paper is about hate speech detection from multimodal Bengali memes and texts. We prepared the only multimodal hate speech detection dataset1 for a kind of problem for Bengali. We train several neural architectures (i.e., neural networks like Bi-LSTM/Conv-LSTM with word embeddings, EfficientNet + transformer architectures such as monolingual Bangla BERT, multilingual BERT-cased/uncased, and XLM-RoBERTa) jointly analyze textual and visual information for hate speech detection. The Conv-LSTM and XLM-RoBERTa models performed best for texts, yielding F1 scores of 0.78 and 0.82, respectively. As of memes, ResNet152 and DenseNet201 models yield F1 scores of 0.78 and 0.7, respectively. The multimodal fusion of mBERT-uncased + EfficientNet-B1 performed the best, yielding an F1 score of 0.80. Our study suggests that memes are moderately useful for hate speech detection in Bengali, but none of the multimodal models outperform unimodal models analyzing only textual data.
DeepHateExplainer: Explainable Hate Speech Detection in Under-resourced Bengali Language
Dec 28, 2020


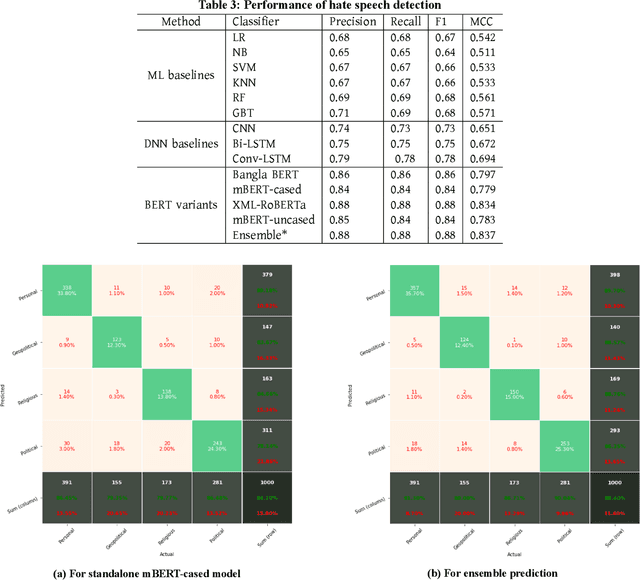
Exponential growths of social media and micro-blogging sites not only provide platforms for empowering freedom of expressions and individual voices, but also enables people to express anti-social behavior like online harassment, cyberbullying, and hate speech. Numerous works have been proposed to utilize these data for social and anti-social behavior analysis, by predicting the contexts mostly for highly-resourced languages like English. However, some languages such as Bengali are under-resourced that lack of computational resources for natural language processing(NLP). In this paper, we propose an explainable approach for hate speech detection from under-resourced Bengali language, which we called DeepHateExplainer. In our approach, Bengali texts are first comprehensively preprocessed, before classifying them into political, personal, geopolitical, and religious hates, by employing neural ensemble of different transformer-based neural architectures(i.e., monolingual Bangla BERT-base, multilingual BERT-cased and uncased, and XLM-RoBERTa), followed by identifying important terms with sensitivity analysis and layer-wise relevance propagation(LRP) to provide human-interpretable explanations. Evaluations against several machine learning~(linear and tree-based models) and deep neural networks (i.e., CNN, Bi-LSTM, and Conv-LSTM with word embeddings) baselines yield F1 scores of 84%, 90%, 88%, and 88%, for political, personal, geopolitical, and religious hates, respectively, during 3-fold cross-validation tests.