 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen-NAS: A Global-Scale Multi-Objective Neural Architecture Search for Robust and Efficient Edge-Native Weather Forecasting
Jan 30, 2026We introduce Green-NAS, a multi-objective NAS (neural architecture search) framework designed for low-resource environments using weather forecasting as a case study. By adhering to 'Green AI' principles, the framework explicitly minimizes computational energy costs and carbon footprints, prioritizing sustainable deployment over raw computational scale. The Green-NAS architecture search method is optimized for both model accuracy and efficiency to find lightweight models with high accuracy and very few model parameters; this is accomplished through an optimization process that simultaneously optimizes multiple objectives. Our best-performing model, Green-NAS-A, achieved an RMSE of 0.0988 (i.e., within 1.4% of our manually tuned baseline) using only 153k model parameters, which is 239 times fewer than other globally applied weather forecasting models, such as GraphCast. In addition, we also describe how the use of transfer learning will improve the weather forecasting accuracy by approximately 5.2%, in comparison to a naive approach of training a new model for each city, when there is limited historical weather data available for that city.
Unveiling Black-boxes: Explainable Deep Learning Models for Patent Classification
Oct 31, 2023Recent technological advancements have led to a large number of patents in a diverse range of domains, making it challenging for human experts to analyze and manage. State-of-the-art methods for multi-label patent classification rely on deep neural networks (DNNs), which are complex and often considered black-boxes due to their opaque decision-making processes. In this paper, we propose a novel deep explainable patent classification framework by introducing layer-wise relevance propagation (LRP) to provide human-understandable explanations for predictions. We train several DNN models, including Bi-LSTM, CNN, and CNN-BiLSTM, and propagate the predictions backward from the output layer up to the input layer of the model to identify the relevance of words for individual predictions. Considering the relevance score, we then generate explanations by visualizing relevant words for the predicted patent class. Experimental results on two datasets comprising two-million patent texts demonstrate high performance in terms of various evaluation measures. The explanations generated for each prediction highlight important relevant words that align with the predicted class, making the prediction more understandable. Explainable systems have the potential to facilitate the adoption of complex AI-enabled methods for patent classification in real-world applications.
From Large Language Models to Knowledge Graphs for Biomarker Discovery in Cancer
Oct 12, 2023Domain experts often rely on up-to-date knowledge for apprehending and disseminating specific biological processes that help them design strategies to develop prevention and therapeutic decision-making. A challenging scenario for artificial intelligence (AI) is using biomedical data (e.g., texts, imaging, omics, and clinical) to provide diagnosis and treatment recommendations for cancerous conditions. Data and knowledge about cancer, drugs, genes, proteins, and their mechanism is spread across structured (knowledge bases (KBs)) and unstructured (e.g., scientific articles) sources. A large-scale knowledge graph (KG) can be constructed by integrating these data, followed by extracting facts about semantically interrelated entities and relations. Such KGs not only allow exploration and question answering (QA) but also allow domain experts to deduce new knowledge. However, exploring and querying large-scale KGs is tedious for non-domain users due to a lack of understanding of the underlying data assets and semantic technologies. In this paper, we develop a domain KG to leverage cancer-specific biomarker discovery and interactive QA. For this, a domain ontology called OncoNet Ontology (ONO) is developed to enable semantic reasoning for validating gene-disease relations. The KG is then enriched by harmonizing the ONO, controlled vocabularies, and additional biomedical concepts from scientific articles by employing BioBERT- and SciBERT-based information extraction (IE) methods. Further, since the biomedical domain is evolving, where new findings often replace old ones, without employing up-to-date findings, there is a high chance an AI system exhibits concept drift while providing diagnosis and treatment. Therefore, we finetuned the KG using large language models (LLMs) based on more recent articles and KBs that might not have been seen by the named entity recognition models.
Catch Me If You Can: Semi-supervised Graph Learning for Spotting Money Laundering
Feb 24, 2023



Money laundering is the process where criminals use financial services to move massive amounts of illegal money to untraceable destinations and integrate them into legitimate financial systems. It is very crucial to identify such activities accurately and reliably in order to enforce an anti-money laundering (AML). Despite tremendous efforts to AML only a tiny fraction of illicit activities are prevented. From a given graph of money transfers between accounts of a bank, existing approaches attempted to detect money laundering. In particular, some approaches employ structural and behavioural dynamics of dense subgraph detection thereby not taking into consideration that money laundering involves high-volume flows of funds through chains of bank accounts. Some approaches model the transactions in the form of multipartite graphs to detect the complete flow of money from source to destination. However, existing approaches yield lower detection accuracy, making them less reliable. In this paper, we employ semi-supervised graph learning techniques on graphs of financial transactions in order to identify nodes involved in potential money laundering. Experimental results suggest that our approach can sport money laundering from real and synthetic transaction graphs.
A Biomedical Knowledge Graph for Biomarker Discovery in Cancer
Feb 23, 2023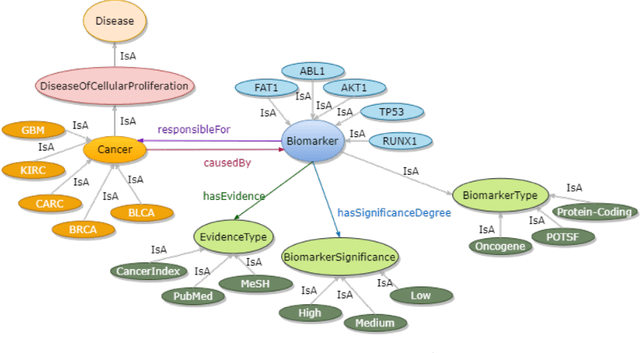
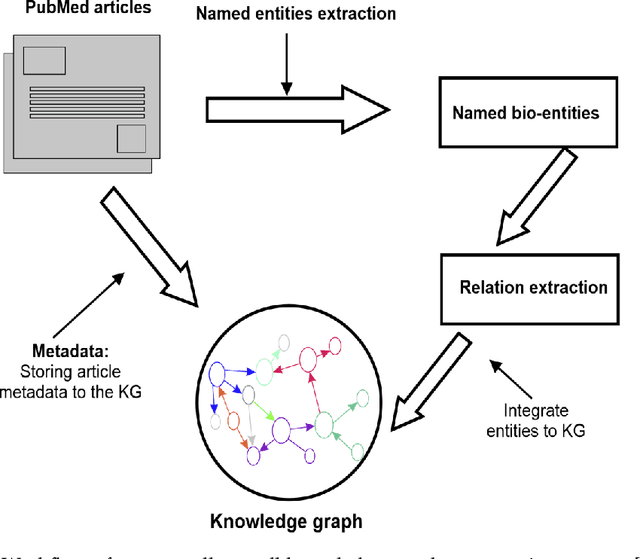

Structured and unstructured data and facts about drugs, genes, protein, viruses, and their mechanism are spread across a huge number of scientific articles. These articles are a large-scale knowledge source and can have a huge impact on disseminating knowledge about the mechanisms of certain biological processes. A domain-specific knowledge graph~(KG) is an explicit conceptualization of a specific subject-matter domain represented w.r.t semantically interrelated entities and relations. A KG can be constructed by integrating such facts and data and be used for data integration, exploration, and federated queries. However, exploration and querying large-scale KGs is tedious for certain groups of users due to a lack of knowledge about underlying data assets or semantic technologies. Such a KG will not only allow deducing new knowledge and question answering(QA) but also allows domain experts to explore. Since cross-disciplinary explanations are important for accurate diagnosis, it is important to query the KG to provide interactive explanations about learned biomarkers. Inspired by these, we construct a domain-specific KG, particularly for cancer-specific biomarker discovery. The KG is constructed by integrating cancer-related knowledge and facts from multiple sources. First, we construct a domain-specific ontology, which we call OncoNet Ontology (ONO). The ONO ontology is developed to enable semantic reasoning for verification of the predictions for relations between diseases and genes. The KG is then developed and enriched by harmonizing the ONO, additional metadata schemas, ontologies, controlled vocabularies, and additional concepts from external sources using a BERT-based information extraction method. BioBERT and SciBERT are finetuned with the selected articles crawled from PubMed. We listed down some queries and some examples of QA and deducing knowledge based on the KG.
Explainable AI for Bioinformatics: Methods, Tools, and Applications
Dec 25, 2022Artificial intelligence(AI) systems based on deep neural networks (DNNs) and machine learning (ML) algorithms are increasingly used to solve critical problems in bioinformatics, biomedical informatics, and precision medicine. However, complex DNN or ML models that are unavoidably opaque and perceived as black-box methods, may not be able to explain why and how they make certain decisions. Such black-box models are difficult to comprehend not only for targeted users and decision-makers but also for AI developers. Besides, in sensitive areas like healthcare, explainability and accountability are not only desirable properties of AI but also legal requirements -- especially when AI may have significant impacts on human lives. Explainable artificial intelligence (XAI) is an emerging field that aims to mitigate the opaqueness of black-box models and make it possible to interpret how AI systems make their decisions with transparency. An interpretable ML model can explain how it makes predictions and which factors affect the model's outcomes. The majority of state-of-the-art interpretable ML methods have been developed in a domain-agnostic way and originate from computer vision, automated reasoning, or even statistics. Many of these methods cannot be directly applied to bioinformatics problems, without prior customization, extension, and domain adoption. In this paper, we discuss the importance of explainability with a focus on bioinformatics. We analyse and comprehensively overview of model-specific and model-agnostic interpretable ML methods and tools. Via several case studies covering bioimaging, cancer genomics, and biomedical text mining, we show how bioinformatics research could benefit from XAI methods and how they could help improve decision fairness.
Question Answering Over Biological Knowledge Graph via Amazon Alexa
Oct 12, 2022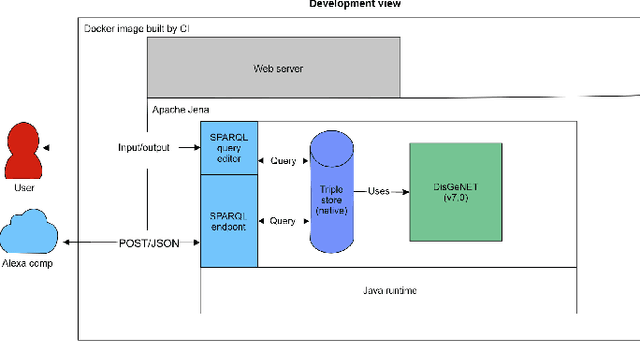
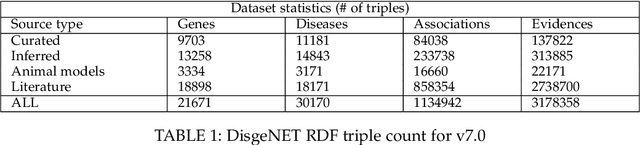
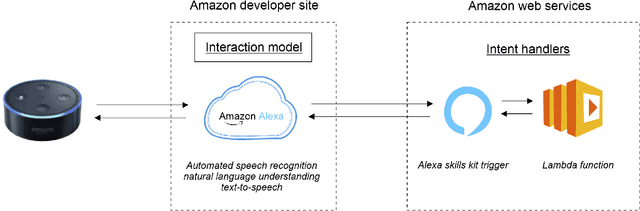
Structured and unstructured data and facts about drugs, genes, protein, viruses, and their mechanism are spread across a huge number of scientific articles. These articles are a large-scale knowledge source and can have a huge impact on disseminating knowledge about the mechanisms of certain biological processes. A knowledge graph (KG) can be constructed by integrating such facts and data and be used for data integration, exploration, and federated queries. However, exploration and querying large-scale KGs is tedious for certain groups of users due to a lack of knowledge about underlying data assets or semantic technologies. A question-answering (QA) system allows the answer of natural language questions over KGs automatically using triples contained in a KG. Recently, the use and adaption of digital assistants are getting wider owing to their capability at enabling users to voice commands to control smart systems or devices. This paper is about using Amazon Alexa's voice-enabled interface for QA over KGs. As a proof-of-concept, we use the well-known DisgeNET KG, which contains knowledge covering 1.13 million gene-disease associations between 21,671 genes and 30,170 diseases, disorders, and clinical or abnormal human phenotypes. Our study shows how Alex could be of help to find facts about certain biological entities from large-scale knowledge bases.
Interpreting Black-box Machine Learning Models for High Dimensional Datasets
Aug 29, 2022
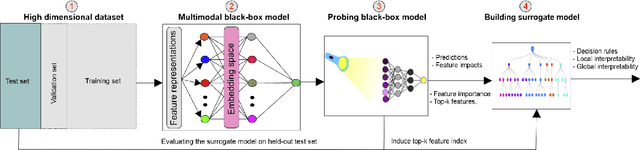


Deep neural networks (DNNs) have been shown to outperform traditional machine learning algorithms in a broad variety of application domains due to their effectiveness in modeling intricate problems and handling high-dimensional datasets. Many real-life datasets, however, are of increasingly high dimensionality, where a large number of features may be irrelevant to the task at hand. The inclusion of such features would not only introduce unwanted noise but also increase computational complexity. Furthermore, due to high non-linearity and dependency among a large number of features, DNN models tend to be unavoidably opaque and perceived as black-box methods because of their not well-understood internal functioning. A well-interpretable model can identify statistically significant features and explain the way they affect the model's outcome. In this paper, we propose an efficient method to improve the interpretability of black-box models for classification tasks in the case of high-dimensional datasets. To this end, we first train a black-box model on a high-dimensional dataset to learn the embeddings on which the classification is performed. To decompose the inner working principles of the black-box model and to identify top-k important features, we employ different probing and perturbing techniques. We then approximate the behavior of the black-box model by means of an interpretable surrogate model on the top-k feature space. Finally, we derive decision rules and local explanations from the surrogate model to explain individual decisions. Our approach outperforms and competes with state-of-the-art methods such as TabNet, XGboost, and SHAP-based interpretability techniques when tested on different datasets with varying dimensionality between 50 and 20,000.
Multimodal Hate Speech Detection from Bengali Memes and Texts
Apr 19, 2022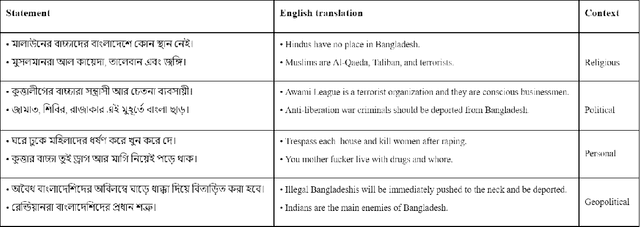
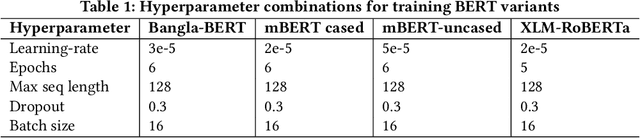
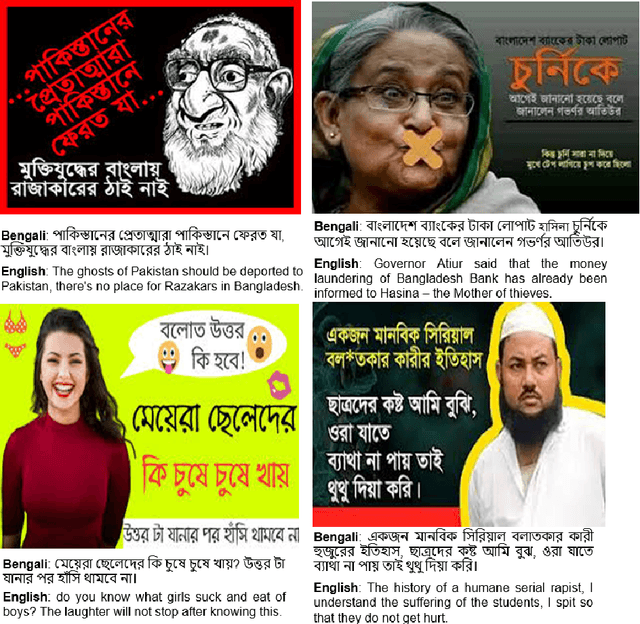
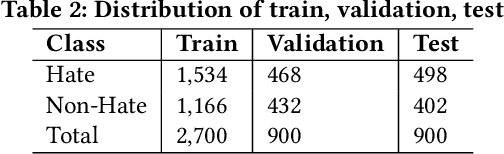
Numerous works have been proposed to employ machine learning (ML) and deep learning (DL) techniques to utilize textual data from social media for anti-social behavior analysis such as cyberbullying, fake news propagation, and hate speech mainly for highly resourced languages like English. However, despite having a lot of diversity and millions of native speakers, some languages such as Bengali are under-resourced, which is due to a lack of computational resources for natural language processing (NLP). Like English, Bengali social media content also includes images along with texts (e.g., multimodal contents are posted by embedding short texts into images on Facebook), only the textual data is not enough to judge them (e.g., to determine they are hate speech). In those cases, images might give extra context to properly judge. This paper is about hate speech detection from multimodal Bengali memes and texts. We prepared the only multimodal hate speech detection dataset1 for a kind of problem for Bengali. We train several neural architectures (i.e., neural networks like Bi-LSTM/Conv-LSTM with word embeddings, EfficientNet + transformer architectures such as monolingual Bangla BERT, multilingual BERT-cased/uncased, and XLM-RoBERTa) jointly analyze textual and visual information for hate speech detection. The Conv-LSTM and XLM-RoBERTa models performed best for texts, yielding F1 scores of 0.78 and 0.82, respectively. As of memes, ResNet152 and DenseNet201 models yield F1 scores of 0.78 and 0.7, respectively. The multimodal fusion of mBERT-uncased + EfficientNet-B1 performed the best, yielding an F1 score of 0.80. Our study suggests that memes are moderately useful for hate speech detection in Bengali, but none of the multimodal models outperform unimodal models analyzing only textual data.
DeepHateExplainer: Explainable Hate Speech Detection in Under-resourced Bengali Language
Dec 28, 2020


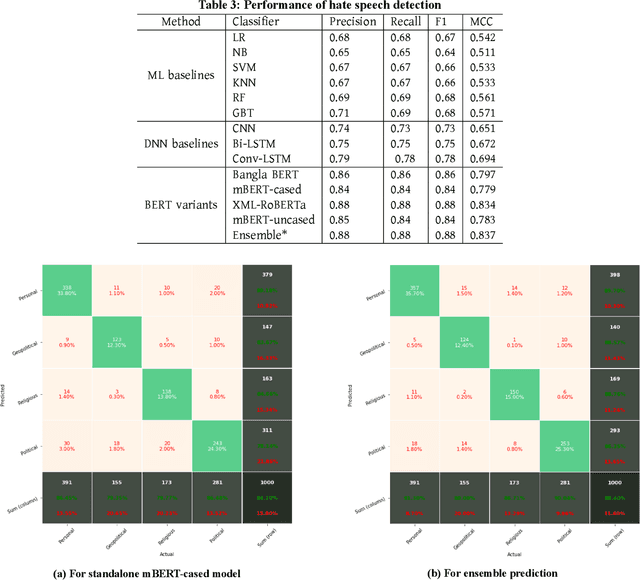
Exponential growths of social media and micro-blogging sites not only provide platforms for empowering freedom of expressions and individual voices, but also enables people to express anti-social behavior like online harassment, cyberbullying, and hate speech. Numerous works have been proposed to utilize these data for social and anti-social behavior analysis, by predicting the contexts mostly for highly-resourced languages like English. However, some languages such as Bengali are under-resourced that lack of computational resources for natural language processing(NLP). In this paper, we propose an explainable approach for hate speech detection from under-resourced Bengali language, which we called DeepHateExplainer. In our approach, Bengali texts are first comprehensively preprocessed, before classifying them into political, personal, geopolitical, and religious hates, by employing neural ensemble of different transformer-based neural architectures(i.e., monolingual Bangla BERT-base, multilingual BERT-cased and uncased, and XLM-RoBERTa), followed by identifying important terms with sensitivity analysis and layer-wise relevance propagation(LRP) to provide human-interpretable explanations. Evaluations against several machine learning~(linear and tree-based models) and deep neural networks (i.e., CNN, Bi-LSTM, and Conv-LSTM with word embeddings) baselines yield F1 scores of 84%, 90%, 88%, and 88%, for political, personal, geopolitical, and religious hates, respectively, during 3-fold cross-validation tests.