 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Hate Speech Detection from Bengali Memes and Texts
Paper and Code
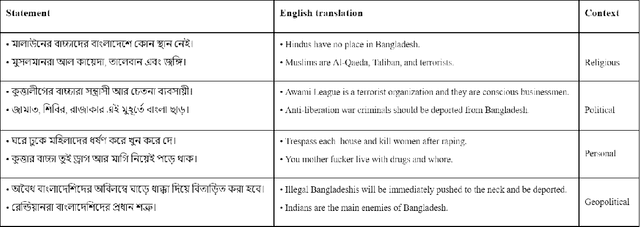
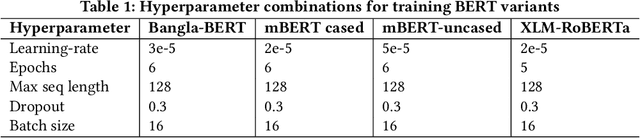
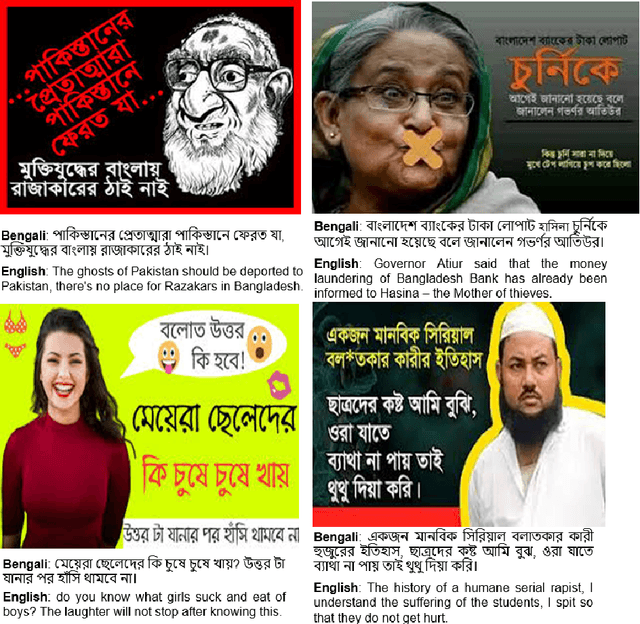
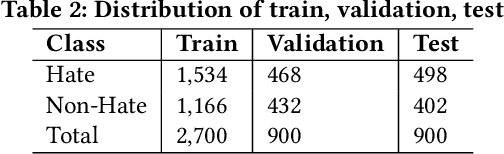
Numerous works have been proposed to employ machine learning (ML) and deep learning (DL) techniques to utilize textual data from social media for anti-social behavior analysis such as cyberbullying, fake news propagation, and hate speech mainly for highly resourced languages like English. However, despite having a lot of diversity and millions of native speakers, some languages such as Bengali are under-resourced, which is due to a lack of computational resources for natural language processing (NLP). Like English, Bengali social media content also includes images along with texts (e.g., multimodal contents are posted by embedding short texts into images on Facebook), only the textual data is not enough to judge them (e.g., to determine they are hate speech). In those cases, images might give extra context to properly judge. This paper is about hate speech detection from multimodal Bengali memes and texts. We prepared the only multimodal hate speech detection dataset1 for a kind of problem for Bengali. We train several neural architectures (i.e., neural networks like Bi-LSTM/Conv-LSTM with word embeddings, EfficientNet + transformer architectures such as monolingual Bangla BERT, multilingual BERT-cased/uncased, and XLM-RoBERTa) jointly analyze textual and visual information for hate speech detection. The Conv-LSTM and XLM-RoBERTa models performed best for texts, yielding F1 scores of 0.78 and 0.82, respectively. As of memes, ResNet152 and DenseNet201 models yield F1 scores of 0.78 and 0.7, respectively. The multimodal fusion of mBERT-uncased + EfficientNet-B1 performed the best, yielding an F1 score of 0.80. Our study suggests that memes are moderately useful for hate speech detection in Bengali, but none of the multimodal models outperform unimodal models analyzing only textual data.