 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Code-Mixed Offensive Span Identification through Rationale Extraction
May 12, 2022
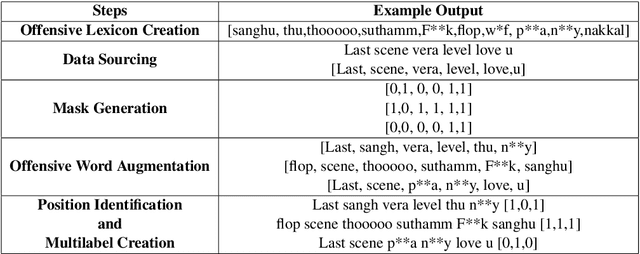

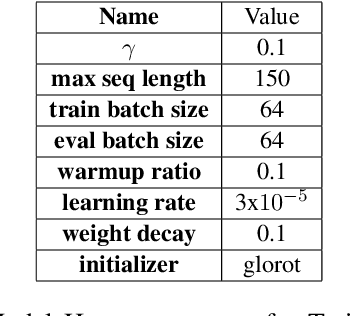
This paper investigates the effectiveness of sentence-level transformers for zero-shot offensive span identification on a code-mixed Tamil dataset. More specifically, we evaluate rationale extraction methods of Local Interpretable Model Agnostic Explanations (LIME) \cite{DBLP:conf/kdd/Ribeiro0G16} and Integrated Gradients (IG) \cite{DBLP:conf/icml/SundararajanTY17} for adapting transformer based offensive language classification models for zero-shot offensive span identification. To this end, we find that LIME and IG show baseline $F_{1}$ of 26.35\% and 44.83\%, respectively. Besides, we study the effect of data set size and training process on the overall accuracy of span identification. As a result, we find both LIME and IG to show significant improvement with Masked Data Augmentation and Multilabel Training, with $F_{1}$ of 50.23\% and 47.38\% respectively. \textit{Disclaimer : This paper contains examples that may be considered profane, vulgar, or offensive. The examples do not represent the views of the authors or their employers/graduate schools towards any person(s), group(s), practice(s), or entity/entities. Instead they are used to emphasize only the linguistic research challenges.}
Findings of the Shared Task on Offensive Span Identification from Code-Mixed Tamil-English Comments
May 12, 2022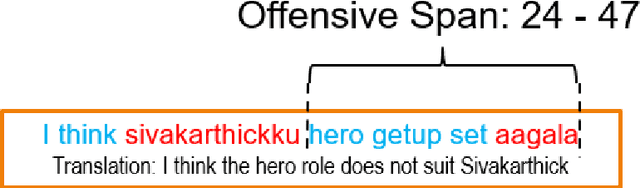
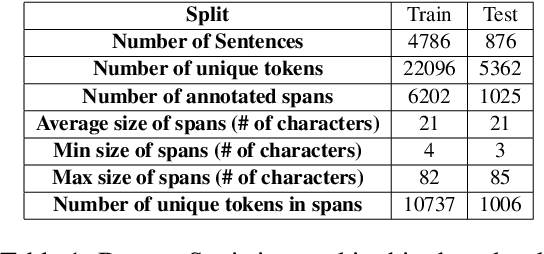
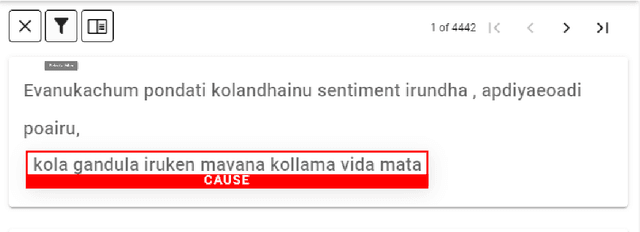
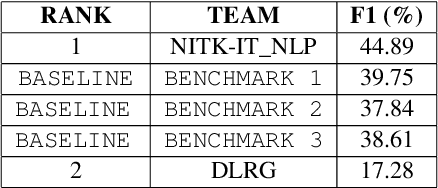
Offensive content moderation is vital in social media platforms to support healthy online discussions. However, their prevalence in codemixed Dravidian languages is limited to classifying whole comments without identifying part of it contributing to offensiveness. Such limitation is primarily due to the lack of annotated data for offensive spans. Accordingly, in this shared task, we provide Tamil-English code-mixed social comments with offensive spans. This paper outlines the dataset so released, methods, and results of the submitted systems
Multimodal Hate Speech Detection from Bengali Memes and Texts
Apr 19, 2022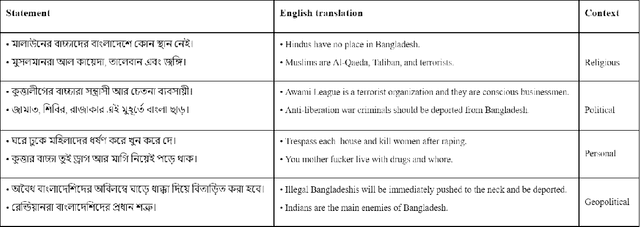
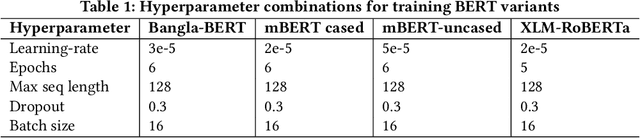
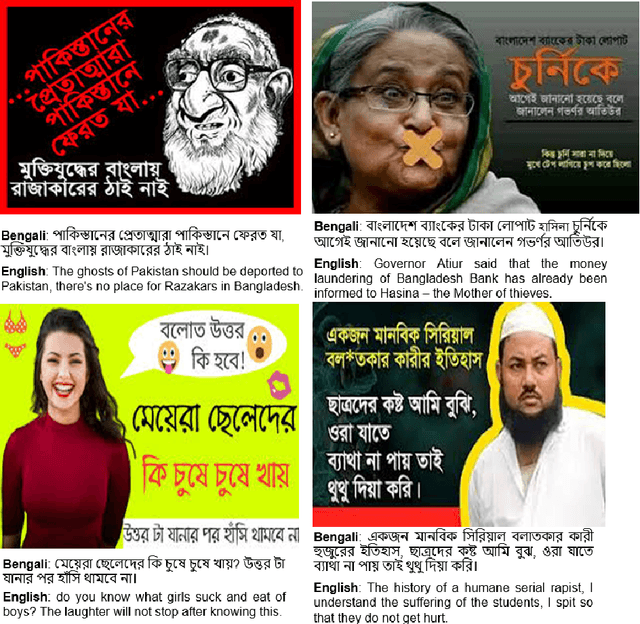
Numerous works have been proposed to employ machine learning (ML) and deep learning (DL) techniques to utilize textual data from social media for anti-social behavior analysis such as cyberbullying, fake news propagation, and hate speech mainly for highly resourced languages like English. However, despite having a lot of diversity and millions of native speakers, some languages such as Bengali are under-resourced, which is due to a lack of computational resources for natural language processing (NLP). Like English, Bengali social media content also includes images along with texts (e.g., multimodal contents are posted by embedding short texts into images on Facebook), only the textual data is not enough to judge them (e.g., to determine they are hate speech). In those cases, images might give extra context to properly judge. This paper is about hate speech detection from multimodal Bengali memes and texts. We prepared the only multimodal hate speech detection dataset1 for a kind of problem for Bengali. We train several neural architectures (i.e., neural networks like Bi-LSTM/Conv-LSTM with word embeddings, EfficientNet + transformer architectures such as monolingual Bangla BERT, multilingual BERT-cased/uncased, and XLM-RoBERTa) jointly analyze textual and visual information for hate speech detection. The Conv-LSTM and XLM-RoBERTa models performed best for texts, yielding F1 scores of 0.78 and 0.82, respectively. As of memes, ResNet152 and DenseNet201 models yield F1 scores of 0.78 and 0.7, respectively. The multimodal fusion of mBERT-uncased + EfficientNet-B1 performed the best, yielding an F1 score of 0.80. Our study suggests that memes are moderately useful for hate speech detection in Bengali, but none of the multimodal models outperform unimodal models analyzing only textual data.
Overlapping Word Removal is All You Need: Revisiting Data Imbalance in Hope Speech Detection
Apr 12, 2022
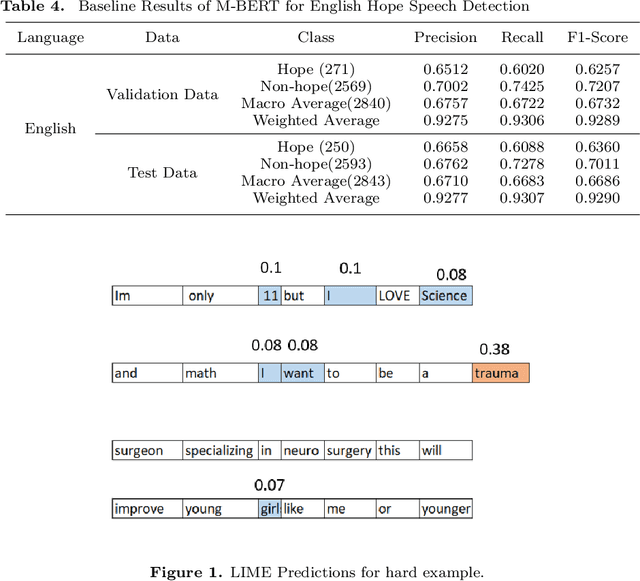


Hope Speech Detection, a task of recognizing positive expressions, has made significant strides recently. However, much of the current works focus on model development without considering the issue of inherent imbalance in the data. Our work revisits this issue in hope-speech detection by introducing focal loss, data augmentation, and pre-processing strategies. Accordingly, we find that introducing focal loss as part of Multilingual-BERT's (M-BERT) training process mitigates the effect of class imbalance and improves overall F1-Macro by 0.11. At the same time, contextual and back-translation-based word augmentation with M-BERT improves results by 0.10 over baseline despite imbalance. Finally, we show that overlapping word removal based on pre-processing, though simple, improves F1-Macro by 0.28. In due process, we present detailed studies depicting various behaviors of each of these strategies and summarize key findings from our empirical results for those interested in getting the most out of M-BERT for hope speech detection under real-world conditions of data imbalance.
TamilEmo: Finegrained Emotion Detection Dataset for Tamil
Feb 09, 2022

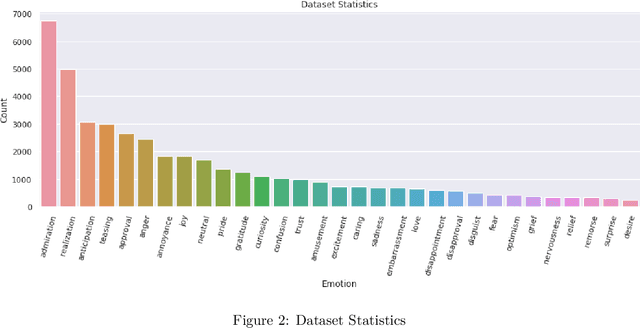
Emotional Analysis from textual input has been considered both a challenging and interesting task in Natural Language Processing. However, due to the lack of datasets in low-resource languages (i.e. Tamil), it is difficult to conduct research of high standard in this area. Therefore we introduce this labelled dataset (a largest manually annotated dataset of more than 42k Tamil YouTube comments, labelled for 31 emotions including neutral) for emotion recognition. The goal of this dataset is to improve emotion detection in multiple downstream tasks in Tamil. We have also created three different groupings of our emotions (3-class, 7-class and 31-class) and evaluated the model's performance on each category of the grouping. Our MURIL-base model has achieved a 0.60 macro average F1-score across our 3-class group dataset. With 7-class and 31-class groups, the Random Forest model performed well with a macro average F1-scores of 0.42 and 0.29 respectively.
Hypers at ComMA@ICON: Modelling Aggressiveness, Gender Bias and Communal Bias Identification
Jan 13, 2022


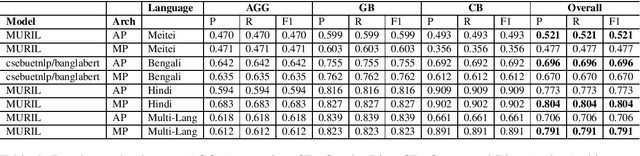
Due to the exponentially increasing reach of social media, it is essential to focus on its negative aspects as it can potentially divide society and incite people into violence. In this paper, we present our system description of work on the shared task ComMA@ICON, where we have to classify how aggressive the sentence is and if the sentence is gender-biased or communal biased. These three could be the primary reasons to cause significant problems in society. As team Hypers we have proposed an approach that utilizes different pretrained models with Attention and mean pooling methods. We were able to get Rank 3 with 0.223 Instance F1 score on Bengali, Rank 2 with 0.322 Instance F1 score on Multi-lingual set, Rank 4 with 0.129 Instance F1 score on Meitei and Rank 5 with 0.336 Instance F1 score on Hindi. The source code and the pretrained models of this work can be found here.
Findings of the Sentiment Analysis of Dravidian Languages in Code-Mixed Text
Nov 18, 2021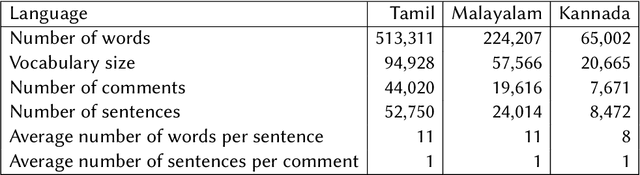
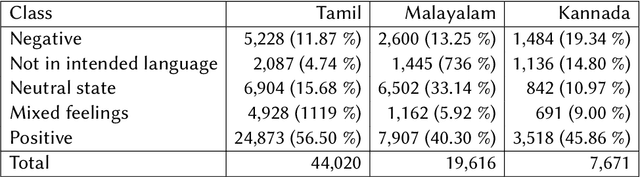
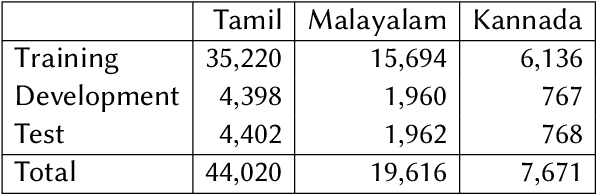
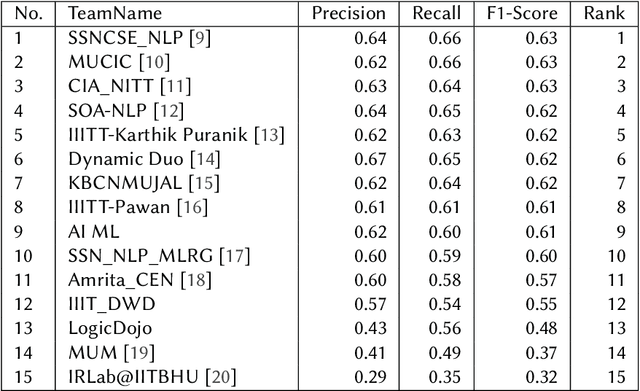
We present the results of the Dravidian-CodeMix shared task held at FIRE 2021, a track on sentiment analysis for Dravidian Languages in Code-Mixed Text. We describe the task, its organization, and the submitted systems. This shared task is the continuation of last year's Dravidian-CodeMix shared task held at FIRE 2020. This year's tasks included code-mixing at the intra-token and inter-token levels. Additionally, apart from Tamil and Malayalam, Kannada was also introduced. We received 22 systems for Tamil-English, 15 systems for Malayalam-English, and 15 for Kannada-English. The top system for Tamil-English, Malayalam-English and Kannada-English scored weighted average F1-score of 0.711, 0.804, and 0.630, respectively. In summary, the quality and quantity of the submission show that there is great interest in Dravidian languages in code-mixed setting and state of the art in this domain still needs more improvement.
Developing Successful Shared Tasks on Offensive Language Identification for Dravidian Languages
Nov 05, 2021
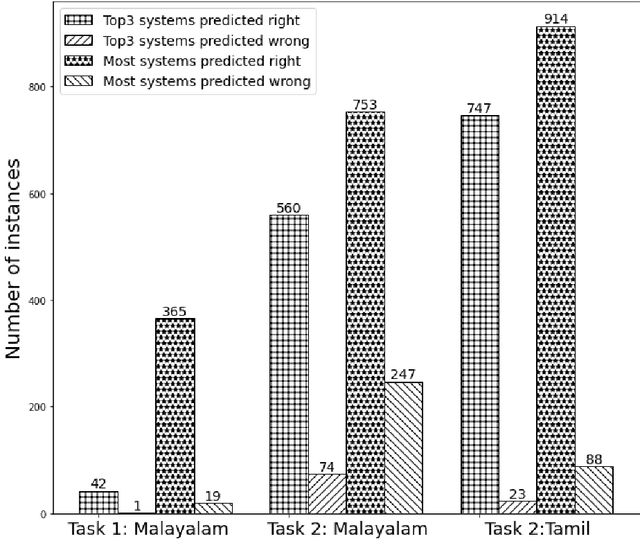

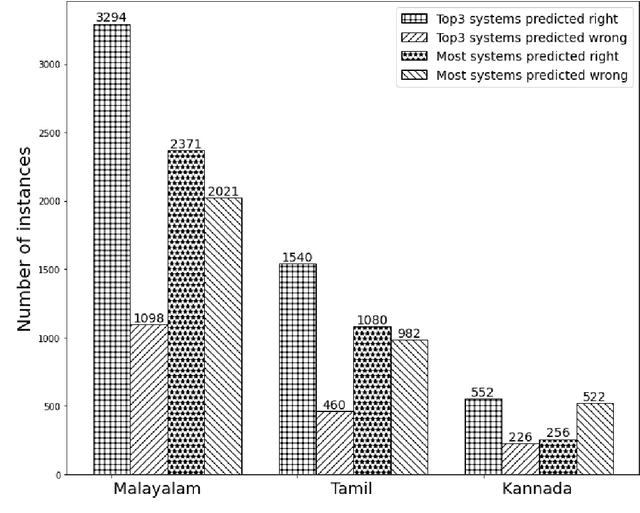
With the fast growth of mobile computing and Web technologies, offensive language has become more prevalent on social networking platforms. Since offensive language identification in local languages is essential to moderate the social media content, in this paper we work with three Dravidian languages, namely Malayalam, Tamil, and Kannada, that are under-resourced. We present an evaluation task at FIRE 2020- HASOC-DravidianCodeMix and DravidianLangTech at EACL 2021, designed to provide a framework for comparing different approaches to this problem. This paper describes the data creation, defines the task, lists the participating systems, and discusses various methods.
TrollsWithOpinion: A Dataset for Predicting Domain-specific Opinion Manipulation in Troll Memes
Sep 08, 2021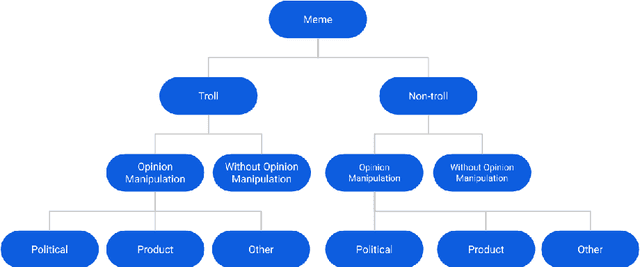

Research into the classification of Image with Text (IWT) troll memes has recently become popular. Since the online community utilizes the refuge of memes to express themselves, there is an abundance of data in the form of memes. These memes have the potential to demean, harras, or bully targeted individuals. Moreover, the targeted individual could fall prey to opinion manipulation. To comprehend the use of memes in opinion manipulation, we define three specific domains (product, political or others) which we classify into troll or not-troll, with or without opinion manipulation. To enable this analysis, we enhanced an existing dataset by annotating the data with our defined classes, resulting in a dataset of 8,881 IWT or multimodal memes in the English language (TrollsWithOpinion dataset). We perform baseline experiments on the annotated dataset, and our result shows that existing state-of-the-art techniques could only reach a weighted-average F1-score of 0.37. This shows the need for a development of a specific technique to deal with multimodal troll memes.
Dataset for Identification of Homophobia and Transophobia in Multilingual YouTube Comments
Sep 01, 2021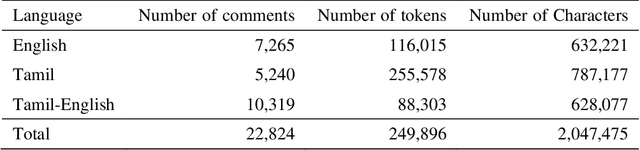
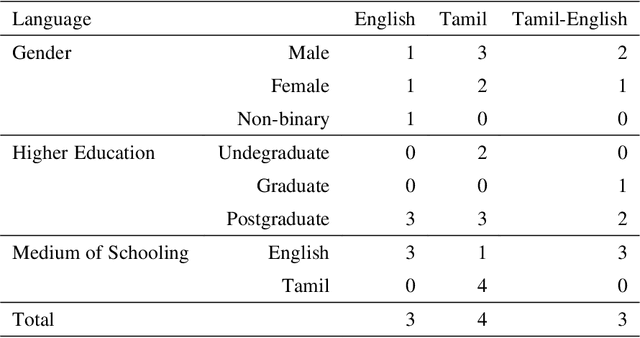
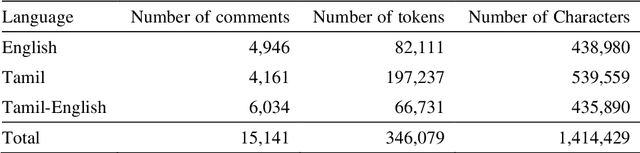
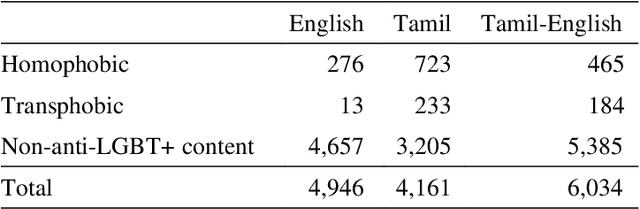
The increased proliferation of abusive content on social media platforms has a negative impact on online users. The dread, dislike, discomfort, or mistrust of lesbian, gay, transgender or bisexual persons is defined as homophobia/transphobia. Homophobic/transphobic speech is a type of offensive language that may be summarized as hate speech directed toward LGBT+ people, and it has been a growing concern in recent years. Online homophobia/transphobia is a severe societal problem that can make online platforms poisonous and unwelcome to LGBT+ people while also attempting to eliminate equality, diversity, and inclusion. We provide a new hierarchical taxonomy for online homophobia and transphobia, as well as an expert-labelled dataset that will allow homophobic/transphobic content to be automatically identified. We educated annotators and supplied them with comprehensive annotation rules because this is a sensitive issue, and we previously discovered that untrained crowdsourcing annotators struggle with diagnosing homophobia due to cultural and other prejudices. The dataset comprises 15,141 annotated multilingual comments. This paper describes the process of building the dataset, qualitative analysis of data, and inter-annotator agreement. In addition, we create baseline models for the dataset. To the best of our knowledge, our dataset is the first such dataset created. Warning: This paper contains explicit statements of homophobia, transphobia, stereotypes which may be distressing to some readers.