 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverlapping Word Removal is All You Need: Revisiting Data Imbalance in Hope Speech Detection
Apr 12, 2022
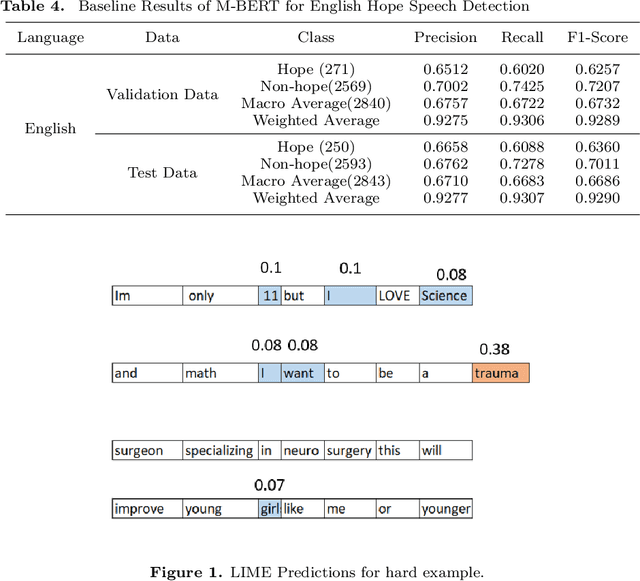


Hope Speech Detection, a task of recognizing positive expressions, has made significant strides recently. However, much of the current works focus on model development without considering the issue of inherent imbalance in the data. Our work revisits this issue in hope-speech detection by introducing focal loss, data augmentation, and pre-processing strategies. Accordingly, we find that introducing focal loss as part of Multilingual-BERT's (M-BERT) training process mitigates the effect of class imbalance and improves overall F1-Macro by 0.11. At the same time, contextual and back-translation-based word augmentation with M-BERT improves results by 0.10 over baseline despite imbalance. Finally, we show that overlapping word removal based on pre-processing, though simple, improves F1-Macro by 0.28. In due process, we present detailed studies depicting various behaviors of each of these strategies and summarize key findings from our empirical results for those interested in getting the most out of M-BERT for hope speech detection under real-world conditions of data imbalance.
Human-like Relational Models for Activity Recognition in Video
Jul 12, 2021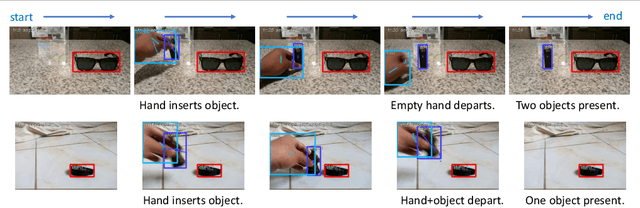
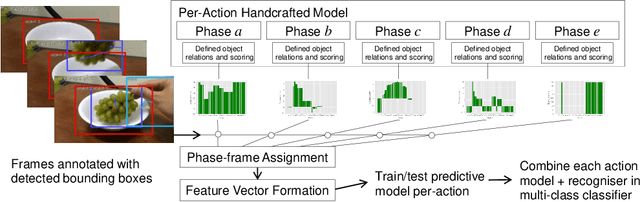
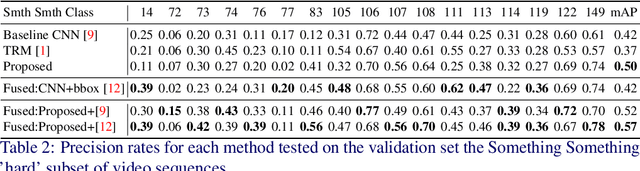
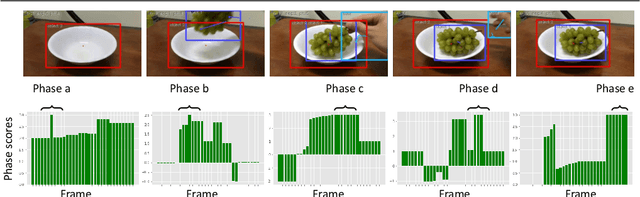
Video activity recognition by deep neural networks is impressive for many classes. However, it falls short of human performance, especially for challenging to discriminate activities. Humans differentiate these complex activities by recognising critical spatio-temporal relations among explicitly recognised objects and parts, for example, an object entering the aperture of a container. Deep neural networks can struggle to learn such critical relationships effectively. Therefore we propose a more human-like approach to activity recognition, which interprets a video in sequential temporal phases and extracts specific relationships among objects and hands in those phases. Random forest classifiers are learnt from these extracted relationships. We apply the method to a challenging subset of the something-something dataset and achieve a more robust performance against neural network baselines on challenging activities.