 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like Relational Models for Activity Recognition in Video
Paper and Code
Jul 12, 2021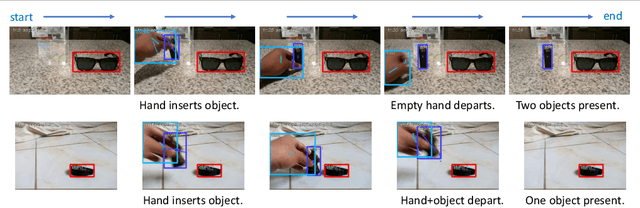
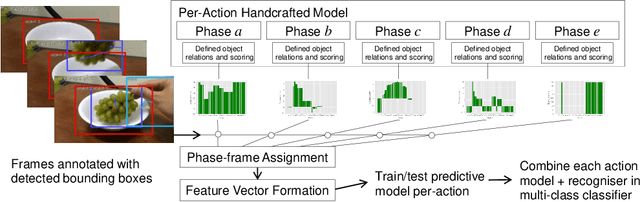
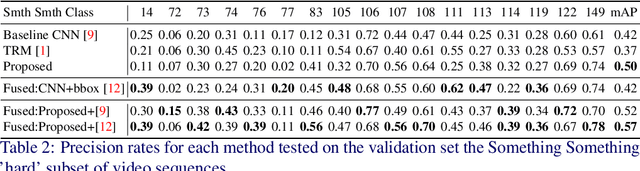
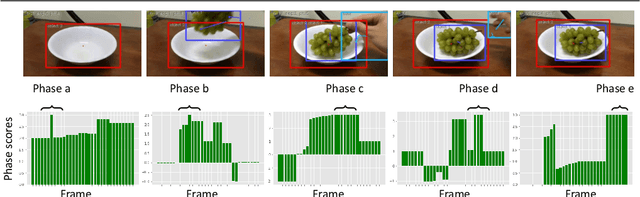
Video activity recognition by deep neural networks is impressive for many classes. However, it falls short of human performance, especially for challenging to discriminate activities. Humans differentiate these complex activities by recognising critical spatio-temporal relations among explicitly recognised objects and parts, for example, an object entering the aperture of a container. Deep neural networks can struggle to learn such critical relationships effectively. Therefore we propose a more human-like approach to activity recognition, which interprets a video in sequential temporal phases and extracts specific relationships among objects and hands in those phases. Random forest classifiers are learnt from these extracted relationships. We apply the method to a challenging subset of the something-something dataset and achieve a more robust performance against neural network baselines on challenging activities.