 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian-Manifold Steering: Geometry-Aware Generative Autoencoders for Label-Free Steering
May 24, 2026Steering a language model - intervening on its internal activations to change downstream behaviour - has recently expanded beyond linear interpolation to nonlinear methods such as angular and kernelized steering, which define intervention transformations without learning an explicit geometry over paths in activation space. Freshly introduced geometry-aware manifold methods do learn such a geometry, but require labelled class centroids together with prescribed cyclic or sequential structure. These assumptions restrict where manifold steering can be applied, since existing constructions require labelled centroids and compatible boundary conditions. We recast manifold steering more broadly as \textbf{Riemannian geodesic computation} on activation space, recovering linear and labelled-spline steering as geodesics under particular choices of metric. A principled metric within this framework is the output-space Hellinger distance pulled back to activations; we approximate this with a learned encoder trained on output distances over a small concept-token schema - no per-prompt labels, no topology prior, and no per-task curve fitting. Empirically, the method reliably drives the model onto the target class across all tasks in a standard four-task language-model arithmetic benchmark, while following more behaviourally natural trajectories than baselines on smaller output spaces. We thereby provide a unified Riemannian framework for manifold steering together with a schema-supervised, label-free instantiation that operates without labelled centroids or prescribed boundary conditions.
INDIC DIALECT: A Multi Task Benchmark to Evaluate and Translate in Indian Language Dialects
Jan 15, 2026Recent NLP advances focus primarily on standardized languages, leaving most low-resource dialects under-served especially in Indian scenarios. In India, the issue is particularly important: despite Hindi being the third most spoken language globally (over 600 million speakers), its numerous dialects remain underrepresented. The situation is similar for Odia, which has around 45 million speakers. While some datasets exist which contain standard Hindi and Odia languages, their regional dialects have almost no web presence. We introduce INDIC-DIALECT, a human-curated parallel corpus of 13k sentence pairs spanning 11 dialects and 2 languages: Hindi and Odia. Using this corpus, we construct a multi-task benchmark with three tasks: dialect classification, multiple-choice question (MCQ) answering, and machine translation (MT). Our experiments show that LLMs like GPT-4o and Gemini 2.5 perform poorly on the classification task. While fine-tuned transformer based models pretrained on Indian languages substantially improve performance e.g., improving F1 from 19.6\% to 89.8\% on dialect classification. For dialect to language translation, we find that hybrid AI model achieves highest BLEU score of 61.32 compared to the baseline score of 23.36. Interestingly, due to complexity in generating dialect sentences, we observe that for language to dialect translation the ``rule-based followed by AI" approach achieves best BLEU score of 48.44 compared to the baseline score of 27.59. INDIC-DIALECT thus is a new benchmark for dialect-aware Indic NLP, and we plan to release it as open source to support further work on low-resource Indian dialects.
Towards Transparent AI Grading: Semantic Entropy as a Signal for Human-AI Disagreement
Aug 06, 2025Automated grading systems can efficiently score short-answer responses, yet they often fail to indicate when a grading decision is uncertain or potentially contentious. We introduce semantic entropy, a measure of variability across multiple GPT-4-generated explanations for the same student response, as a proxy for human grader disagreement. By clustering rationales via entailment-based similarity and computing entropy over these clusters, we quantify the diversity of justifications without relying on final output scores. We address three research questions: (1) Does semantic entropy align with human grader disagreement? (2) Does it generalize across academic subjects? (3) Is it sensitive to structural task features such as source dependency? Experiments on the ASAP-SAS dataset show that semantic entropy correlates with rater disagreement, varies meaningfully across subjects, and increases in tasks requiring interpretive reasoning. Our findings position semantic entropy as an interpretable uncertainty signal that supports more transparent and trustworthy AI-assisted grading workflows.
Zero-shot Code-Mixed Offensive Span Identification through Rationale Extraction
May 12, 2022
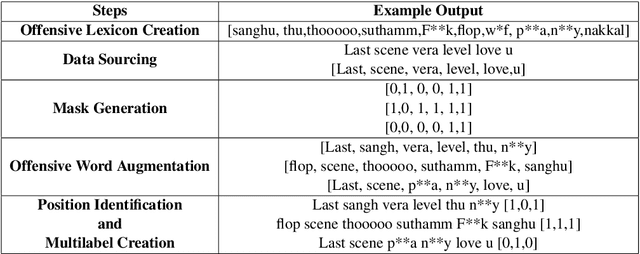

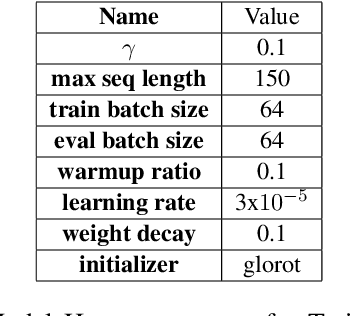
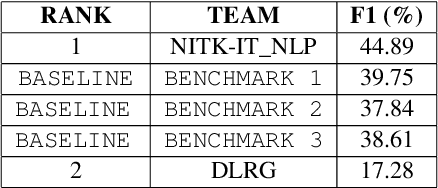
This paper investigates the effectiveness of sentence-level transformers for zero-shot offensive span identification on a code-mixed Tamil dataset. More specifically, we evaluate rationale extraction methods of Local Interpretable Model Agnostic Explanations (LIME) \cite{DBLP:conf/kdd/Ribeiro0G16} and Integrated Gradients (IG) \cite{DBLP:conf/icml/SundararajanTY17} for adapting transformer based offensive language classification models for zero-shot offensive span identification. To this end, we find that LIME and IG show baseline $F_{1}$ of 26.35\% and 44.83\%, respectively. Besides, we study the effect of data set size and training process on the overall accuracy of span identification. As a result, we find both LIME and IG to show significant improvement with Masked Data Augmentation and Multilabel Training, with $F_{1}$ of 50.23\% and 47.38\% respectively. \textit{Disclaimer : This paper contains examples that may be considered profane, vulgar, or offensive. The examples do not represent the views of the authors or their employers/graduate schools towards any person(s), group(s), practice(s), or entity/entities. Instead they are used to emphasize only the linguistic research challenges.}
Findings of the Shared Task on Offensive Span Identification from Code-Mixed Tamil-English Comments
May 12, 2022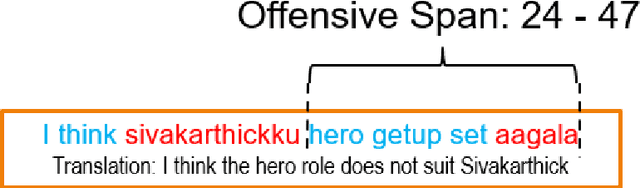
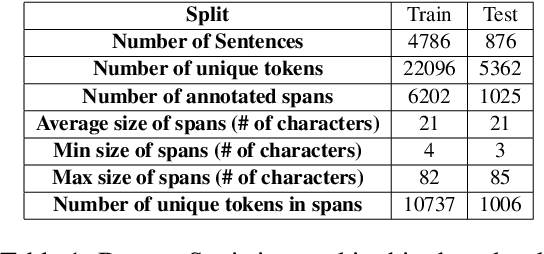
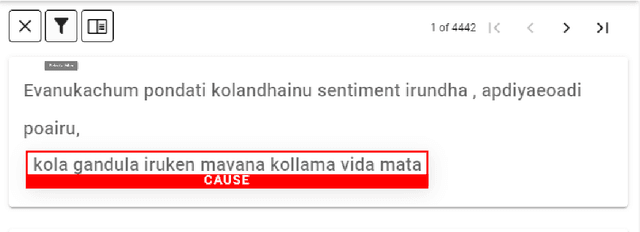
Offensive content moderation is vital in social media platforms to support healthy online discussions. However, their prevalence in codemixed Dravidian languages is limited to classifying whole comments without identifying part of it contributing to offensiveness. Such limitation is primarily due to the lack of annotated data for offensive spans. Accordingly, in this shared task, we provide Tamil-English code-mixed social comments with offensive spans. This paper outlines the dataset so released, methods, and results of the submitted systems
Overlapping Word Removal is All You Need: Revisiting Data Imbalance in Hope Speech Detection
Apr 12, 2022
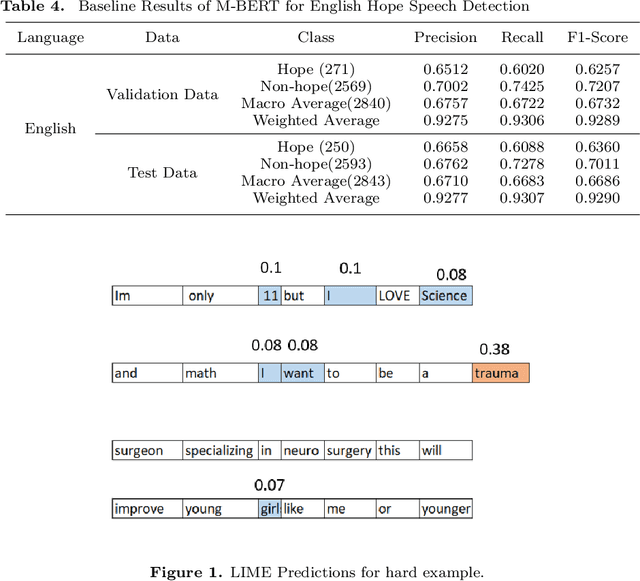


Hope Speech Detection, a task of recognizing positive expressions, has made significant strides recently. However, much of the current works focus on model development without considering the issue of inherent imbalance in the data. Our work revisits this issue in hope-speech detection by introducing focal loss, data augmentation, and pre-processing strategies. Accordingly, we find that introducing focal loss as part of Multilingual-BERT's (M-BERT) training process mitigates the effect of class imbalance and improves overall F1-Macro by 0.11. At the same time, contextual and back-translation-based word augmentation with M-BERT improves results by 0.10 over baseline despite imbalance. Finally, we show that overlapping word removal based on pre-processing, though simple, improves F1-Macro by 0.28. In due process, we present detailed studies depicting various behaviors of each of these strategies and summarize key findings from our empirical results for those interested in getting the most out of M-BERT for hope speech detection under real-world conditions of data imbalance.
Investigating the Effect of Intraclass Variability in Temporal Ensembling
Aug 21, 2020


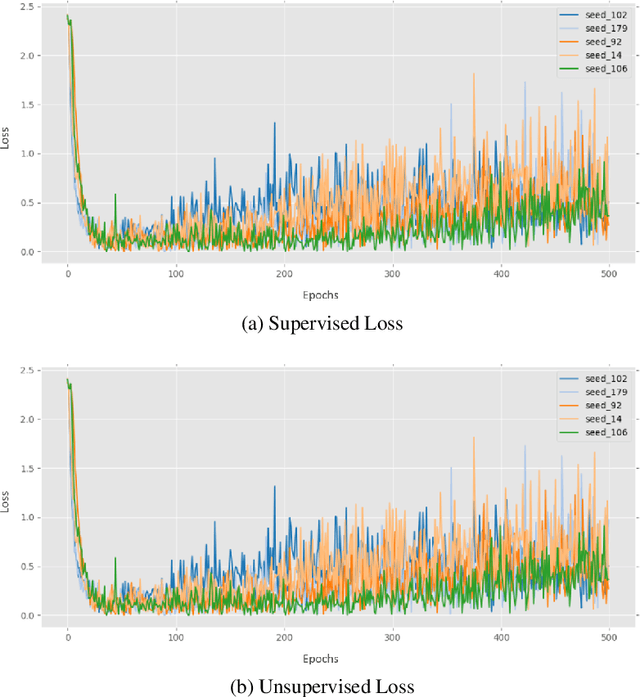
Temporal Ensembling is a semi-supervised approach that allows training deep neural network models with a small number of labeled images. In this paper, we present our preliminary study on the effect of intraclass variability on temporal ensembling, with a focus on seed size and seed type, respectively. Through our experiments we find that (a) there is a significant drop in accuracy with datasets that offer high intraclass variability, (b) more seed images offer consistently higher accuracy across the datasets, and (c) seed type indeed has an impact on the overall efficiency, where it produces a spectrum of accuracy both lower and higher. Additionally, based on our experiments, we also find KMNIST to be a competitive baseline for temporal ensembling.
Hitachi at SemEval-2020 Task 12: Offensive Language Identification with Noisy Labels using Statistical Sampling and Post-Processing
May 01, 2020
In this paper, we present our participation in SemEval-2020 Task-12 Subtask-A (English Language) which focuses on offensive language identification from noisy labels. To this end, we developed a hybrid system with the BERT classifier trained with tweets selected using Statistical Sampling Algorithm (SA) and Post-Processed (PP) using an offensive wordlist. Our developed system achieved 34 th position with Macro-averaged F1-score (Macro-F1) of 0.90913 over both offensive and non-offensive classes. We further show comprehensive results and error analysis to assist future research in offensive language identification with noisy labels.
Finding Black Cat in a Coal Cellar -- Keyphrase Extraction & Keyphrase-Rubric Relationship Classification from Complex Assignments
Apr 24, 2020
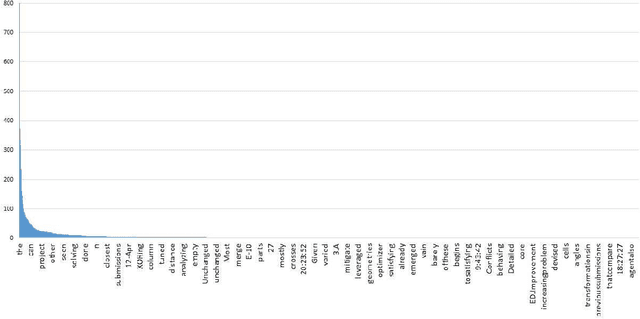

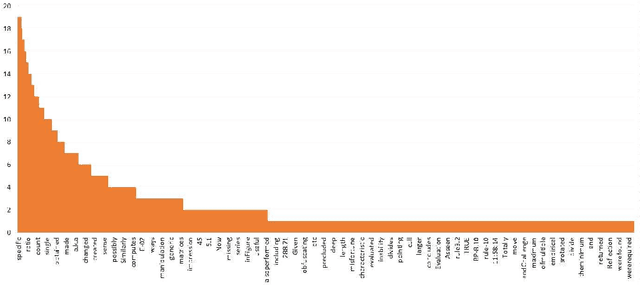
Diversity in content and open-ended questions are inherent in complex assignments across online graduate programs. The natural scale of these programs poses a variety of challenges across both peer and expert feedback including rogue reviews. While the identification of relevant content and associating it to predefined rubrics would simplify and improve the grading process, the research to date is still in a nascent stage. As such in this paper we aim to quantify the effectiveness of supervised and unsupervised approaches for the task for keyphrase extraction and generic/specific keyphrase-rubric relationship extraction. Through this study, we find that (i) unsupervised MultiPartiteRank produces the best result for keyphrase extraction (ii) supervised SVM classifier with BERT features that offer the best performance for both generic and specific keyphrase-rubric relationship classification. We finally present a comprehensive analysis and derive useful observations for those interested in these tasks for the future. The source code is released in \url{https://github.com/manikandan-ravikiran/cs6460-proj}.
Key Phrase Classification in Complex Assignments
Mar 16, 2020
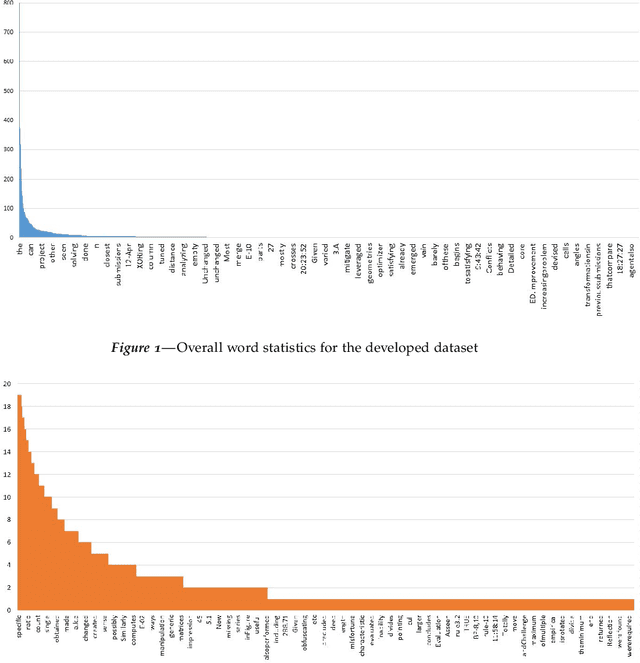

Complex assignments typically consist of open-ended questions with large and diverse content in the context of both classroom and online graduate programs. With the sheer scale of these programs comes a variety of problems in peer and expert feedback, including rogue reviews. As such with the hope of identifying important contents needed for the review, in this work we present a very first work on key phrase classification with a detailed empirical study on traditional and most recent language modeling approaches. From this study, we find that the task of classification of key phrases is ambiguous at a human level producing Cohen's kappa of 0.77 on a new data set. Both pretrained language models and simple TFIDF SVM classifiers produce similar results with a former producing average of 0.6 F1 higher than the latter. We finally derive practical advice from our extensive empirical and model interpretability results for those interested in key phrase classification from educational reports in the future.