 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Shared Task on Offensive Span Identification from Code-Mixed Tamil-English Comments
May 12, 2022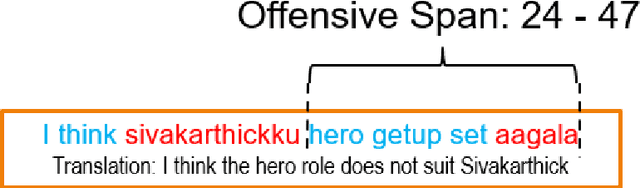
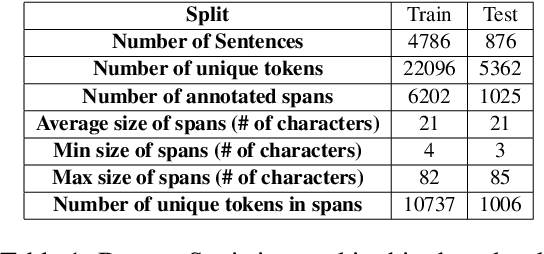
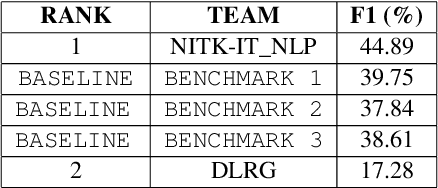
Offensive content moderation is vital in social media platforms to support healthy online discussions. However, their prevalence in codemixed Dravidian languages is limited to classifying whole comments without identifying part of it contributing to offensiveness. Such limitation is primarily due to the lack of annotated data for offensive spans. Accordingly, in this shared task, we provide Tamil-English code-mixed social comments with offensive spans. This paper outlines the dataset so released, methods, and results of the submitted systems
Findings of the Sentiment Analysis of Dravidian Languages in Code-Mixed Text
Nov 18, 2021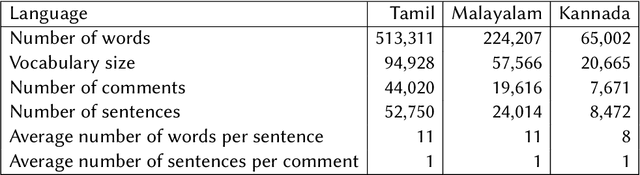
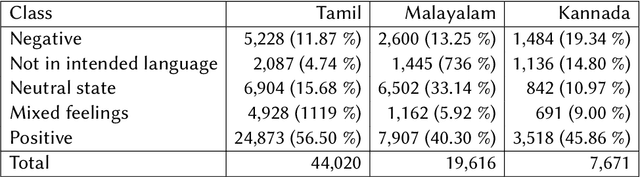
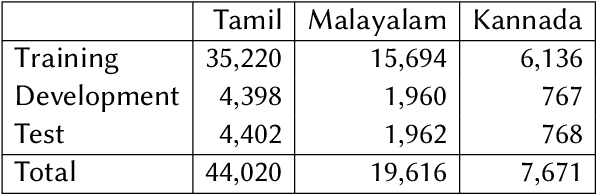
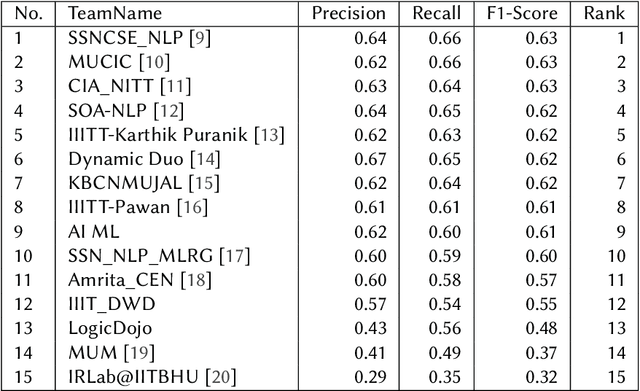
We present the results of the Dravidian-CodeMix shared task held at FIRE 2021, a track on sentiment analysis for Dravidian Languages in Code-Mixed Text. We describe the task, its organization, and the submitted systems. This shared task is the continuation of last year's Dravidian-CodeMix shared task held at FIRE 2020. This year's tasks included code-mixing at the intra-token and inter-token levels. Additionally, apart from Tamil and Malayalam, Kannada was also introduced. We received 22 systems for Tamil-English, 15 systems for Malayalam-English, and 15 for Kannada-English. The top system for Tamil-English, Malayalam-English and Kannada-English scored weighted average F1-score of 0.711, 0.804, and 0.630, respectively. In summary, the quality and quantity of the submission show that there is great interest in Dravidian languages in code-mixed setting and state of the art in this domain still needs more improvement.
Developing Successful Shared Tasks on Offensive Language Identification for Dravidian Languages
Nov 05, 2021
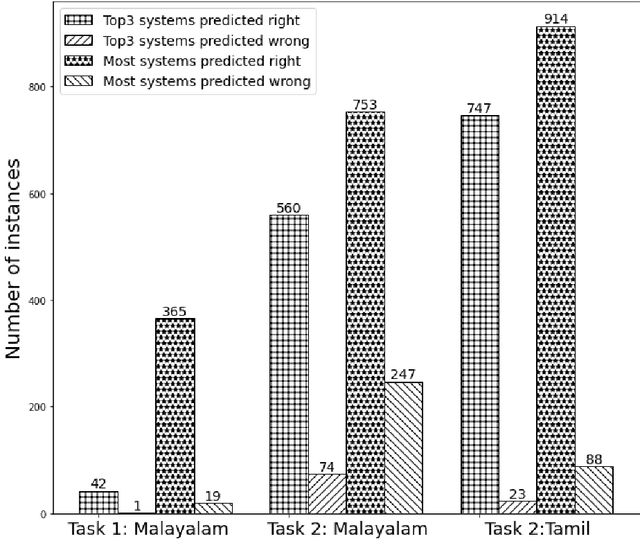

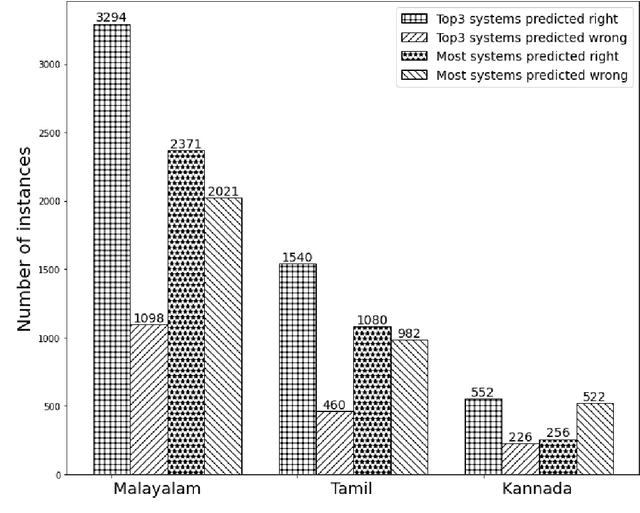
With the fast growth of mobile computing and Web technologies, offensive language has become more prevalent on social networking platforms. Since offensive language identification in local languages is essential to moderate the social media content, in this paper we work with three Dravidian languages, namely Malayalam, Tamil, and Kannada, that are under-resourced. We present an evaluation task at FIRE 2020- HASOC-DravidianCodeMix and DravidianLangTech at EACL 2021, designed to provide a framework for comparing different approaches to this problem. This paper describes the data creation, defines the task, lists the participating systems, and discusses various methods.
Offensive Language Identification in Low-resourced Code-mixed Dravidian languages using Pseudo-labeling
Aug 27, 2021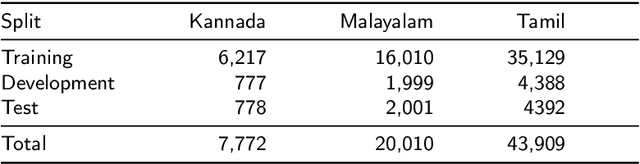
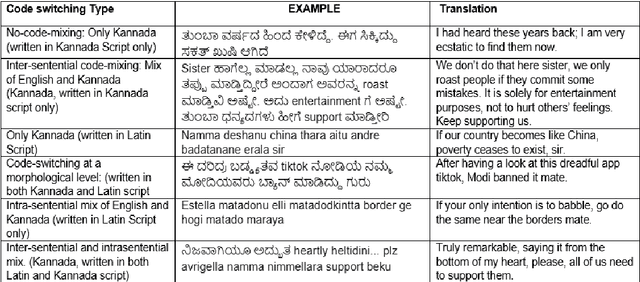

Social media has effectively become the prime hub of communication and digital marketing. As these platforms enable the free manifestation of thoughts and facts in text, images and video, there is an extensive need to screen them to protect individuals and groups from offensive content targeted at them. Our work intends to classify codemixed social media comments/posts in the Dravidian languages of Tamil, Kannada, and Malayalam. We intend to improve offensive language identification by generating pseudo-labels on the dataset. A custom dataset is constructed by transliterating all the code-mixed texts into the respective Dravidian language, either Kannada, Malayalam, or Tamil and then generating pseudo-labels for the transliterated dataset. The two datasets are combined using the generated pseudo-labels to create a custom dataset called CMTRA. As Dravidian languages are under-resourced, our approach increases the amount of training data for the language models. We fine-tune several recent pretrained language models on the newly constructed dataset. We extract the pretrained language embeddings and pass them onto recurrent neural networks. We observe that fine-tuning ULMFiT on the custom dataset yields the best results on the code-mixed test sets of all three languages. Our approach yields the best results among the benchmarked models on Tamil-English, achieving a weighted F1-Score of 0.7934 while scoring competitive weighted F1-Scores of 0.9624 and 0.7306 on the code-mixed test sets of Malayalam-English and Kannada-English, respectively.
Do Images really do the Talking? Analysing the significance of Images in Tamil Troll meme classification
Aug 09, 2021
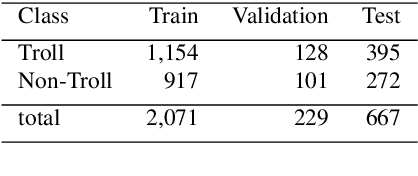
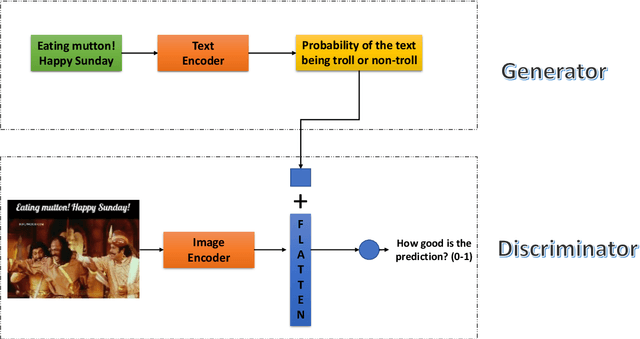
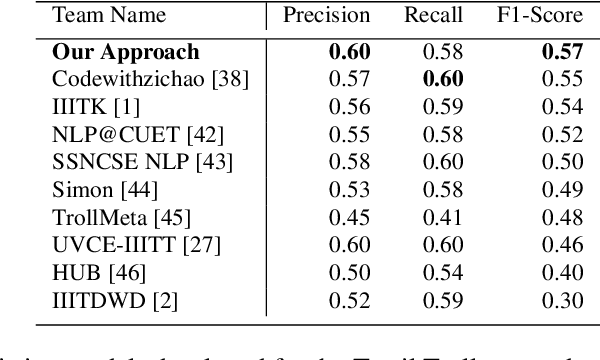
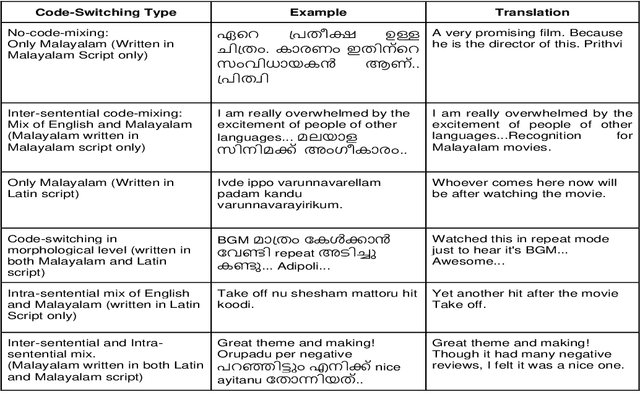
A meme is an part of media created to share an opinion or emotion across the internet. Due to its popularity, memes have become the new forms of communication on social media. However, due to its nature, they are being used in harmful ways such as trolling and cyberbullying progressively. Various data modelling methods create different possibilities in feature extraction and turning them into beneficial information. The variety of modalities included in data plays a significant part in predicting the results. We try to explore the significance of visual features of images in classifying memes. Memes are a blend of both image and text, where the text is embedded into the image. We try to incorporate the memes as troll and non-trolling memes based on the images and the text on them. However, the images are to be analysed and combined with the text to increase performance. Our work illustrates different textual analysis methods and contrasting multimodal methods ranging from simple merging to cross attention to utilising both worlds' - best visual and textual features. The fine-tuned cross-lingual language model, XLM, performed the best in textual analysis, and the multimodal transformer performs the best in multimodal analysis.
UVCE-IIITT@DravidianLangTech-EACL2021: Tamil Troll Meme Classification: You need to Pay more Attention
Apr 19, 2021

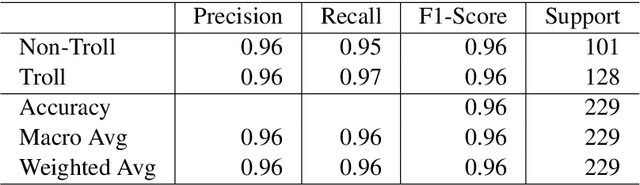

Tamil is a Dravidian language that is commonly used and spoken in the southern part of Asia. In the era of social media, memes have been a fun moment in the day-to-day life of people. Here, we try to analyze the true meaning of Tamil memes by categorizing them as troll and non-troll. We propose an ingenious model comprising of a transformer-transformer architecture that tries to attain state-of-the-art by using attention as its main component. The dataset consists of troll and non-troll images with their captions as text. The task is a binary classification task. The objective of the model is to pay more attention to the extracted features and to ignore the noise in both images and text.
IIITT@LT-EDI-EACL2021-Hope Speech Detection: There is always Hope in Transformers
Apr 19, 2021
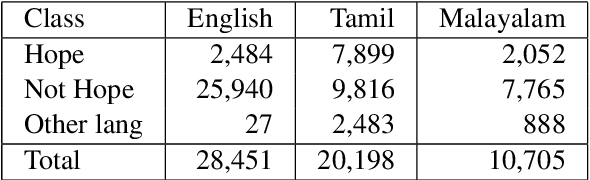

In a world filled with serious challenges like climate change, religious and political conflicts, global pandemics, terrorism, and racial discrimination, an internet full of hate speech, abusive and offensive content is the last thing we desire for. In this paper, we work to identify and promote positive and supportive content on these platforms. We work with several transformer-based models to classify social media comments as hope speech or not-hope speech in English, Malayalam and Tamil languages. This paper portrays our work for the Shared Task on Hope Speech Detection for Equality, Diversity, and Inclusion at LT-EDI 2021- EACL 2021.
NUIG-Shubhanker@Dravidian-CodeMix-FIRE2020: Sentiment Analysis of Code-Mixed Dravidian text using XLNet
Oct 15, 2020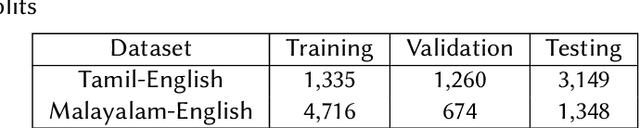
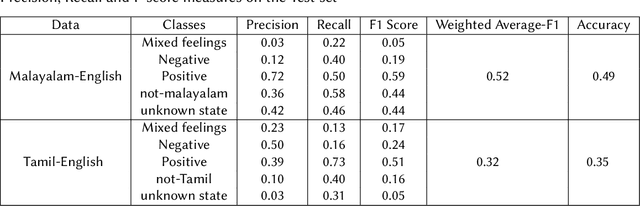
Social media has penetrated into multilingual societies, however most of them use English to be a preferred language for communication. So it looks natural for them to mix their cultural language with English during conversations resulting in abundance of multilingual data, call this code-mixed data, available in todays' world.Downstream NLP tasks using such data is challenging due to the semantic nature of it being spread across multiple languages.One such Natural Language Processing task is sentiment analysis, for this we use an auto-regressive XLNet model to perform sentiment analysis on code-mixed Tamil-English and Malayalam-English datasets.