 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Images really do the Talking? Analysing the significance of Images in Tamil Troll meme classification
Aug 09, 2021
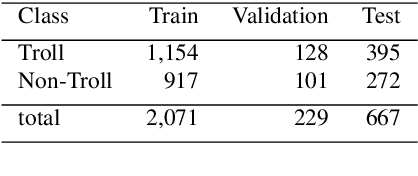
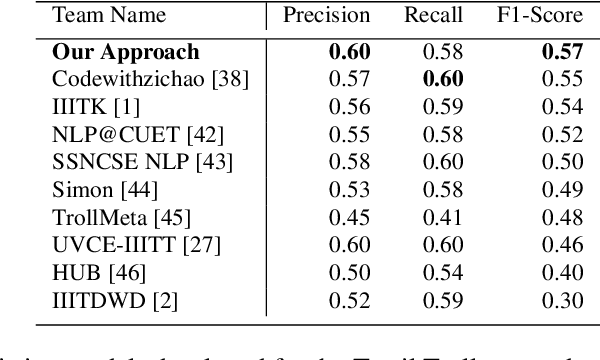
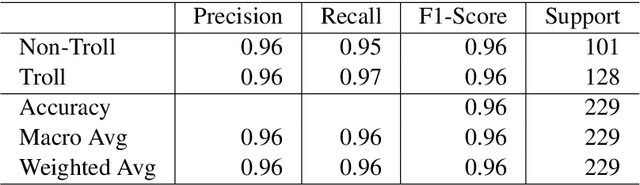
A meme is an part of media created to share an opinion or emotion across the internet. Due to its popularity, memes have become the new forms of communication on social media. However, due to its nature, they are being used in harmful ways such as trolling and cyberbullying progressively. Various data modelling methods create different possibilities in feature extraction and turning them into beneficial information. The variety of modalities included in data plays a significant part in predicting the results. We try to explore the significance of visual features of images in classifying memes. Memes are a blend of both image and text, where the text is embedded into the image. We try to incorporate the memes as troll and non-trolling memes based on the images and the text on them. However, the images are to be analysed and combined with the text to increase performance. Our work illustrates different textual analysis methods and contrasting multimodal methods ranging from simple merging to cross attention to utilising both worlds' - best visual and textual features. The fine-tuned cross-lingual language model, XLM, performed the best in textual analysis, and the multimodal transformer performs the best in multimodal analysis.
UVCE-IIITT@DravidianLangTech-EACL2021: Tamil Troll Meme Classification: You need to Pay more Attention
Apr 19, 2021


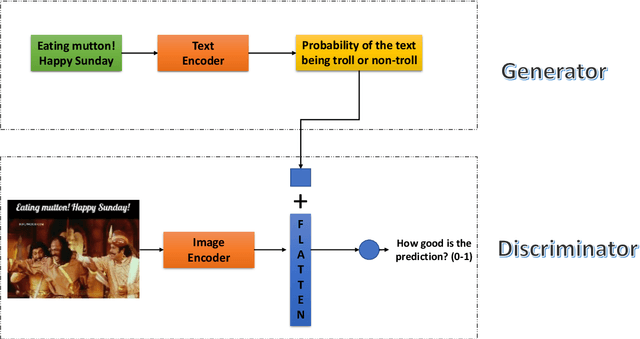
Tamil is a Dravidian language that is commonly used and spoken in the southern part of Asia. In the era of social media, memes have been a fun moment in the day-to-day life of people. Here, we try to analyze the true meaning of Tamil memes by categorizing them as troll and non-troll. We propose an ingenious model comprising of a transformer-transformer architecture that tries to attain state-of-the-art by using attention as its main component. The dataset consists of troll and non-troll images with their captions as text. The task is a binary classification task. The objective of the model is to pay more attention to the extracted features and to ignore the noise in both images and text.