Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Shared Task on Offensive Span Identification from Code-Mixed Tamil-English Comments
Paper and Code
May 12, 2022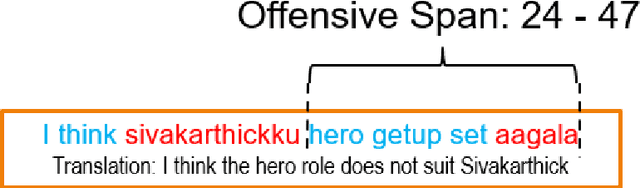
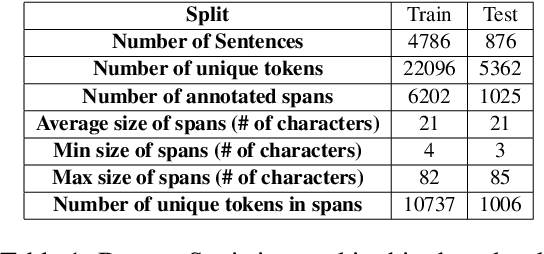
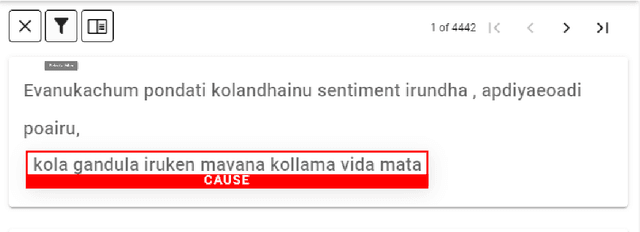
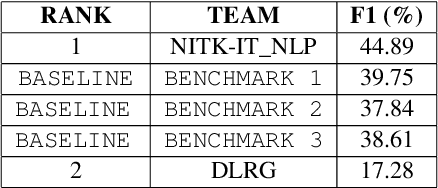
Offensive content moderation is vital in social media platforms to support healthy online discussions. However, their prevalence in codemixed Dravidian languages is limited to classifying whole comments without identifying part of it contributing to offensiveness. Such limitation is primarily due to the lack of annotated data for offensive spans. Accordingly, in this shared task, we provide Tamil-English code-mixed social comments with offensive spans. This paper outlines the dataset so released, methods, and results of the submitted systems
* System Description of Shared Task
https://competitions.codalab.org/competitions/36395
View paper on