 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSarang at DEFACTIFY 4.0: Detecting AI-Generated Text Using Noised Data and an Ensemble of DeBERTa Models
Feb 24, 2025This paper presents an effective approach to detect AI-generated text, developed for the Defactify 4.0 shared task at the fourth workshop on multimodal fact checking and hate speech detection. The task consists of two subtasks: Task-A, classifying whether a text is AI generated or human written, and Task-B, classifying the specific large language model that generated the text. Our team (Sarang) achieved the 1st place in both tasks with F1 scores of 1.0 and 0.9531, respectively. The methodology involves adding noise to the dataset to improve model robustness and generalization. We used an ensemble of DeBERTa models to effectively capture complex patterns in the text. The result indicates the effectiveness of our noise-driven and ensemble-based approach, setting a new standard in AI-generated text detection and providing guidance for future developments.
Findings of the Shared Task on Offensive Span Identification from Code-Mixed Tamil-English Comments
May 12, 2022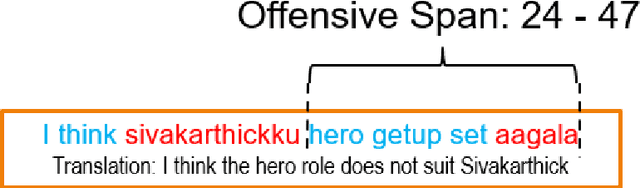
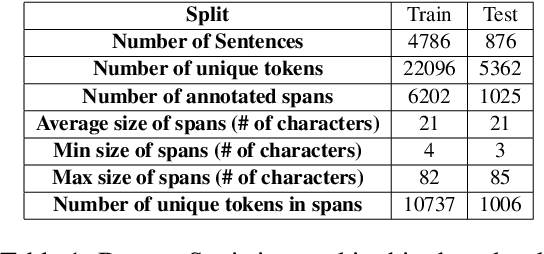
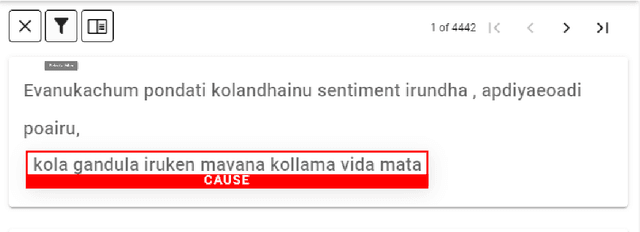
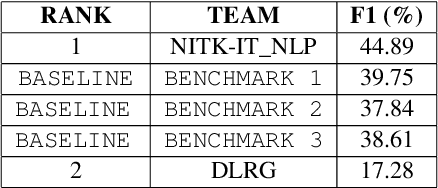
Offensive content moderation is vital in social media platforms to support healthy online discussions. However, their prevalence in codemixed Dravidian languages is limited to classifying whole comments without identifying part of it contributing to offensiveness. Such limitation is primarily due to the lack of annotated data for offensive spans. Accordingly, in this shared task, we provide Tamil-English code-mixed social comments with offensive spans. This paper outlines the dataset so released, methods, and results of the submitted systems
Developing Successful Shared Tasks on Offensive Language Identification for Dravidian Languages
Nov 05, 2021
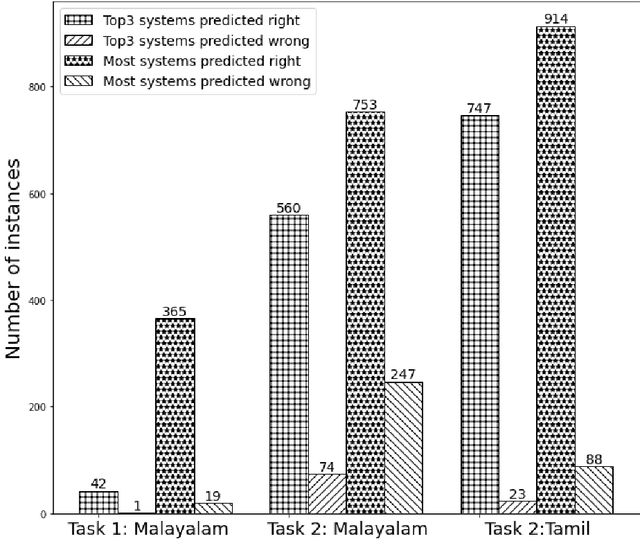

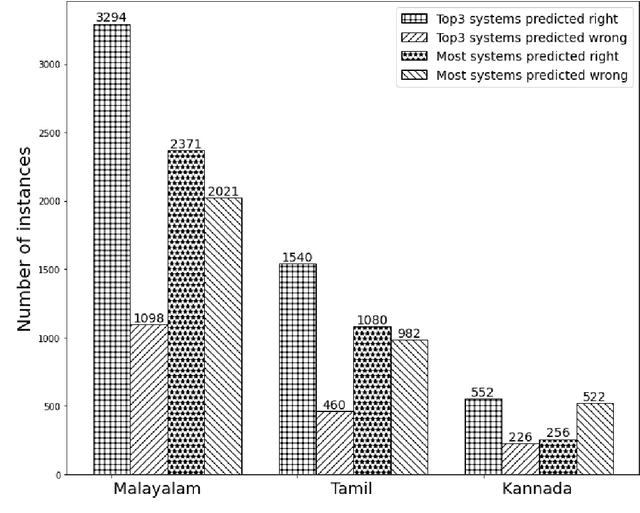
With the fast growth of mobile computing and Web technologies, offensive language has become more prevalent on social networking platforms. Since offensive language identification in local languages is essential to moderate the social media content, in this paper we work with three Dravidian languages, namely Malayalam, Tamil, and Kannada, that are under-resourced. We present an evaluation task at FIRE 2020- HASOC-DravidianCodeMix and DravidianLangTech at EACL 2021, designed to provide a framework for comparing different approaches to this problem. This paper describes the data creation, defines the task, lists the participating systems, and discusses various methods.