 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Successful Shared Tasks on Offensive Language Identification for Dravidian Languages
Nov 05, 2021
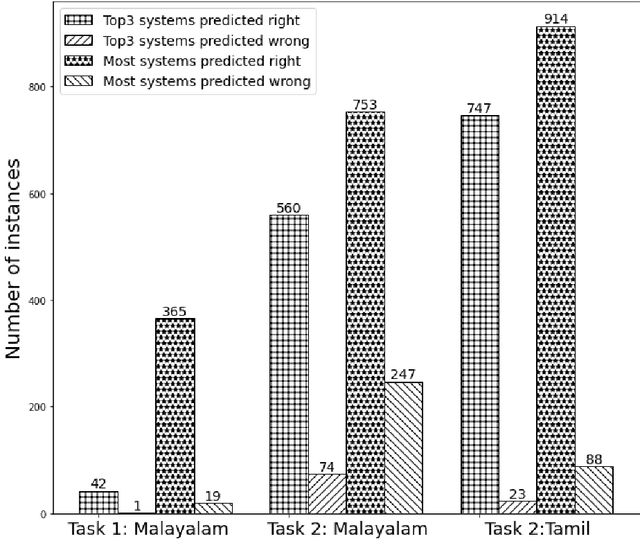

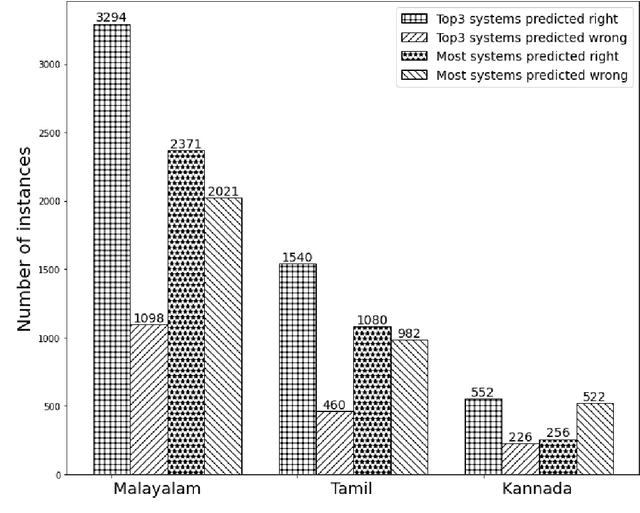
With the fast growth of mobile computing and Web technologies, offensive language has become more prevalent on social networking platforms. Since offensive language identification in local languages is essential to moderate the social media content, in this paper we work with three Dravidian languages, namely Malayalam, Tamil, and Kannada, that are under-resourced. We present an evaluation task at FIRE 2020- HASOC-DravidianCodeMix and DravidianLangTech at EACL 2021, designed to provide a framework for comparing different approaches to this problem. This paper describes the data creation, defines the task, lists the participating systems, and discusses various methods.
Dataset for Identification of Homophobia and Transophobia in Multilingual YouTube Comments
Sep 01, 2021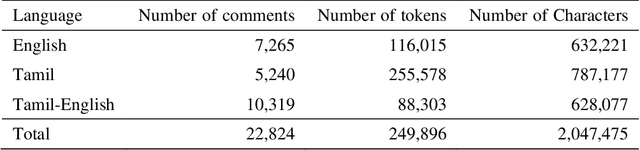
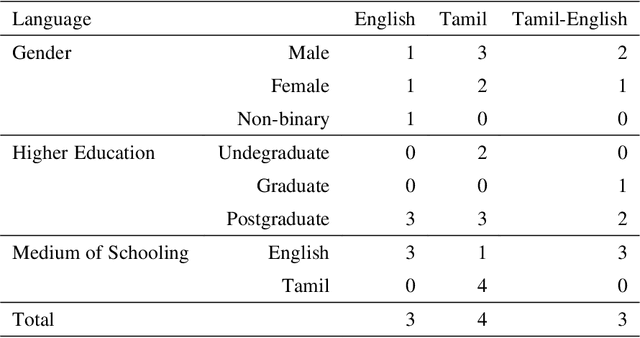
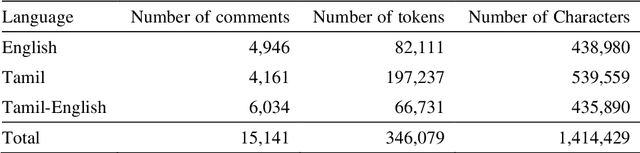
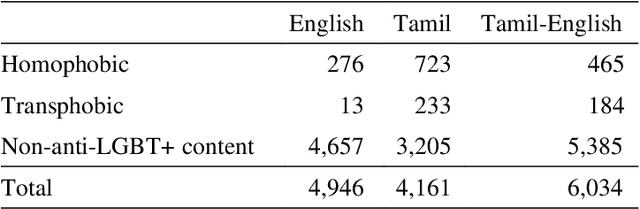
The increased proliferation of abusive content on social media platforms has a negative impact on online users. The dread, dislike, discomfort, or mistrust of lesbian, gay, transgender or bisexual persons is defined as homophobia/transphobia. Homophobic/transphobic speech is a type of offensive language that may be summarized as hate speech directed toward LGBT+ people, and it has been a growing concern in recent years. Online homophobia/transphobia is a severe societal problem that can make online platforms poisonous and unwelcome to LGBT+ people while also attempting to eliminate equality, diversity, and inclusion. We provide a new hierarchical taxonomy for online homophobia and transphobia, as well as an expert-labelled dataset that will allow homophobic/transphobic content to be automatically identified. We educated annotators and supplied them with comprehensive annotation rules because this is a sensitive issue, and we previously discovered that untrained crowdsourcing annotators struggle with diagnosing homophobia due to cultural and other prejudices. The dataset comprises 15,141 annotated multilingual comments. This paper describes the process of building the dataset, qualitative analysis of data, and inter-annotator agreement. In addition, we create baseline models for the dataset. To the best of our knowledge, our dataset is the first such dataset created. Warning: This paper contains explicit statements of homophobia, transphobia, stereotypes which may be distressing to some readers.
DravidianMultiModality: A Dataset for Multi-modal Sentiment Analysis in Tamil and Malayalam
Jun 09, 2021
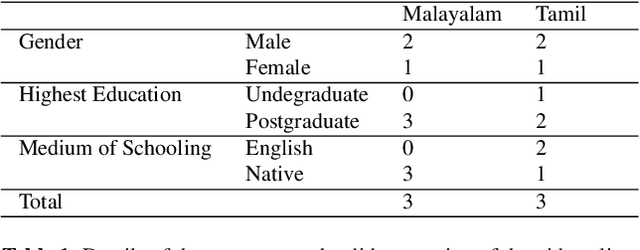

Human communication is inherently multimodal and asynchronous. Analyzing human emotions and sentiment is an emerging field of artificial intelligence. We are witnessing an increasing amount of multimodal content in local languages on social media about products and other topics. However, there are not many multimodal resources available for under-resourced Dravidian languages. Our study aims to create a multimodal sentiment analysis dataset for the under-resourced Tamil and Malayalam languages. First, we downloaded product or movies review videos from YouTube for Tamil and Malayalam. Next, we created captions for the videos with the help of annotators. Then we labelled the videos for sentiment, and verified the inter-annotator agreement using Fleiss's Kappa. This is the first multimodal sentiment analysis dataset for Tamil and Malayalam by volunteer annotators.