 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePegasus@Dravidian-CodeMix-HASOC2021: Analyzing Social Media Content for Detection of Offensive Text
Nov 18, 2021
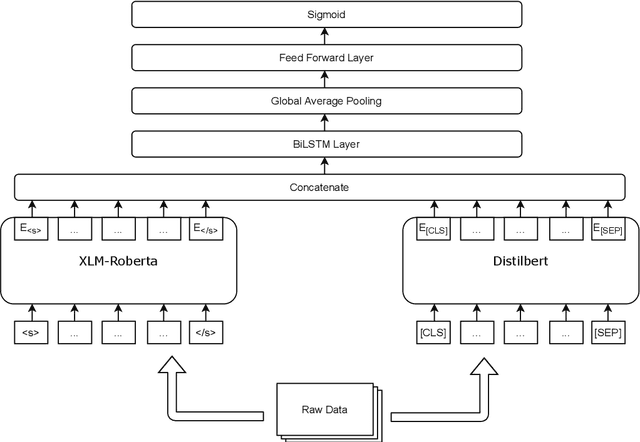

To tackle the conundrum of detecting offensive comments/posts which are considerably informal, unstructured, miswritten and code-mixed, we introduce two inventive methods in this research paper. Offensive comments/posts on the social media platforms, can affect an individual, a group or underage alike. In order to classify comments/posts in two popular Dravidian languages, Tamil and Malayalam, as a part of the HASOC - DravidianCodeMix FIRE 2021 shared task, we employ two Transformer-based prototypes which successfully stood in the top 8 for all the tasks. The codes for our approach can be viewed and utilized.
Attentive fine-tuning of Transformers for Translation of low-resourced languages @LoResMT 2021
Aug 31, 2021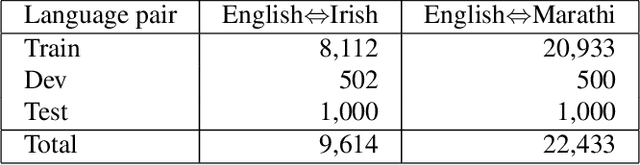
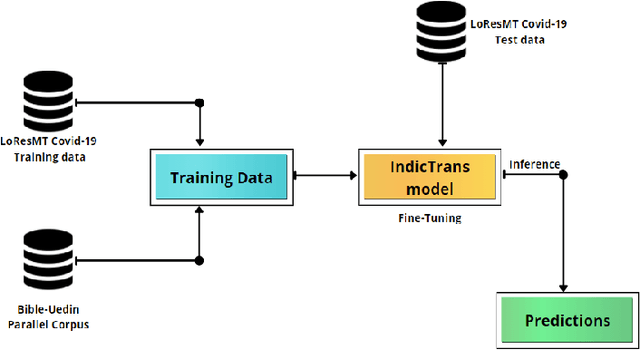
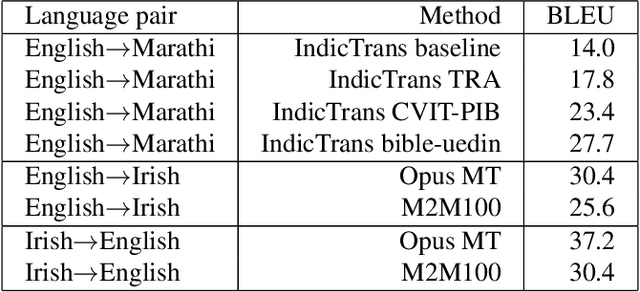
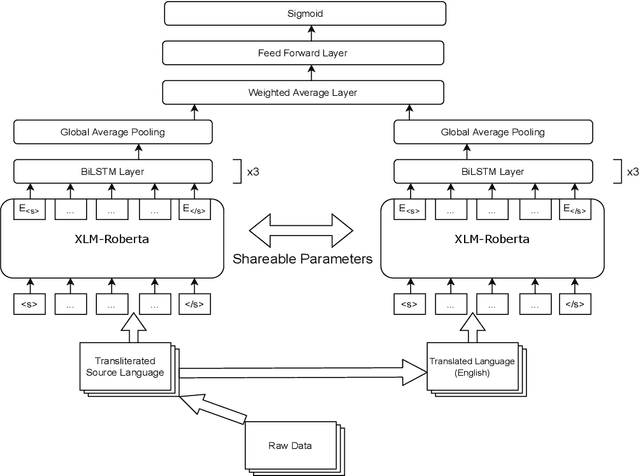
This paper reports the Machine Translation (MT) systems submitted by the IIITT team for the English->Marathi and English->Irish language pairs LoResMT 2021 shared task. The task focuses on getting exceptional translations for rather low-resourced languages like Irish and Marathi. We fine-tune IndicTrans, a pretrained multilingual NMT model for English->Marathi, using external parallel corpus as input for additional training. We have used a pretrained Helsinki-NLP Opus MT English->Irish model for the latter language pair. Our approaches yield relatively promising results on the BLEU metrics. Under the team name IIITT, our systems ranked 1, 1, and 2 in English->Marathi, Irish->English, and English->Irish, respectively.
Hope Speech detection in under-resourced Kannada language
Aug 10, 2021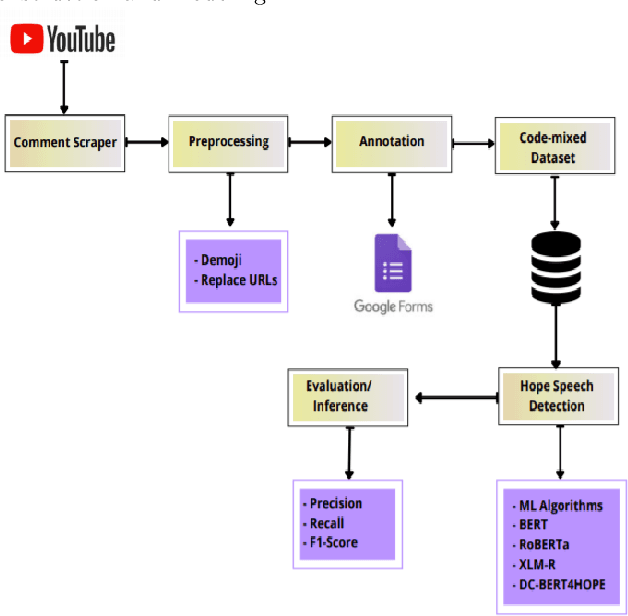
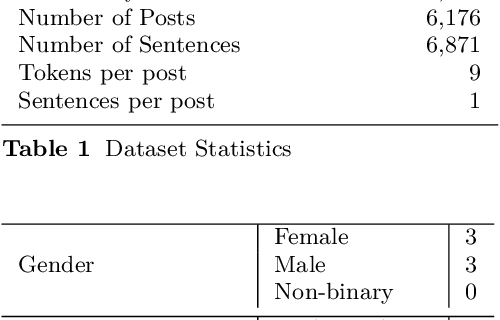
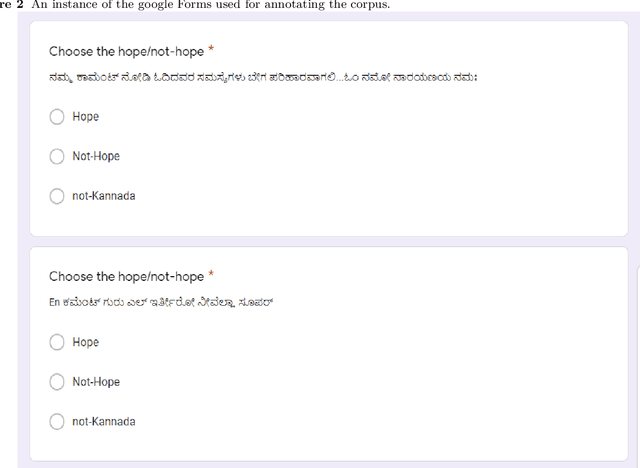
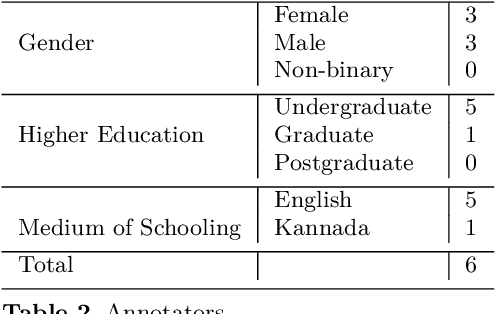
Numerous methods have been developed to monitor the spread of negativity in modern years by eliminating vulgar, offensive, and fierce comments from social media platforms. However, there are relatively lesser amounts of study that converges on embracing positivity, reinforcing supportive and reassuring content in online forums. Consequently, we propose creating an English-Kannada Hope speech dataset, KanHope and comparing several experiments to benchmark the dataset. The dataset consists of 6,176 user-generated comments in code mixed Kannada scraped from YouTube and manually annotated as bearing hope speech or Not-hope speech. In addition, we introduce DC-BERT4HOPE, a dual-channel model that uses the English translation of KanHope for additional training to promote hope speech detection. The approach achieves a weighted F1-score of 0.756, bettering other models. Henceforth, KanHope aims to instigate research in Kannada while broadly promoting researchers to take a pragmatic approach towards online content that encourages, positive, and supportive.
DravidianMultiModality: A Dataset for Multi-modal Sentiment Analysis in Tamil and Malayalam
Jun 09, 2021
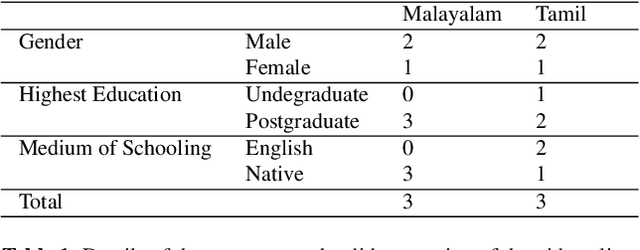

Human communication is inherently multimodal and asynchronous. Analyzing human emotions and sentiment is an emerging field of artificial intelligence. We are witnessing an increasing amount of multimodal content in local languages on social media about products and other topics. However, there are not many multimodal resources available for under-resourced Dravidian languages. Our study aims to create a multimodal sentiment analysis dataset for the under-resourced Tamil and Malayalam languages. First, we downloaded product or movies review videos from YouTube for Tamil and Malayalam. Next, we created captions for the videos with the help of annotators. Then we labelled the videos for sentiment, and verified the inter-annotator agreement using Fleiss's Kappa. This is the first multimodal sentiment analysis dataset for Tamil and Malayalam by volunteer annotators.