 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTamilEmo: Finegrained Emotion Detection Dataset for Tamil
Feb 09, 2022
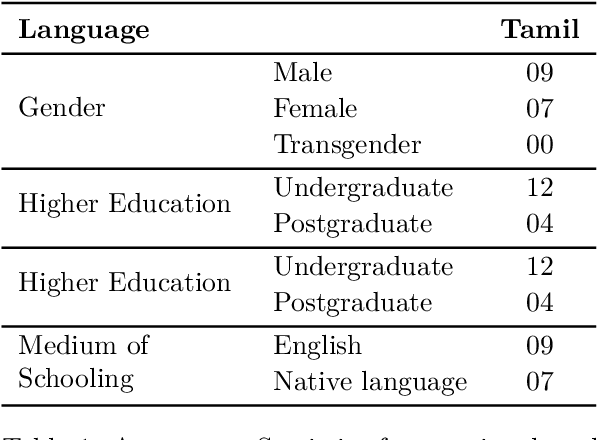

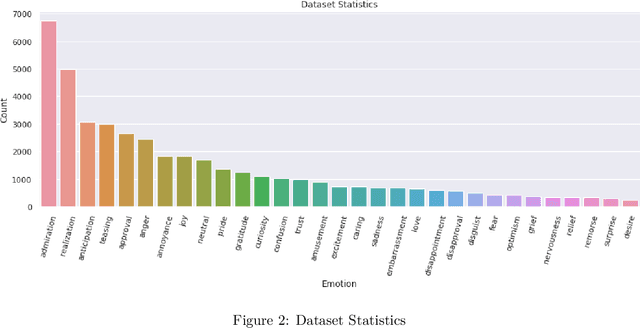
Emotional Analysis from textual input has been considered both a challenging and interesting task in Natural Language Processing. However, due to the lack of datasets in low-resource languages (i.e. Tamil), it is difficult to conduct research of high standard in this area. Therefore we introduce this labelled dataset (a largest manually annotated dataset of more than 42k Tamil YouTube comments, labelled for 31 emotions including neutral) for emotion recognition. The goal of this dataset is to improve emotion detection in multiple downstream tasks in Tamil. We have also created three different groupings of our emotions (3-class, 7-class and 31-class) and evaluated the model's performance on each category of the grouping. Our MURIL-base model has achieved a 0.60 macro average F1-score across our 3-class group dataset. With 7-class and 31-class groups, the Random Forest model performed well with a macro average F1-scores of 0.42 and 0.29 respectively.
Attentive fine-tuning of Transformers for Translation of low-resourced languages @LoResMT 2021
Aug 31, 2021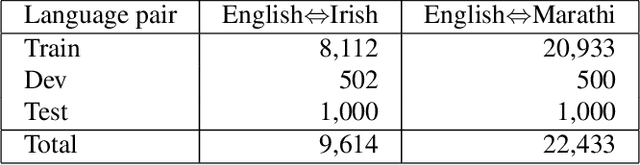
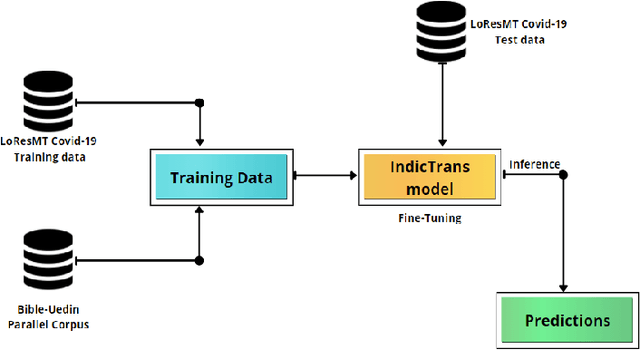
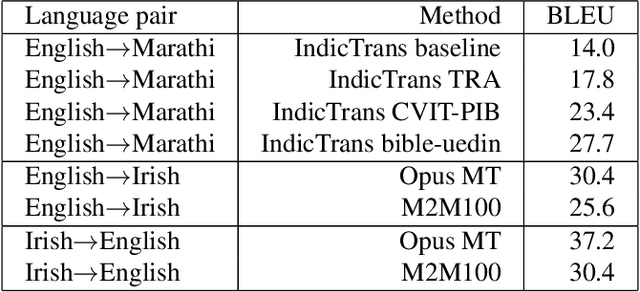
This paper reports the Machine Translation (MT) systems submitted by the IIITT team for the English->Marathi and English->Irish language pairs LoResMT 2021 shared task. The task focuses on getting exceptional translations for rather low-resourced languages like Irish and Marathi. We fine-tune IndicTrans, a pretrained multilingual NMT model for English->Marathi, using external parallel corpus as input for additional training. We have used a pretrained Helsinki-NLP Opus MT English->Irish model for the latter language pair. Our approaches yield relatively promising results on the BLEU metrics. Under the team name IIITT, our systems ranked 1, 1, and 2 in English->Marathi, Irish->English, and English->Irish, respectively.