 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTamilEmo: Finegrained Emotion Detection Dataset for Tamil
Feb 09, 2022
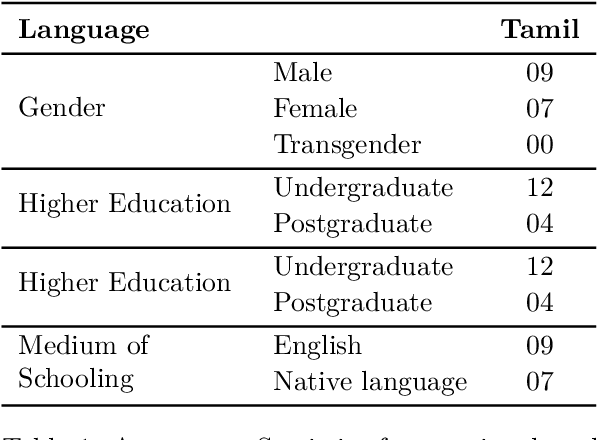

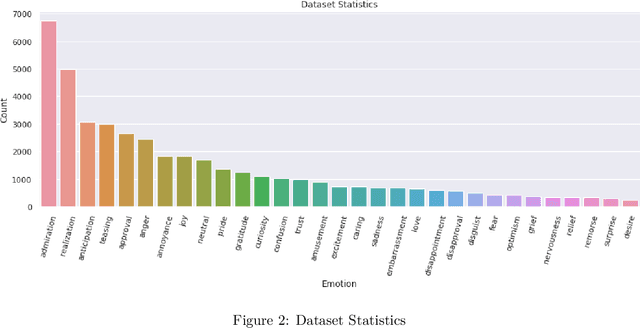
Emotional Analysis from textual input has been considered both a challenging and interesting task in Natural Language Processing. However, due to the lack of datasets in low-resource languages (i.e. Tamil), it is difficult to conduct research of high standard in this area. Therefore we introduce this labelled dataset (a largest manually annotated dataset of more than 42k Tamil YouTube comments, labelled for 31 emotions including neutral) for emotion recognition. The goal of this dataset is to improve emotion detection in multiple downstream tasks in Tamil. We have also created three different groupings of our emotions (3-class, 7-class and 31-class) and evaluated the model's performance on each category of the grouping. Our MURIL-base model has achieved a 0.60 macro average F1-score across our 3-class group dataset. With 7-class and 31-class groups, the Random Forest model performed well with a macro average F1-scores of 0.42 and 0.29 respectively.
Hypers at ComMA@ICON: Modelling Aggressiveness, Gender Bias and Communal Bias Identification
Jan 13, 2022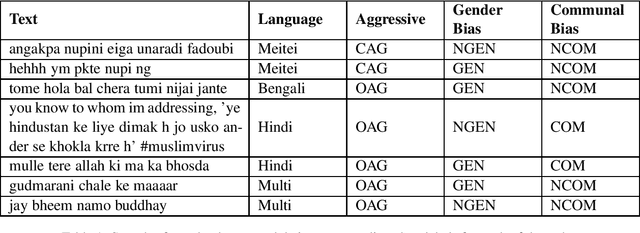


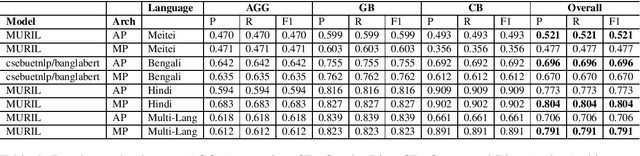
Due to the exponentially increasing reach of social media, it is essential to focus on its negative aspects as it can potentially divide society and incite people into violence. In this paper, we present our system description of work on the shared task ComMA@ICON, where we have to classify how aggressive the sentence is and if the sentence is gender-biased or communal biased. These three could be the primary reasons to cause significant problems in society. As team Hypers we have proposed an approach that utilizes different pretrained models with Attention and mean pooling methods. We were able to get Rank 3 with 0.223 Instance F1 score on Bengali, Rank 2 with 0.322 Instance F1 score on Multi-lingual set, Rank 4 with 0.129 Instance F1 score on Meitei and Rank 5 with 0.336 Instance F1 score on Hindi. The source code and the pretrained models of this work can be found here.
PSG@HASOC-Dravidian CodeMixFIRE2021: Pretrained Transformers for Offensive Language Identification in Tanglish
Oct 07, 2021

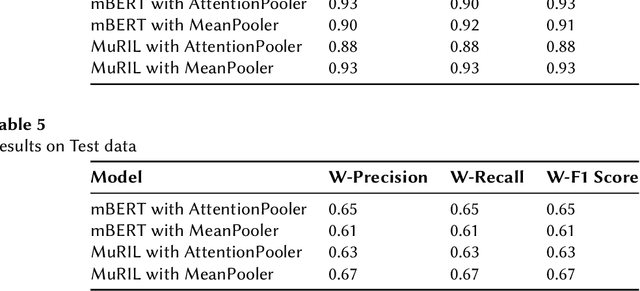
This paper describes the system submitted to Dravidian-Codemix-HASOC2021: Hate Speech and Offensive Language Identification in Dravidian Languages (Tamil-English and Malayalam-English). This task aims to identify offensive content in code-mixed comments/posts in Dravidian Languages collected from social media. Our approach utilizes pooling the last layers of pretrained transformer multilingual BERT for this task which helped us achieve rank nine on the leaderboard with a weighted average score of 0.61 for the Tamil-English dataset in subtask B. After the task deadline, we sampled the dataset uniformly and used the MuRIL pretrained model, which helped us achieve a weighted average score of 0.67, the top score in the leaderboard. Furthermore, our approach to utilizing the pretrained models helps reuse our models for the same task with a different dataset. Our code and models are available in https://github.com/seanbenhur/tanglish-offensive-language-identification