 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSG@HASOC-Dravidian CodeMixFIRE2021: Pretrained Transformers for Offensive Language Identification in Tanglish
Paper and Code


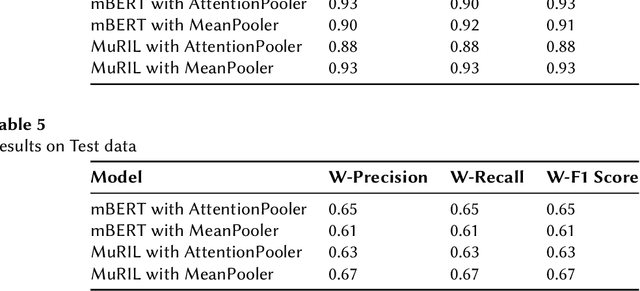
This paper describes the system submitted to Dravidian-Codemix-HASOC2021: Hate Speech and Offensive Language Identification in Dravidian Languages (Tamil-English and Malayalam-English). This task aims to identify offensive content in code-mixed comments/posts in Dravidian Languages collected from social media. Our approach utilizes pooling the last layers of pretrained transformer multilingual BERT for this task which helped us achieve rank nine on the leaderboard with a weighted average score of 0.61 for the Tamil-English dataset in subtask B. After the task deadline, we sampled the dataset uniformly and used the MuRIL pretrained model, which helped us achieve a weighted average score of 0.67, the top score in the leaderboard. Furthermore, our approach to utilizing the pretrained models helps reuse our models for the same task with a different dataset. Our code and models are available in https://github.com/seanbenhur/tanglish-offensive-language-identification