 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMLFormer: A Dual Decoder Transformer with Switching Point Learning for Code-Mixed Language Modeling
May 19, 2025Code-mixed languages, characterized by frequent within-sentence language transitions, present structural challenges that standard language models fail to address. In this work, we propose CMLFormer, an enhanced multi-layer dual-decoder Transformer with a shared encoder and synchronized decoder cross-attention, designed to model the linguistic and semantic dynamics of code-mixed text. CMLFormer is pre-trained on an augmented Hinglish corpus with switching point and translation annotations with multiple new objectives specifically aimed at capturing switching behavior, cross-lingual structure, and code-mixing complexity. Our experiments show that CMLFormer improves F1 score, precision, and accuracy over other approaches on the HASOC-2021 benchmark under select pre-training setups. Attention analyses further show that it can identify and attend to switching points, validating its sensitivity to code-mixed structure. These results demonstrate the effectiveness of CMLFormer's architecture and multi-task pre-training strategy for modeling code-mixed languages.
AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting
May 11, 2024


Knowledge distillation, a widely used model compression technique, works on the basis of transferring knowledge from a cumbersome teacher model to a lightweight student model. The technique involves jointly optimizing the task specific and knowledge distillation losses with a weight assigned to them. Despite these weights playing a crucial role in the performance of the distillation process, current methods provide equal weight to both losses, leading to suboptimal performance. In this paper, we propose Adaptive Knowledge Distillation, a novel technique inspired by curriculum learning to adaptively weigh the losses at instance level. This technique goes by the notion that sample difficulty increases with teacher loss. Our method follows a plug-and-play paradigm that can be applied on top of any task-specific and distillation objectives. Experiments show that our method performs better than conventional knowledge distillation method and existing instance-level loss functions.
Hypers at ComMA@ICON: Modelling Aggressiveness, Gender Bias and Communal Bias Identification
Jan 13, 2022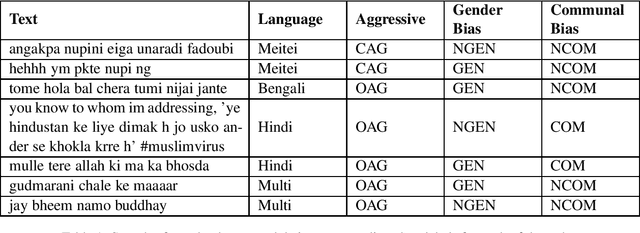


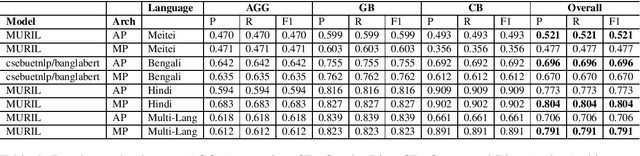
Due to the exponentially increasing reach of social media, it is essential to focus on its negative aspects as it can potentially divide society and incite people into violence. In this paper, we present our system description of work on the shared task ComMA@ICON, where we have to classify how aggressive the sentence is and if the sentence is gender-biased or communal biased. These three could be the primary reasons to cause significant problems in society. As team Hypers we have proposed an approach that utilizes different pretrained models with Attention and mean pooling methods. We were able to get Rank 3 with 0.223 Instance F1 score on Bengali, Rank 2 with 0.322 Instance F1 score on Multi-lingual set, Rank 4 with 0.129 Instance F1 score on Meitei and Rank 5 with 0.336 Instance F1 score on Hindi. The source code and the pretrained models of this work can be found here.