 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTamilEmo: Finegrained Emotion Detection Dataset for Tamil
Feb 09, 2022
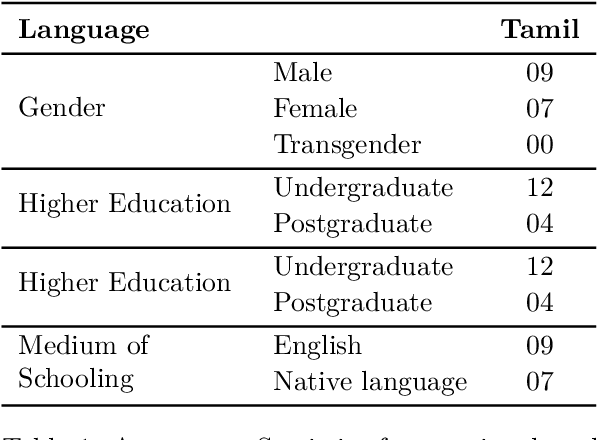

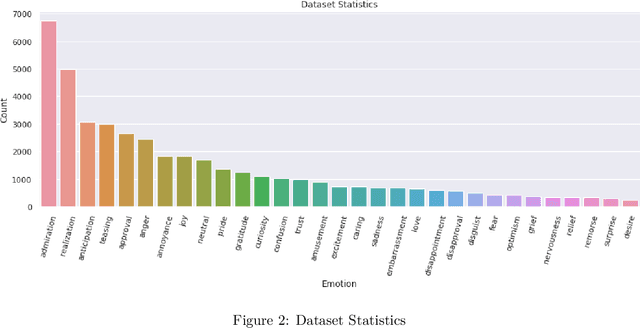
Emotional Analysis from textual input has been considered both a challenging and interesting task in Natural Language Processing. However, due to the lack of datasets in low-resource languages (i.e. Tamil), it is difficult to conduct research of high standard in this area. Therefore we introduce this labelled dataset (a largest manually annotated dataset of more than 42k Tamil YouTube comments, labelled for 31 emotions including neutral) for emotion recognition. The goal of this dataset is to improve emotion detection in multiple downstream tasks in Tamil. We have also created three different groupings of our emotions (3-class, 7-class and 31-class) and evaluated the model's performance on each category of the grouping. Our MURIL-base model has achieved a 0.60 macro average F1-score across our 3-class group dataset. With 7-class and 31-class groups, the Random Forest model performed well with a macro average F1-scores of 0.42 and 0.29 respectively.
Pegasus@Dravidian-CodeMix-HASOC2021: Analyzing Social Media Content for Detection of Offensive Text
Nov 18, 2021
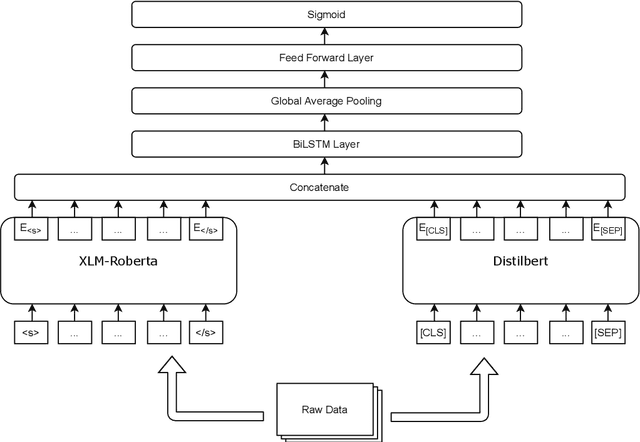

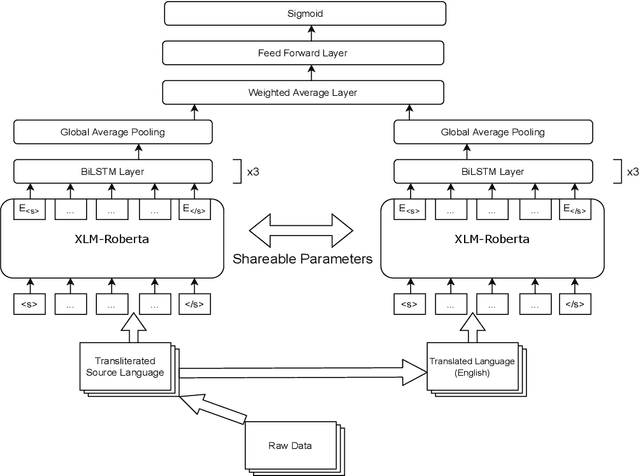
To tackle the conundrum of detecting offensive comments/posts which are considerably informal, unstructured, miswritten and code-mixed, we introduce two inventive methods in this research paper. Offensive comments/posts on the social media platforms, can affect an individual, a group or underage alike. In order to classify comments/posts in two popular Dravidian languages, Tamil and Malayalam, as a part of the HASOC - DravidianCodeMix FIRE 2021 shared task, we employ two Transformer-based prototypes which successfully stood in the top 8 for all the tasks. The codes for our approach can be viewed and utilized.
Attentive fine-tuning of Transformers for Translation of low-resourced languages @LoResMT 2021
Aug 31, 2021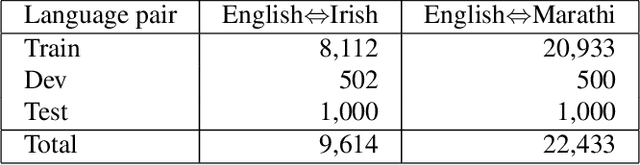
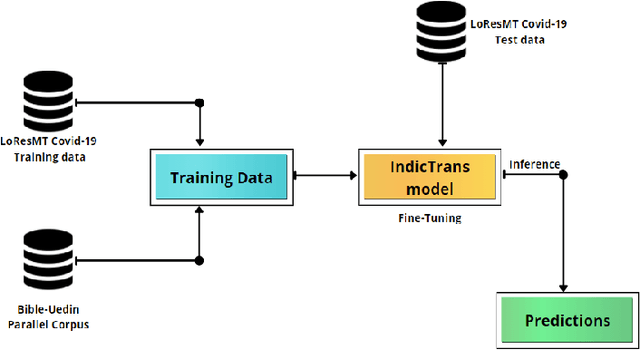
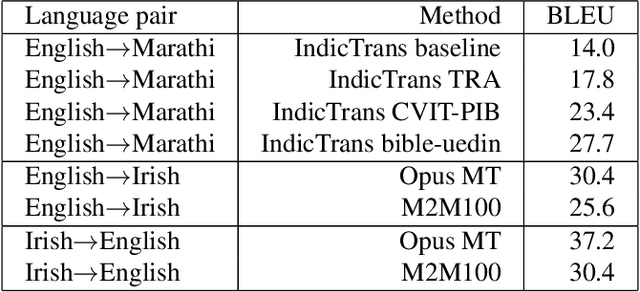
This paper reports the Machine Translation (MT) systems submitted by the IIITT team for the English->Marathi and English->Irish language pairs LoResMT 2021 shared task. The task focuses on getting exceptional translations for rather low-resourced languages like Irish and Marathi. We fine-tune IndicTrans, a pretrained multilingual NMT model for English->Marathi, using external parallel corpus as input for additional training. We have used a pretrained Helsinki-NLP Opus MT English->Irish model for the latter language pair. Our approaches yield relatively promising results on the BLEU metrics. Under the team name IIITT, our systems ranked 1, 1, and 2 in English->Marathi, Irish->English, and English->Irish, respectively.
Offensive Language Identification in Low-resourced Code-mixed Dravidian languages using Pseudo-labeling
Aug 27, 2021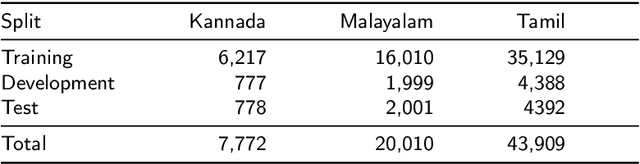
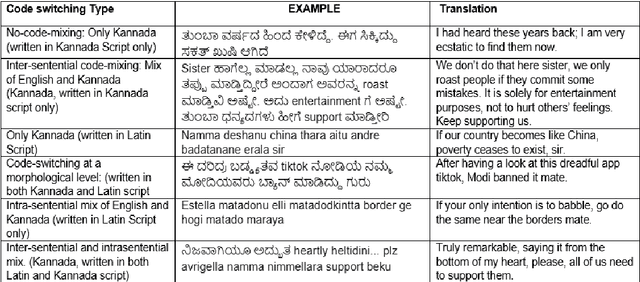

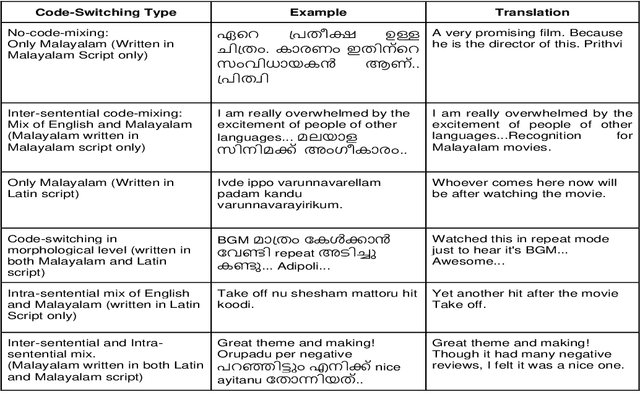
Social media has effectively become the prime hub of communication and digital marketing. As these platforms enable the free manifestation of thoughts and facts in text, images and video, there is an extensive need to screen them to protect individuals and groups from offensive content targeted at them. Our work intends to classify codemixed social media comments/posts in the Dravidian languages of Tamil, Kannada, and Malayalam. We intend to improve offensive language identification by generating pseudo-labels on the dataset. A custom dataset is constructed by transliterating all the code-mixed texts into the respective Dravidian language, either Kannada, Malayalam, or Tamil and then generating pseudo-labels for the transliterated dataset. The two datasets are combined using the generated pseudo-labels to create a custom dataset called CMTRA. As Dravidian languages are under-resourced, our approach increases the amount of training data for the language models. We fine-tune several recent pretrained language models on the newly constructed dataset. We extract the pretrained language embeddings and pass them onto recurrent neural networks. We observe that fine-tuning ULMFiT on the custom dataset yields the best results on the code-mixed test sets of all three languages. Our approach yields the best results among the benchmarked models on Tamil-English, achieving a weighted F1-Score of 0.7934 while scoring competitive weighted F1-Scores of 0.9624 and 0.7306 on the code-mixed test sets of Malayalam-English and Kannada-English, respectively.
Hope Speech detection in under-resourced Kannada language
Aug 10, 2021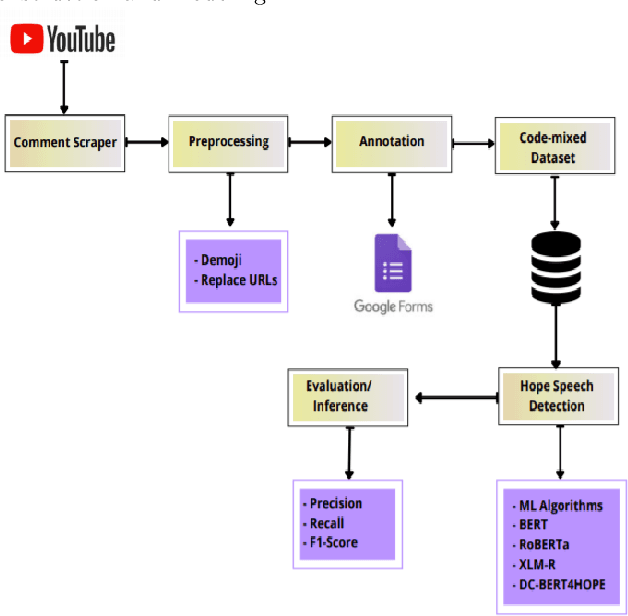
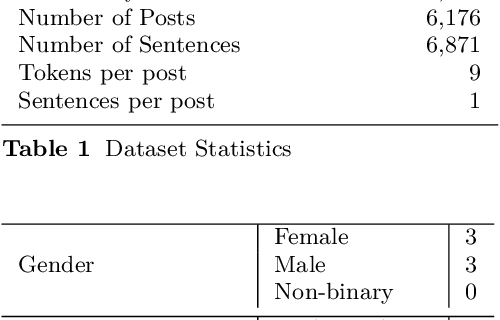
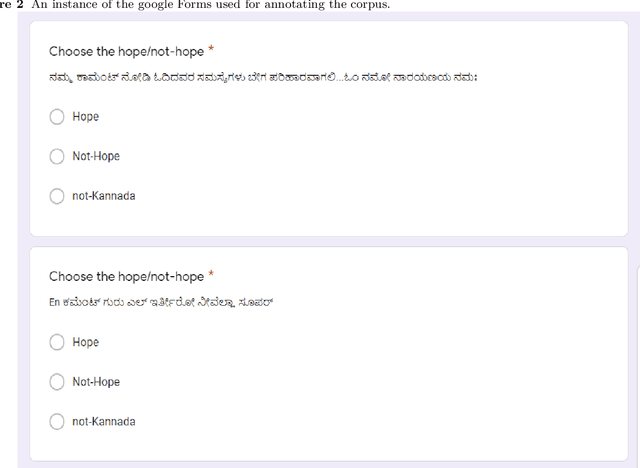
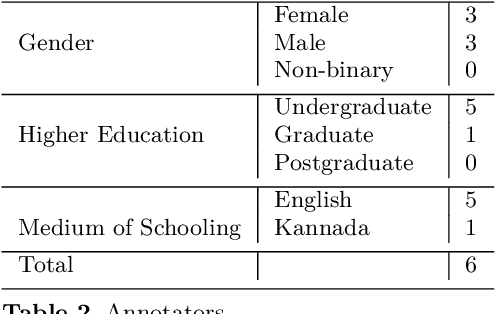
Numerous methods have been developed to monitor the spread of negativity in modern years by eliminating vulgar, offensive, and fierce comments from social media platforms. However, there are relatively lesser amounts of study that converges on embracing positivity, reinforcing supportive and reassuring content in online forums. Consequently, we propose creating an English-Kannada Hope speech dataset, KanHope and comparing several experiments to benchmark the dataset. The dataset consists of 6,176 user-generated comments in code mixed Kannada scraped from YouTube and manually annotated as bearing hope speech or Not-hope speech. In addition, we introduce DC-BERT4HOPE, a dual-channel model that uses the English translation of KanHope for additional training to promote hope speech detection. The approach achieves a weighted F1-score of 0.756, bettering other models. Henceforth, KanHope aims to instigate research in Kannada while broadly promoting researchers to take a pragmatic approach towards online content that encourages, positive, and supportive.