 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePegasus@Dravidian-CodeMix-HASOC2021: Analyzing Social Media Content for Detection of Offensive Text
Nov 18, 2021
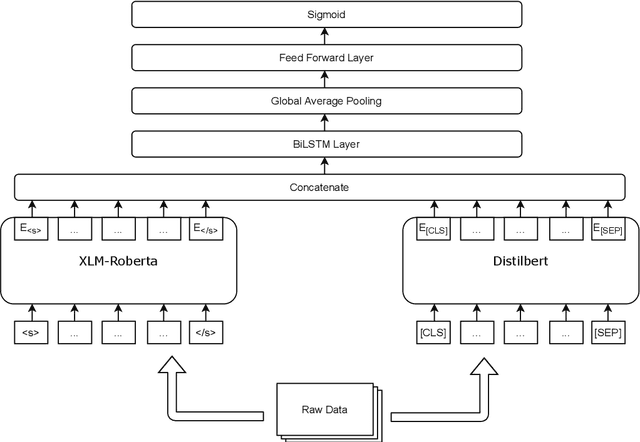

To tackle the conundrum of detecting offensive comments/posts which are considerably informal, unstructured, miswritten and code-mixed, we introduce two inventive methods in this research paper. Offensive comments/posts on the social media platforms, can affect an individual, a group or underage alike. In order to classify comments/posts in two popular Dravidian languages, Tamil and Malayalam, as a part of the HASOC - DravidianCodeMix FIRE 2021 shared task, we employ two Transformer-based prototypes which successfully stood in the top 8 for all the tasks. The codes for our approach can be viewed and utilized.
Offensive Language Identification in Low-resourced Code-mixed Dravidian languages using Pseudo-labeling
Aug 27, 2021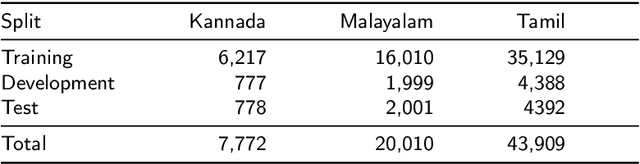
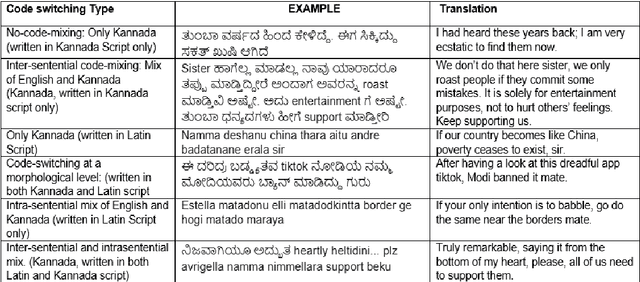

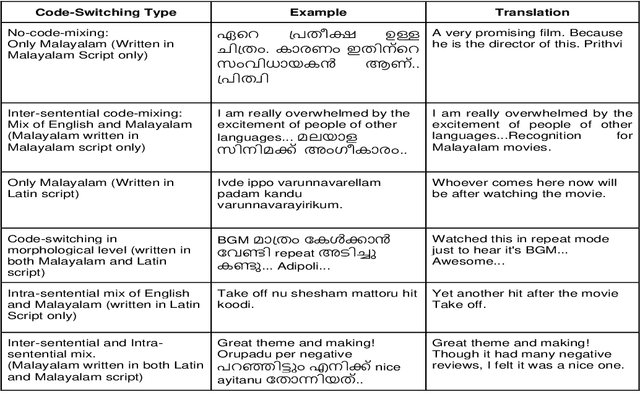
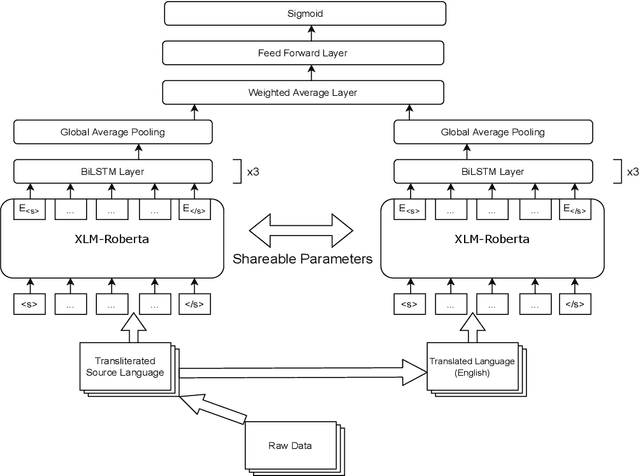
Social media has effectively become the prime hub of communication and digital marketing. As these platforms enable the free manifestation of thoughts and facts in text, images and video, there is an extensive need to screen them to protect individuals and groups from offensive content targeted at them. Our work intends to classify codemixed social media comments/posts in the Dravidian languages of Tamil, Kannada, and Malayalam. We intend to improve offensive language identification by generating pseudo-labels on the dataset. A custom dataset is constructed by transliterating all the code-mixed texts into the respective Dravidian language, either Kannada, Malayalam, or Tamil and then generating pseudo-labels for the transliterated dataset. The two datasets are combined using the generated pseudo-labels to create a custom dataset called CMTRA. As Dravidian languages are under-resourced, our approach increases the amount of training data for the language models. We fine-tune several recent pretrained language models on the newly constructed dataset. We extract the pretrained language embeddings and pass them onto recurrent neural networks. We observe that fine-tuning ULMFiT on the custom dataset yields the best results on the code-mixed test sets of all three languages. Our approach yields the best results among the benchmarked models on Tamil-English, achieving a weighted F1-Score of 0.7934 while scoring competitive weighted F1-Scores of 0.9624 and 0.7306 on the code-mixed test sets of Malayalam-English and Kannada-English, respectively.