 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePegasus@Dravidian-CodeMix-HASOC2021: Analyzing Social Media Content for Detection of Offensive Text
Nov 18, 2021
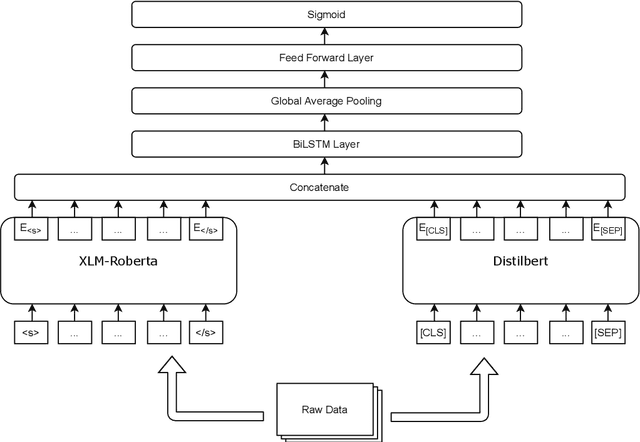

To tackle the conundrum of detecting offensive comments/posts which are considerably informal, unstructured, miswritten and code-mixed, we introduce two inventive methods in this research paper. Offensive comments/posts on the social media platforms, can affect an individual, a group or underage alike. In order to classify comments/posts in two popular Dravidian languages, Tamil and Malayalam, as a part of the HASOC - DravidianCodeMix FIRE 2021 shared task, we employ two Transformer-based prototypes which successfully stood in the top 8 for all the tasks. The codes for our approach can be viewed and utilized.
IIITT@Dravidian-CodeMix-FIRE2021: Transliterate or translate? Sentiment analysis of code-mixed text in Dravidian languages
Nov 15, 2021


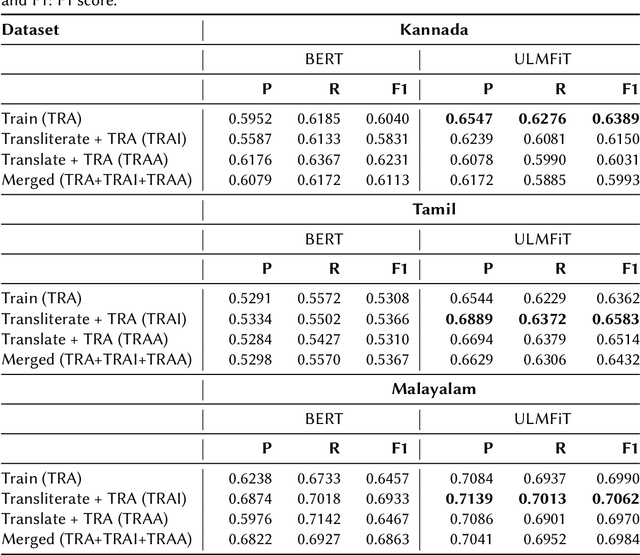
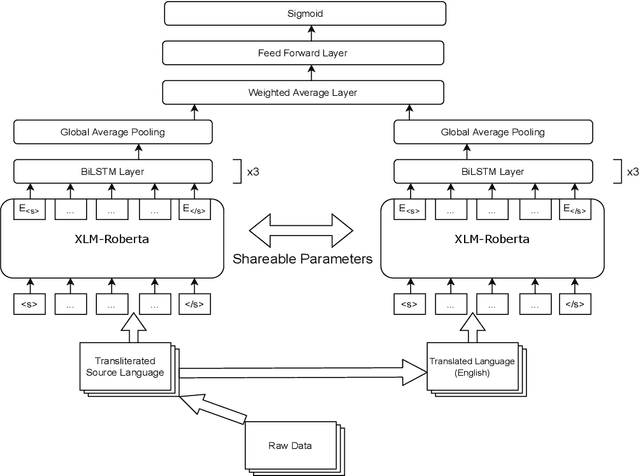
Sentiment analysis of social media posts and comments for various marketing and emotional purposes is gaining recognition. With the increasing presence of code-mixed content in various native languages, there is a need for ardent research to produce promising results. This research paper bestows a tiny contribution to this research in the form of sentiment analysis of code-mixed social media comments in the popular Dravidian languages Kannada, Tamil and Malayalam. It describes the work for the shared task conducted by Dravidian-CodeMix at FIRE 2021 by employing pre-trained models like ULMFiT and multilingual BERT fine-tuned on the code-mixed dataset, transliteration (TRAI) of the same, English translations (TRAA) of the TRAI data and the combination of all the three. The results are recorded in this research paper where the best models stood 4th, 5th and 10th ranks in the Tamil, Kannada and Malayalam tasks respectively.
Attentive fine-tuning of Transformers for Translation of low-resourced languages @LoResMT 2021
Aug 31, 2021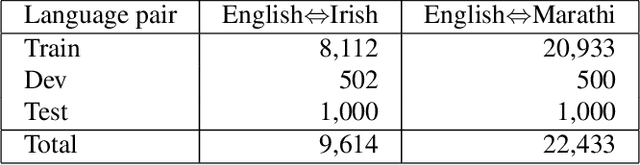
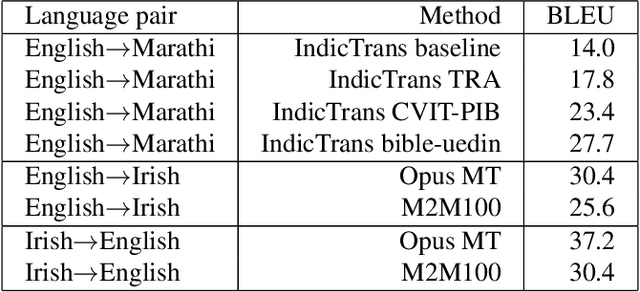
This paper reports the Machine Translation (MT) systems submitted by the IIITT team for the English->Marathi and English->Irish language pairs LoResMT 2021 shared task. The task focuses on getting exceptional translations for rather low-resourced languages like Irish and Marathi. We fine-tune IndicTrans, a pretrained multilingual NMT model for English->Marathi, using external parallel corpus as input for additional training. We have used a pretrained Helsinki-NLP Opus MT English->Irish model for the latter language pair. Our approaches yield relatively promising results on the BLEU metrics. Under the team name IIITT, our systems ranked 1, 1, and 2 in English->Marathi, Irish->English, and English->Irish, respectively.
Offensive Language Identification in Low-resourced Code-mixed Dravidian languages using Pseudo-labeling
Aug 27, 2021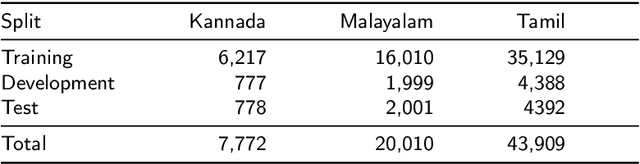
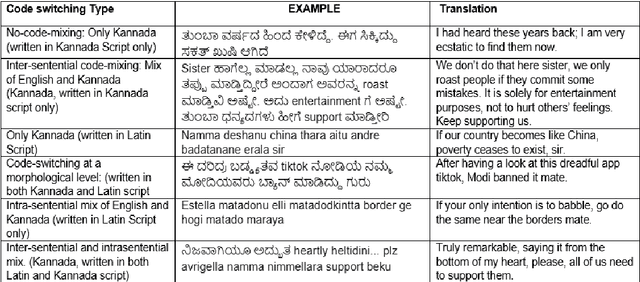

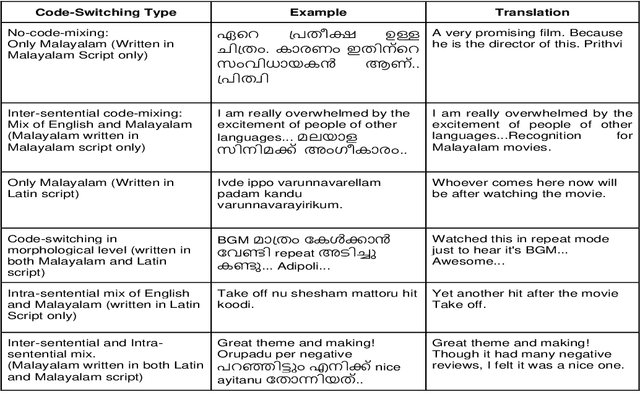
Social media has effectively become the prime hub of communication and digital marketing. As these platforms enable the free manifestation of thoughts and facts in text, images and video, there is an extensive need to screen them to protect individuals and groups from offensive content targeted at them. Our work intends to classify codemixed social media comments/posts in the Dravidian languages of Tamil, Kannada, and Malayalam. We intend to improve offensive language identification by generating pseudo-labels on the dataset. A custom dataset is constructed by transliterating all the code-mixed texts into the respective Dravidian language, either Kannada, Malayalam, or Tamil and then generating pseudo-labels for the transliterated dataset. The two datasets are combined using the generated pseudo-labels to create a custom dataset called CMTRA. As Dravidian languages are under-resourced, our approach increases the amount of training data for the language models. We fine-tune several recent pretrained language models on the newly constructed dataset. We extract the pretrained language embeddings and pass them onto recurrent neural networks. We observe that fine-tuning ULMFiT on the custom dataset yields the best results on the code-mixed test sets of all three languages. Our approach yields the best results among the benchmarked models on Tamil-English, achieving a weighted F1-Score of 0.7934 while scoring competitive weighted F1-Scores of 0.9624 and 0.7306 on the code-mixed test sets of Malayalam-English and Kannada-English, respectively.
IIITT@LT-EDI-EACL2021-Hope Speech Detection: There is always Hope in Transformers
Apr 19, 2021
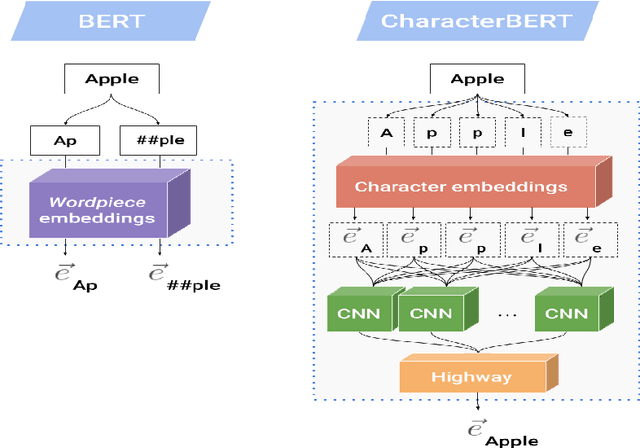
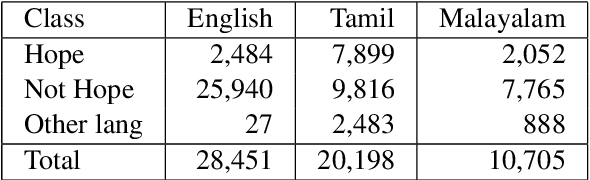

In a world filled with serious challenges like climate change, religious and political conflicts, global pandemics, terrorism, and racial discrimination, an internet full of hate speech, abusive and offensive content is the last thing we desire for. In this paper, we work to identify and promote positive and supportive content on these platforms. We work with several transformer-based models to classify social media comments as hope speech or not-hope speech in English, Malayalam and Tamil languages. This paper portrays our work for the Shared Task on Hope Speech Detection for Equality, Diversity, and Inclusion at LT-EDI 2021- EACL 2021.