 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIIITT@Dravidian-CodeMix-FIRE2021: Transliterate or translate? Sentiment analysis of code-mixed text in Dravidian languages
Nov 15, 2021


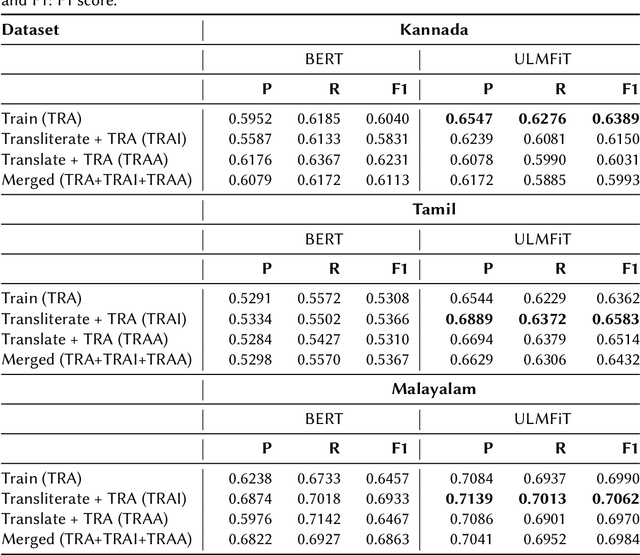
Sentiment analysis of social media posts and comments for various marketing and emotional purposes is gaining recognition. With the increasing presence of code-mixed content in various native languages, there is a need for ardent research to produce promising results. This research paper bestows a tiny contribution to this research in the form of sentiment analysis of code-mixed social media comments in the popular Dravidian languages Kannada, Tamil and Malayalam. It describes the work for the shared task conducted by Dravidian-CodeMix at FIRE 2021 by employing pre-trained models like ULMFiT and multilingual BERT fine-tuned on the code-mixed dataset, transliteration (TRAI) of the same, English translations (TRAA) of the TRAI data and the combination of all the three. The results are recorded in this research paper where the best models stood 4th, 5th and 10th ranks in the Tamil, Kannada and Malayalam tasks respectively.
A Survey of Voice Translation Methodologies - Acoustic Dialect Decoder
Oct 13, 2016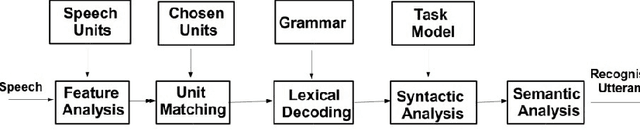
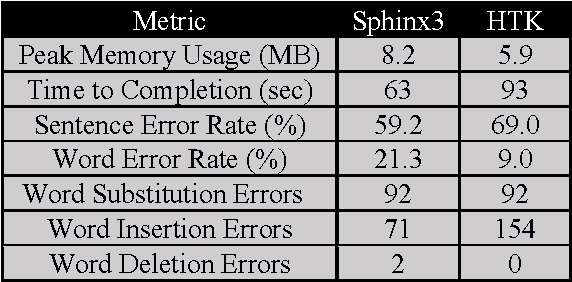
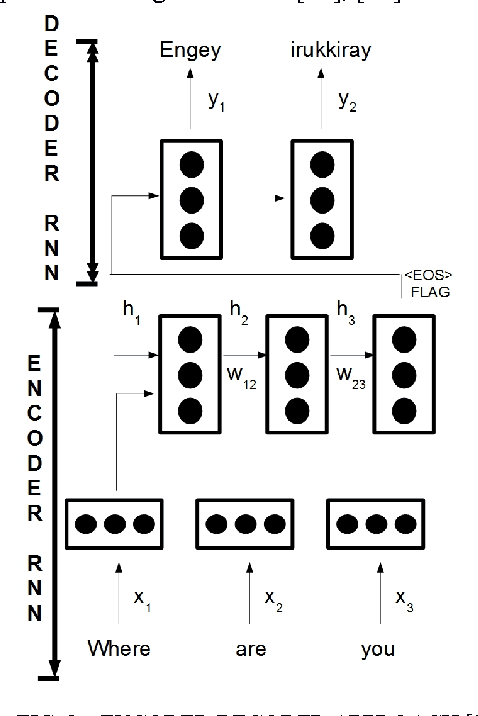
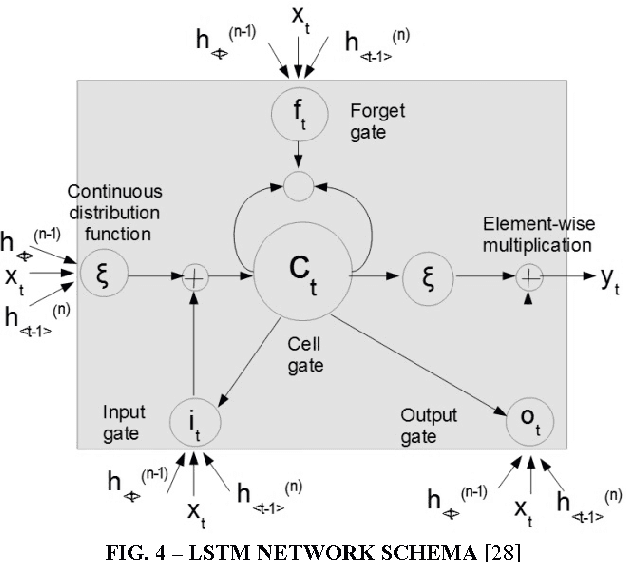
Speech Translation has always been about giving source text or audio input and waiting for system to give translated output in desired form. In this paper, we present the Acoustic Dialect Decoder (ADD) - a voice to voice ear-piece translation device. We introduce and survey the recent advances made in the field of Speech Engineering, to employ in the ADD, particularly focusing on the three major processing steps of Recognition, Translation and Synthesis. We tackle the problem of machine understanding of natural language by designing a recognition unit for source audio to text, a translation unit for source language text to target language text, and a synthesis unit for target language text to target language speech. Speech from the surroundings will be recorded by the recognition unit present on the ear-piece and translation will start as soon as one sentence is successfully read. This way, we hope to give translated output as and when input is being read. The recognition unit will use Hidden Markov Models (HMMs) Based Tool-Kit (HTK), hybrid RNN systems with gated memory cells, and the synthesis unit, HMM based speech synthesis system HTS. This system will initially be built as an English to Tamil translation device.
* (8 pages, 7 figures, IEEE Digital Xplore paper)