 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorizon Activation Mapping for Neural Networks in Time Series Forecasting
Jan 05, 2026Neural networks for time series forecasting have relied on error metrics and architecture-specific interpretability approaches for model selection that don't apply across models of different families. To interpret forecasting models agnostic to the types of layers across state-of-the-art model families, we introduce Horizon Activation Mapping (HAM), a visual interpretability technique inspired by grad-CAM that uses gradient norm averages to study the horizon's subseries where grad-CAM studies attention maps over image data. We introduce causal and anti-causal modes to calculate gradient update norm averages across subseries at every timestep and lines of proportionality signifying uniform distributions of the norm averages. Optimization landscape studies with respect to changes in batch sizes, early stopping, train-val-test splits, univariate forecasting and dropouts are studied with respect to performances and subseries in HAM. Interestingly, batch size based differences in activities seem to indicate potential for existence of an exponential approximation across them per epoch relative to each other. Multivariate forecasting models including MLP-based CycleNet, N-Linear, N-HITS, self attention-based FEDformer, Pyraformer, SSM-based SpaceTime and diffusion-based Multi-Resolution DDPM over different horizon sizes trained over the ETTm2 dataset are used for HAM plots in this study. NHITS' neural approximation theorem and SpaceTime's exponential autoregressive activities have been attributed to trends in HAM plots over their training, validation and test sets. In general, HAM can be used for granular model selection, validation set choices and comparisons across different neural network model families.
A Review of the Long Horizon Forecasting Problem in Time Series Analysis
Jun 15, 2025The long horizon forecasting (LHF) problem has come up in the time series literature for over the last 35 years or so. This review covers aspects of LHF in this period and how deep learning has incorporated variants of trend, seasonality, fourier and wavelet transforms, misspecification bias reduction and bandpass filters while contributing using convolutions, residual connections, sparsity reduction, strided convolutions, attention masks, SSMs, normalization methods, low-rank approximations and gating mechanisms. We highlight time series decomposition techniques, input data preprocessing and dataset windowing schemes that improve performance. Multi-layer perceptron models, recurrent neural network hybrids, self-attention models that improve and/or address the performances of the LHF problem are described, with an emphasis on the feature space construction. Ablation studies are conducted over the ETTm2 dataset in the multivariate and univariate high useful load (HUFL) forecasting contexts, evaluated over the last 4 months of the dataset. The heatmaps of MSE averages per time step over test set series in the horizon show that there is a steady increase in the error proportionate to its length except with xLSTM and Triformer models and motivate LHF as an error propagation problem. The trained models are available here: https://bit.ly/LHFModelZoo
A Review of Intelligent Practices for Irrigation Prediction
Dec 07, 2016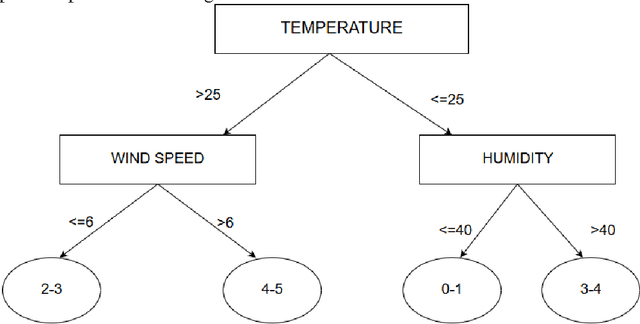
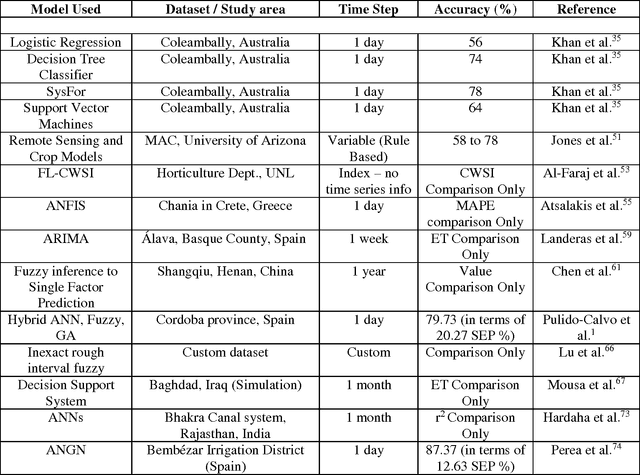
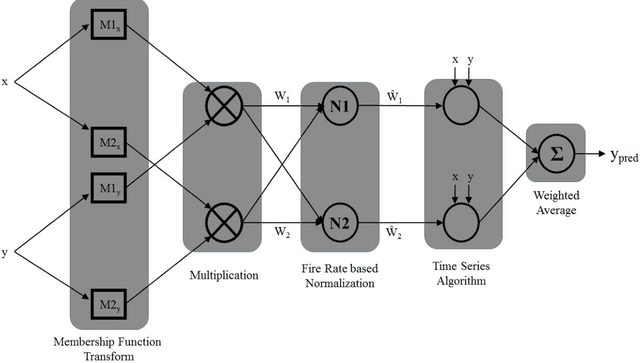
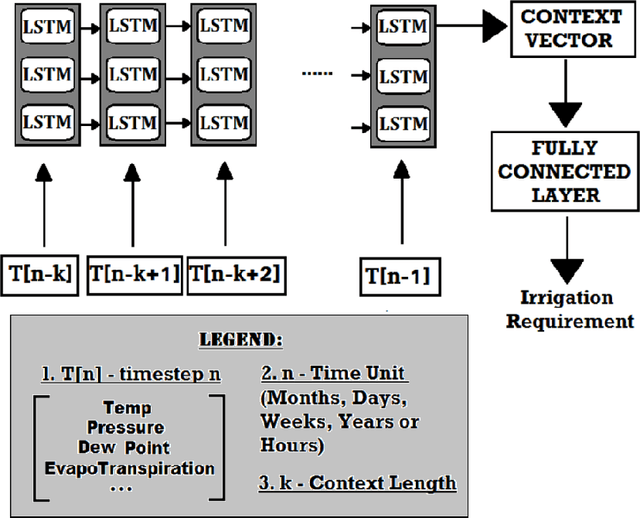
Population growth and increasing droughts are creating unprecedented strain on the continued availability of water resources. Since irrigation is a major consumer of fresh water, wastage of resources in this sector could have strong consequences. To address this issue, irrigation water management and prediction techniques need to be employed effectively and should be able to account for the variabilities present in the environment. The different techniques surveyed in this paper can be classified into two categories: computational and statistical. Computational methods deal with scientific correlations between physical parameters whereas statistical methods involve specific prediction algorithms that can be used to automate the process of irrigation water prediction. These algorithms interpret semantic relationships between the various parameters of temperature, pressure, evapotranspiration etc. and store them as numerical precomputed entities specific to the conditions and the area used as the data for the training corpus used to train it. We focus on reviewing the computational methods used to determine Evapotranspiration and its implications. We compare the efficiencies of different data mining and machine learning methods implemented in this area, such as Logistic Regression, Decision Tress Classifier, SysFor, Support Vector Machine(SVM), Fuzzy Logic techniques, Artifical Neural Networks(ANNs) and various hybrids of Genetic Algorithms (GA) applied to irrigation prediction. We also recommend a possible technique for the same based on its superior results in other such time series analysis tasks.
A Survey of Voice Translation Methodologies - Acoustic Dialect Decoder
Oct 13, 2016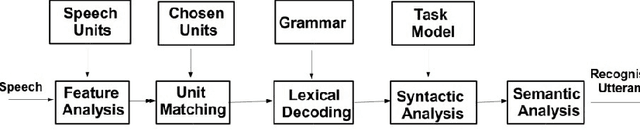
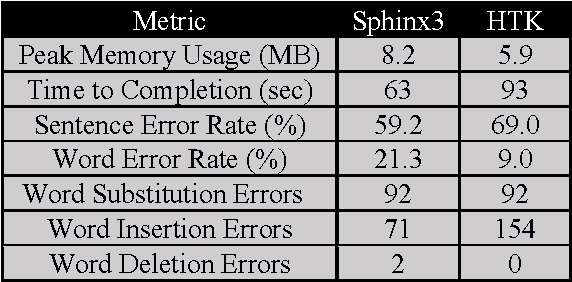
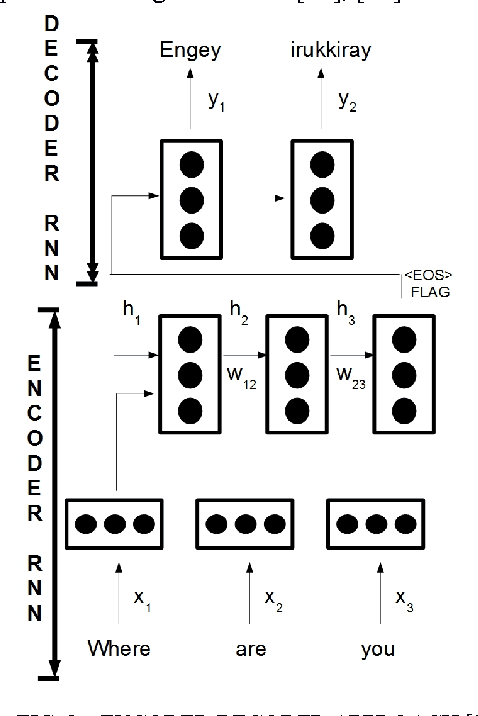
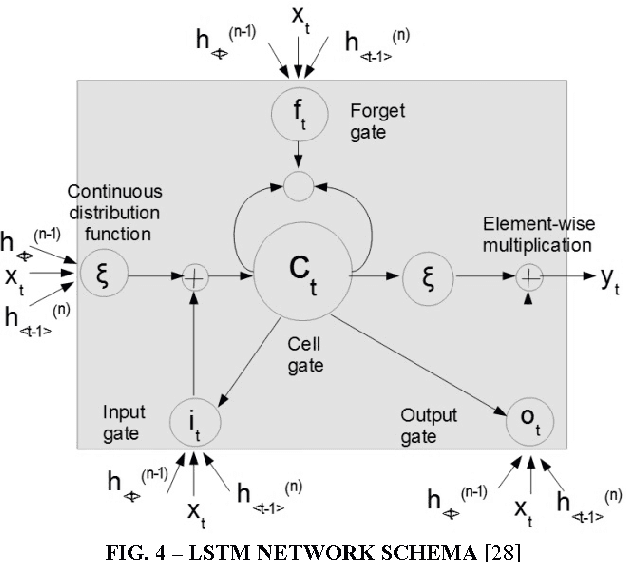
Speech Translation has always been about giving source text or audio input and waiting for system to give translated output in desired form. In this paper, we present the Acoustic Dialect Decoder (ADD) - a voice to voice ear-piece translation device. We introduce and survey the recent advances made in the field of Speech Engineering, to employ in the ADD, particularly focusing on the three major processing steps of Recognition, Translation and Synthesis. We tackle the problem of machine understanding of natural language by designing a recognition unit for source audio to text, a translation unit for source language text to target language text, and a synthesis unit for target language text to target language speech. Speech from the surroundings will be recorded by the recognition unit present on the ear-piece and translation will start as soon as one sentence is successfully read. This way, we hope to give translated output as and when input is being read. The recognition unit will use Hidden Markov Models (HMMs) Based Tool-Kit (HTK), hybrid RNN systems with gated memory cells, and the synthesis unit, HMM based speech synthesis system HTS. This system will initially be built as an English to Tamil translation device.
* (8 pages, 7 figures, IEEE Digital Xplore paper)