 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftware Metadata Classification based on Generative Artificial Intelligence
Oct 14, 2023This paper presents a novel approach to enhance the performance of binary code comment quality classification models through the application of Generative Artificial Intelligence (AI). By leveraging the OpenAI API, a dataset comprising 1239 newly generated code-comment pairs, extracted from various GitHub repositories and open-source projects, has been labelled as "Useful" or "Not Useful", and integrated into the existing corpus of 9048 pairs in the C programming language. Employing a cutting-edge Large Language Model Architecture, the generated dataset demonstrates notable improvements in model accuracy. Specifically, when incorporated into the Support Vector Machine (SVM) model, a 6% increase in precision is observed, rising from 0.79 to 0.85. Additionally, the Artificial Neural Network (ANN) model exhibits a 1.5% increase in recall, climbing from 0.731 to 0.746. This paper sheds light on the potential of Generative AI in augmenting code comment quality classification models. The results affirm the effectiveness of this methodology, indicating its applicability in broader contexts within software development and quality assurance domains. The findings underscore the significance of integrating generative techniques to advance the accuracy and efficacy of machine learning models in practical software engineering scenarios.
Findings of the Sentiment Analysis of Dravidian Languages in Code-Mixed Text
Nov 18, 2021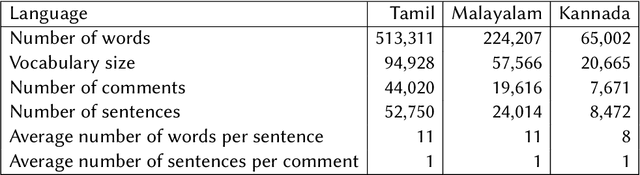
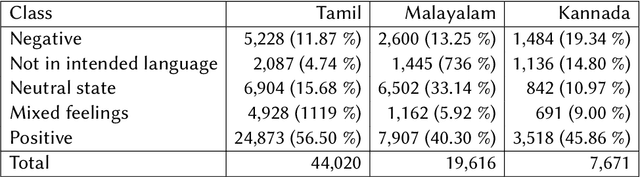
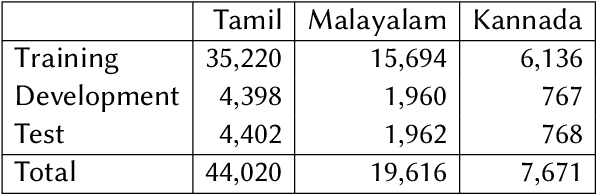
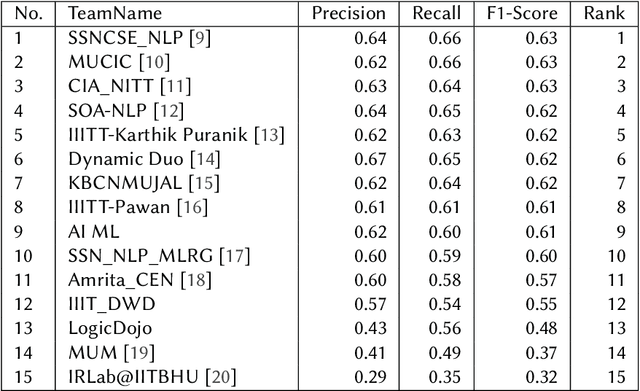
We present the results of the Dravidian-CodeMix shared task held at FIRE 2021, a track on sentiment analysis for Dravidian Languages in Code-Mixed Text. We describe the task, its organization, and the submitted systems. This shared task is the continuation of last year's Dravidian-CodeMix shared task held at FIRE 2020. This year's tasks included code-mixing at the intra-token and inter-token levels. Additionally, apart from Tamil and Malayalam, Kannada was also introduced. We received 22 systems for Tamil-English, 15 systems for Malayalam-English, and 15 for Kannada-English. The top system for Tamil-English, Malayalam-English and Kannada-English scored weighted average F1-score of 0.711, 0.804, and 0.630, respectively. In summary, the quality and quantity of the submission show that there is great interest in Dravidian languages in code-mixed setting and state of the art in this domain still needs more improvement.
Dataset for Identification of Homophobia and Transophobia in Multilingual YouTube Comments
Sep 01, 2021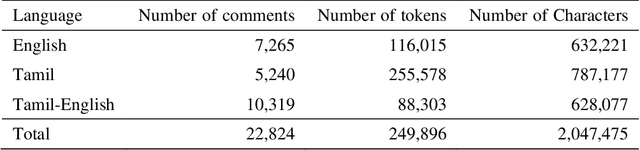
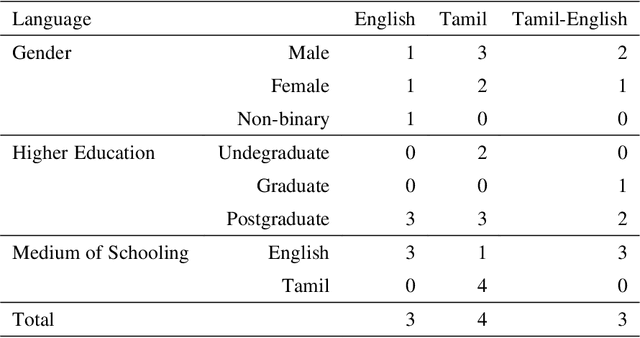
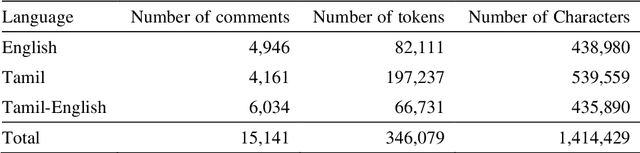
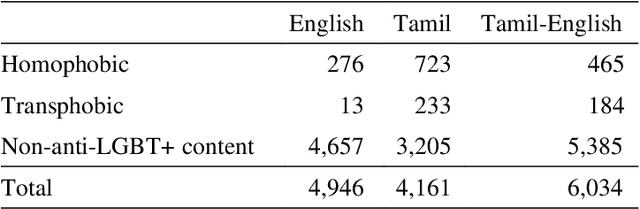
The increased proliferation of abusive content on social media platforms has a negative impact on online users. The dread, dislike, discomfort, or mistrust of lesbian, gay, transgender or bisexual persons is defined as homophobia/transphobia. Homophobic/transphobic speech is a type of offensive language that may be summarized as hate speech directed toward LGBT+ people, and it has been a growing concern in recent years. Online homophobia/transphobia is a severe societal problem that can make online platforms poisonous and unwelcome to LGBT+ people while also attempting to eliminate equality, diversity, and inclusion. We provide a new hierarchical taxonomy for online homophobia and transphobia, as well as an expert-labelled dataset that will allow homophobic/transphobic content to be automatically identified. We educated annotators and supplied them with comprehensive annotation rules because this is a sensitive issue, and we previously discovered that untrained crowdsourcing annotators struggle with diagnosing homophobia due to cultural and other prejudices. The dataset comprises 15,141 annotated multilingual comments. This paper describes the process of building the dataset, qualitative analysis of data, and inter-annotator agreement. In addition, we create baseline models for the dataset. To the best of our knowledge, our dataset is the first such dataset created. Warning: This paper contains explicit statements of homophobia, transphobia, stereotypes which may be distressing to some readers.
Offensive Language Identification in Low-resourced Code-mixed Dravidian languages using Pseudo-labeling
Aug 27, 2021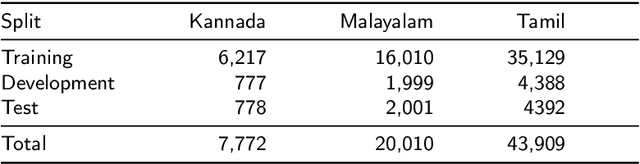
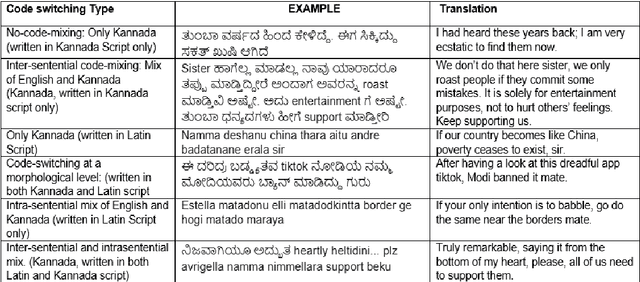

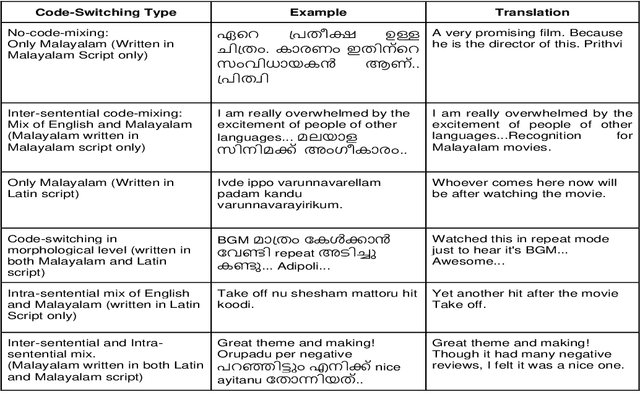
Social media has effectively become the prime hub of communication and digital marketing. As these platforms enable the free manifestation of thoughts and facts in text, images and video, there is an extensive need to screen them to protect individuals and groups from offensive content targeted at them. Our work intends to classify codemixed social media comments/posts in the Dravidian languages of Tamil, Kannada, and Malayalam. We intend to improve offensive language identification by generating pseudo-labels on the dataset. A custom dataset is constructed by transliterating all the code-mixed texts into the respective Dravidian language, either Kannada, Malayalam, or Tamil and then generating pseudo-labels for the transliterated dataset. The two datasets are combined using the generated pseudo-labels to create a custom dataset called CMTRA. As Dravidian languages are under-resourced, our approach increases the amount of training data for the language models. We fine-tune several recent pretrained language models on the newly constructed dataset. We extract the pretrained language embeddings and pass them onto recurrent neural networks. We observe that fine-tuning ULMFiT on the custom dataset yields the best results on the code-mixed test sets of all three languages. Our approach yields the best results among the benchmarked models on Tamil-English, achieving a weighted F1-Score of 0.7934 while scoring competitive weighted F1-Scores of 0.9624 and 0.7306 on the code-mixed test sets of Malayalam-English and Kannada-English, respectively.