 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Computational Model of Brain-Heart Interactions via HRV and EEG Feature
Jan 11, 2026The electroencephalogram (EEG) has been the gold standard for quantifying mental workload; however, due to its complexity and non-portability, it can be constraining. ECG signals, which are feasible on wearable equipment pieces such as headbands, present a promising method for cognitive state monitoring. This research explores whether electrocardiogram (ECG) signals are able to indicate mental workload consistently and act as surrogates for EEG-based cognitive indicators. This study investigates whether ECG-derived features can serve as surrogate indicators of cognitive load, a concept traditionally quantified using EEG. Using a publicly available multimodal dataset (OpenNeuro) of EEG and ECG recorded during working-memory and listening tasks, features of HRV and Catch22 descriptors are extracted from ECG, and spectral band-power with Catch22 features from EEG. A cross-modal regression framework based on XGBoost was trained to map ECG-derived HRV representations to EEG-derived cognitive features. In order to address data sparsity and model brain-heart interactions, we integrated the PSV-SDG to produce EEG-conditioned synthetic HRV time series.This addresses the challenge of inferring cognitive load solely from ECG-derived features using a combination of multimodal learning, signal processing, and synthetic data generation. These outcomes form a basis for light, interpretable machine learning models that are implemented through wearable biosensors in non-lab environments. Synthetic HRV inclusion enhances robustness, particularly in sparse data situations. Overall, this work is an initiation for building low-cost, explainable, and real-time cognitive monitoring systems for mental health, education, and human-computer interaction, with a focus on ageing and clinical populations.
Unveiling the Heart-Brain Connection: An Analysis of ECG in Cognitive Performance
Jan 04, 2026Understanding the interaction of neural and cardiac systems during cognitive activity is critical to advancing physiological computing. Although EEG has been the gold standard for assessing mental workload, its limited portability restricts its real-world use. Widely available ECG through wearable devices proposes a pragmatic alternative. This research investigates whether ECG signals can reliably reflect cognitive load and serve as proxies for EEG-based indicators. In this work, we present multimodal data acquired from two different paradigms involving working-memory and passive-listening tasks. For each modality, we extracted ECG time-domain HRV metrics and Catch22 descriptors against EEG spectral and Catch22 features, respectively. We propose a cross-modal XGBoost framework to project the ECG features onto EEG-representative cognitive spaces, thereby allowing workload inferences using only ECG. Our results show that ECG-derived projections expressively capture variation in cognitive states and provide good support for accurate classification. Our findings underpin ECG as an interpretable, real-time, wearable solution for everyday cognitive monitoring.
Tracking Articulatory Dynamics in Speech with a Fixed-Weight BiLSTM-CNN Architecture
Apr 25, 2025Speech production is a complex sequential process which involve the coordination of various articulatory features. Among them tongue being a highly versatile active articulator responsible for shaping airflow to produce targeted speech sounds that are intellectual, clear, and distinct. This paper presents a novel approach for predicting tongue and lip articulatory features involved in a given speech acoustics using a stacked Bidirectional Long Short-Term Memory (BiLSTM) architecture, combined with a one-dimensional Convolutional Neural Network (CNN) for post-processing with fixed weights initialization. The proposed network is trained with two datasets consisting of simultaneously recorded speech and Electromagnetic Articulography (EMA) datasets, each introducing variations in terms of geographical origin, linguistic characteristics, phonetic diversity, and recording equipment. The performance of the model is assessed in Speaker Dependent (SD), Speaker Independent (SI), corpus dependent (CD) and cross corpus (CC) modes. Experimental results indicate that the proposed model with fixed weights approach outperformed the adaptive weights initialization with in relatively minimal number of training epochs. These findings contribute to the development of robust and efficient models for articulatory feature prediction, paving the way for advancements in speech production research and applications.
Romanized to Native Malayalam Script Transliteration Using an Encoder-Decoder Framework
Dec 13, 2024



In this work, we present the development of a reverse transliteration model to convert romanized Malayalam to native script using an encoder-decoder framework built with attention-based bidirectional Long Short Term Memory (Bi-LSTM) architecture. To train the model, we have used curated and combined collection of 4.3 million transliteration pairs derived from publicly available Indic language translitertion datasets, Dakshina and Aksharantar. We evaluated the model on two different test dataset provided by IndoNLP-2025-Shared-Task that contain, (1) General typing patterns and (2) Adhoc typing patterns, respectively. On the Test Set-1, we obtained a character error rate (CER) of 7.4%. However upon Test Set-2, with adhoc typing patterns, where most vowel indicators are missing, our model gave a CER of 22.7%.
Multistage Fine-tuning Strategies for Automatic Speech Recognition in Low-resource Languages
Nov 07, 2024This paper presents a novel multistage fine-tuning strategy designed to enhance automatic speech recognition (ASR) performance in low-resource languages using OpenAI's Whisper model. In this approach we aim to build ASR model for languages with limited digital resources by sequentially adapting the model across linguistically similar languages. We experimented this on the Malasar language, a Dravidian language spoken by approximately ten thousand people in the Western Ghats of South India. Malasar language faces critical challenges for technological intervention due to its lack of a native script and absence of digital or spoken data resources. Working in collaboration with Wycliffe India and Malasar community members, we created a spoken Malasar corpus paired with transcription in Tamil script, a closely related major language. In our approach to build ASR model for Malasar, we first build an intermediate Tamil ASR, leveraging higher data availability for Tamil annotated speech. This intermediate model is subsequently fine-tuned on Malasar data, allowing for more effective ASR adaptation despite limited resources. The multistage fine-tuning strategy demonstrated significant improvements over direct fine-tuning on Malasar data alone, achieving a word error rate (WER) of 51.9%, which is 4.5% absolute reduction when compared to the direct fine-tuning method. Further a WER reduction to 47.3% was achieved through punctuation removal in post-processing, which addresses formatting inconsistencies that impact evaluation. Our results underscore the effectiveness of sequential multistage fine-tuning combined with targeted post-processing as a scalable strategy for ASR system development in low-resource languages, especially where linguistic similarities can be leveraged to bridge gaps in training data.
Findings of the Sentiment Analysis of Dravidian Languages in Code-Mixed Text
Nov 18, 2021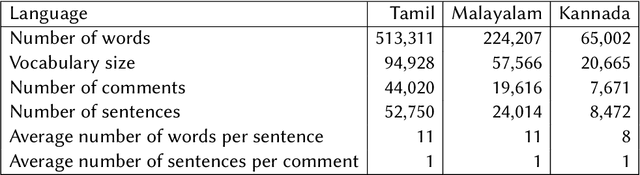
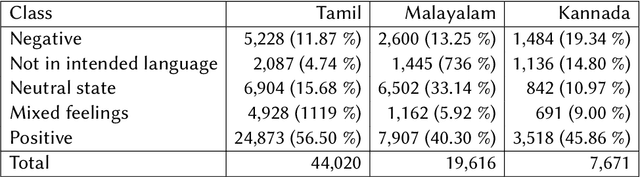
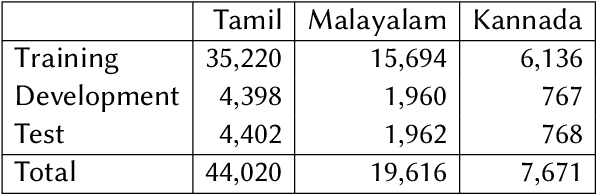
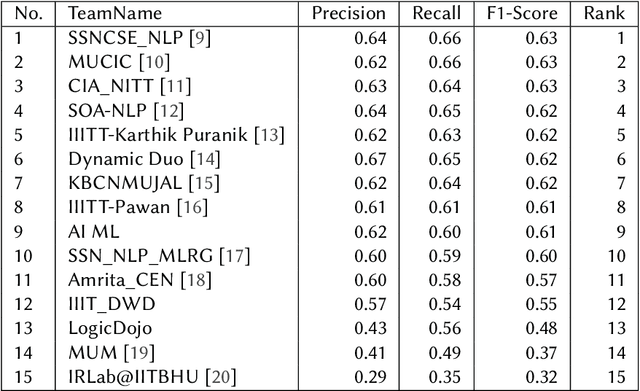
We present the results of the Dravidian-CodeMix shared task held at FIRE 2021, a track on sentiment analysis for Dravidian Languages in Code-Mixed Text. We describe the task, its organization, and the submitted systems. This shared task is the continuation of last year's Dravidian-CodeMix shared task held at FIRE 2020. This year's tasks included code-mixing at the intra-token and inter-token levels. Additionally, apart from Tamil and Malayalam, Kannada was also introduced. We received 22 systems for Tamil-English, 15 systems for Malayalam-English, and 15 for Kannada-English. The top system for Tamil-English, Malayalam-English and Kannada-English scored weighted average F1-score of 0.711, 0.804, and 0.630, respectively. In summary, the quality and quantity of the submission show that there is great interest in Dravidian languages in code-mixed setting and state of the art in this domain still needs more improvement.
DravidianCodeMix: Sentiment Analysis and Offensive Language Identification Dataset for Dravidian Languages in Code-Mixed Text
Jun 17, 2021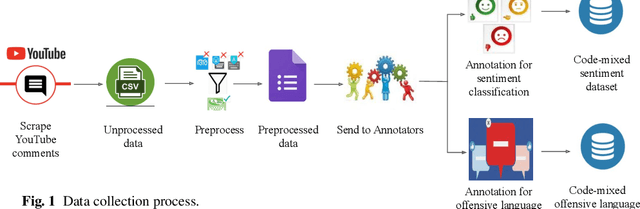
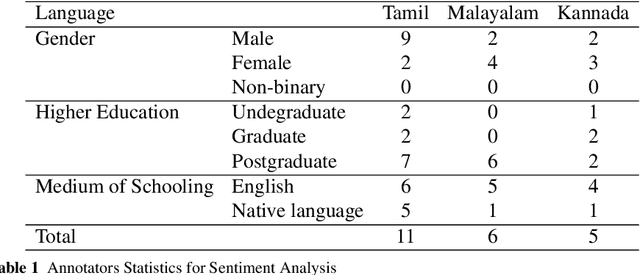
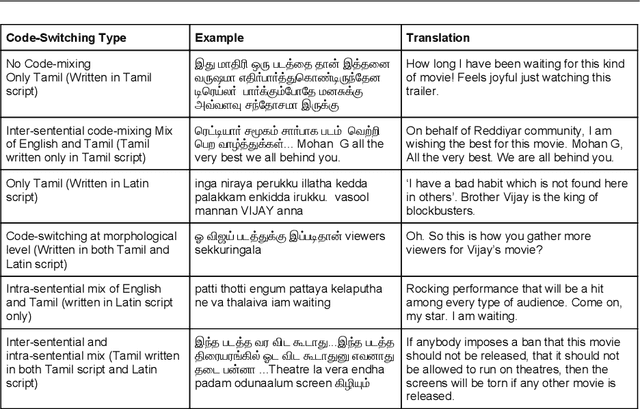
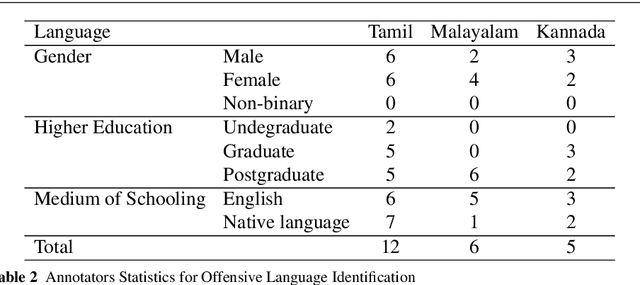
This paper describes the development of a multilingual, manually annotated dataset for three under-resourced Dravidian languages generated from social media comments. The dataset was annotated for sentiment analysis and offensive language identification for a total of more than 60,000 YouTube comments. The dataset consists of around 44,000 comments in Tamil-English, around 7,000 comments in Kannada-English, and around 20,000 comments in Malayalam-English. The data was manually annotated by volunteer annotators and has a high inter-annotator agreement in Krippendorff's alpha. The dataset contains all types of code-mixing phenomena since it comprises user-generated content from a multilingual country. We also present baseline experiments to establish benchmarks on the dataset using machine learning methods. The dataset is available on Github (https://github.com/bharathichezhiyan/DravidianCodeMix-Dataset) and Zenodo (https://zenodo.org/record/4750858\#.YJtw0SYo\_0M).
A Sentiment Analysis Dataset for Code-Mixed Malayalam-English
May 30, 2020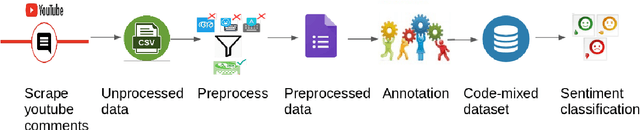
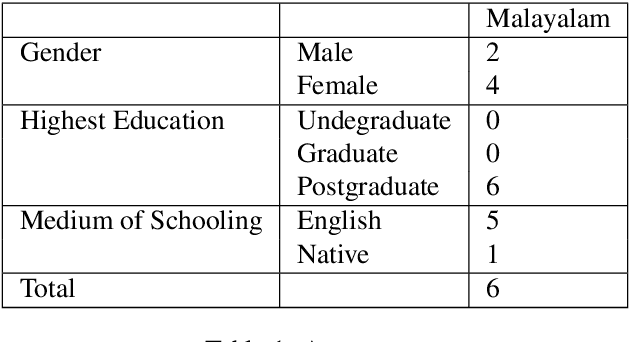
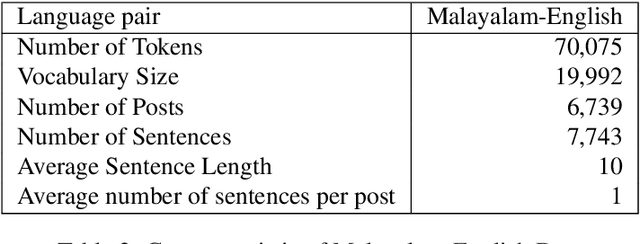

There is an increasing demand for sentiment analysis of text from social media which are mostly code-mixed. Systems trained on monolingual data fail for code-mixed data due to the complexity of mixing at different levels of the text. However, very few resources are available for code-mixed data to create models specific for this data. Although much research in multilingual and cross-lingual sentiment analysis has used semi-supervised or unsupervised methods, supervised methods still performs better. Only a few datasets for popular languages such as English-Spanish, English-Hindi, and English-Chinese are available. There are no resources available for Malayalam-English code-mixed data. This paper presents a new gold standard corpus for sentiment analysis of code-mixed text in Malayalam-English annotated by voluntary annotators. This gold standard corpus obtained a Krippendorff's alpha above 0.8 for the dataset. We use this new corpus to provide the benchmark for sentiment analysis in Malayalam-English code-mixed texts.