 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrollsWithOpinion: A Dataset for Predicting Domain-specific Opinion Manipulation in Troll Memes
Sep 08, 2021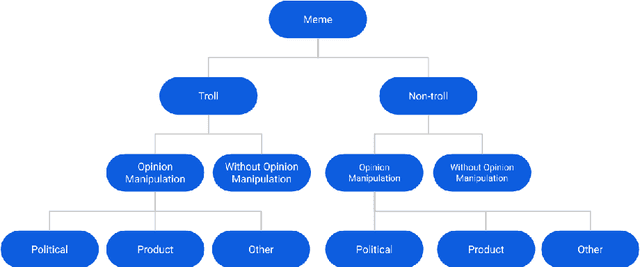

Research into the classification of Image with Text (IWT) troll memes has recently become popular. Since the online community utilizes the refuge of memes to express themselves, there is an abundance of data in the form of memes. These memes have the potential to demean, harras, or bully targeted individuals. Moreover, the targeted individual could fall prey to opinion manipulation. To comprehend the use of memes in opinion manipulation, we define three specific domains (product, political or others) which we classify into troll or not-troll, with or without opinion manipulation. To enable this analysis, we enhanced an existing dataset by annotating the data with our defined classes, resulting in a dataset of 8,881 IWT or multimodal memes in the English language (TrollsWithOpinion dataset). We perform baseline experiments on the annotated dataset, and our result shows that existing state-of-the-art techniques could only reach a weighted-average F1-score of 0.37. This shows the need for a development of a specific technique to deal with multimodal troll memes.
DravidianCodeMix: Sentiment Analysis and Offensive Language Identification Dataset for Dravidian Languages in Code-Mixed Text
Jun 17, 2021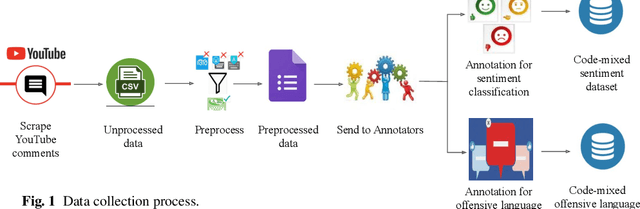
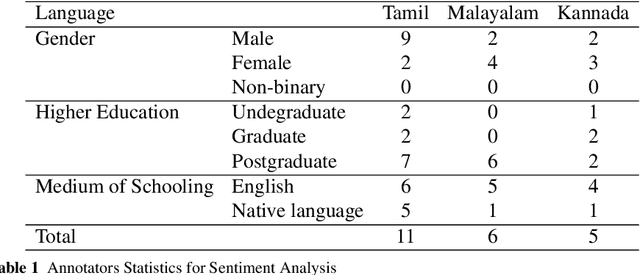
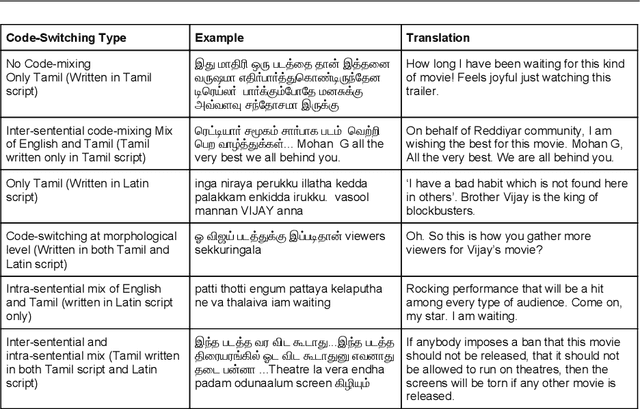
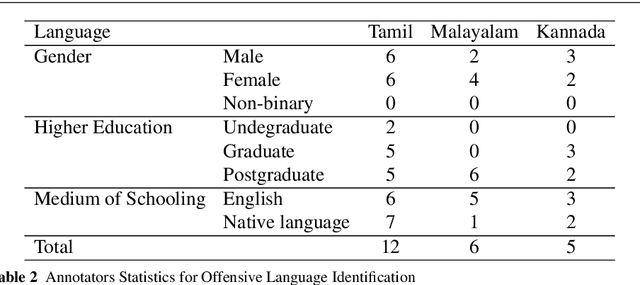
This paper describes the development of a multilingual, manually annotated dataset for three under-resourced Dravidian languages generated from social media comments. The dataset was annotated for sentiment analysis and offensive language identification for a total of more than 60,000 YouTube comments. The dataset consists of around 44,000 comments in Tamil-English, around 7,000 comments in Kannada-English, and around 20,000 comments in Malayalam-English. The data was manually annotated by volunteer annotators and has a high inter-annotator agreement in Krippendorff's alpha. The dataset contains all types of code-mixing phenomena since it comprises user-generated content from a multilingual country. We also present baseline experiments to establish benchmarks on the dataset using machine learning methods. The dataset is available on Github (https://github.com/bharathichezhiyan/DravidianCodeMix-Dataset) and Zenodo (https://zenodo.org/record/4750858\#.YJtw0SYo\_0M).
A Sentiment Analysis Dataset for Code-Mixed Malayalam-English
May 30, 2020
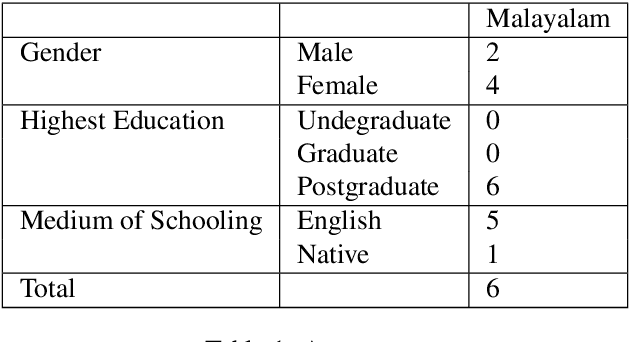
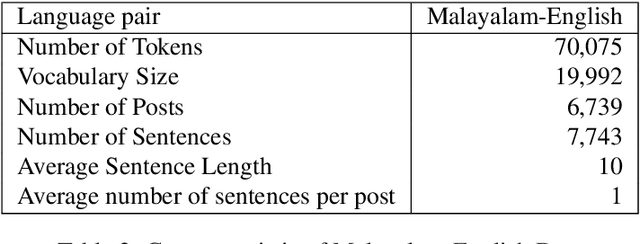

There is an increasing demand for sentiment analysis of text from social media which are mostly code-mixed. Systems trained on monolingual data fail for code-mixed data due to the complexity of mixing at different levels of the text. However, very few resources are available for code-mixed data to create models specific for this data. Although much research in multilingual and cross-lingual sentiment analysis has used semi-supervised or unsupervised methods, supervised methods still performs better. Only a few datasets for popular languages such as English-Spanish, English-Hindi, and English-Chinese are available. There are no resources available for Malayalam-English code-mixed data. This paper presents a new gold standard corpus for sentiment analysis of code-mixed text in Malayalam-English annotated by voluntary annotators. This gold standard corpus obtained a Krippendorff's alpha above 0.8 for the dataset. We use this new corpus to provide the benchmark for sentiment analysis in Malayalam-English code-mixed texts.