 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Enriching Investor Micro-blogs for Opinion-Aware Emotion Analysis: A Practical Approach
May 04, 2026While sentiment analysis is the staple of financial NLP, capturing the nuances of 'why' behind that sentiment remains a challenge. There have been attempts to address this by analysing investor emotions alongside sentiment; however, this does not provide the additional granularity required to understand the target of the emotion/sentiment. We address this by augmenting the StockEmotions dataset with semantically structured opinion graphs, which provide granular semantic depth to the existing sentiment and emotion labels. Using a declarative LLM pipeline, we augment the StockEmotions dataset with opinion graphs for each sentence, derived from 10,000 comments collected from StockTwits. In addition, we study the effect of introducing opinion semantics on baseline classifiers using Graph Neural Networks (GNNs). Our analysis demonstrates that incorporating opinion semantics improves classification performance across different emotional spectrums
Large Language Models as Automatic Annotators and Annotation Adjudicators for Fine-Grained Opinion Analysis
Jan 23, 2026Fine-grained opinion analysis of text provides a detailed understanding of expressed sentiments, including the addressed entity. Although this level of detail is sound, it requires considerable human effort and substantial cost to annotate opinions in datasets for training models, especially across diverse domains and real-world applications. We explore the feasibility of LLMs as automatic annotators for fine-grained opinion analysis, addressing the shortage of domain-specific labelled datasets. In this work, we use a declarative annotation pipeline. This approach reduces the variability of manual prompt engineering when using LLMs to identify fine-grained opinion spans in text. We also present a novel methodology for an LLM to adjudicate multiple labels and produce final annotations. After trialling the pipeline with models of different sizes for the Aspect Sentiment Triplet Extraction (ASTE) and Aspect-Category-Opinion-Sentiment (ACOS) analysis tasks, we show that LLMs can serve as automatic annotators and adjudicators, achieving high Inter-Annotator Agreement across individual LLM-based annotators. This reduces the cost and human effort needed to create these fine-grained opinion-annotated datasets.
Towards Semantic Integration of Opinions: Unified Opinion Concepts Ontology and Extraction Task
May 24, 2025This paper introduces the Unified Opinion Concepts (UOC) ontology to integrate opinions within their semantic context. The UOC ontology bridges the gap between the semantic representation of opinion across different formulations. It is a unified conceptualisation based on the facets of opinions studied extensively in NLP and semantic structures described through symbolic descriptions. We further propose the Unified Opinion Concept Extraction (UOCE) task of extracting opinions from the text with enhanced expressivity. Additionally, we provide a manually extended and re-annotated evaluation dataset for this task and tailored evaluation metrics to assess the adherence of extracted opinions to UOC semantics. Finally, we establish baseline performance for the UOCE task using state-of-the-art generative models.
A Hybrid Approach To Aspect Based Sentiment Analysis Using Transfer Learning
Mar 25, 2024



Aspect-Based Sentiment Analysis (ABSA) aims to identify terms or multiword expressions (MWEs) on which sentiments are expressed and the sentiment polarities associated with them. The development of supervised models has been at the forefront of research in this area. However, training these models requires the availability of manually annotated datasets which is both expensive and time-consuming. Furthermore, the available annotated datasets are tailored to a specific domain, language, and text type. In this work, we address this notable challenge in current state-of-the-art ABSA research. We propose a hybrid approach for Aspect Based Sentiment Analysis using transfer learning. The approach focuses on generating weakly-supervised annotations by exploiting the strengths of both large language models (LLM) and traditional syntactic dependencies. We utilise syntactic dependency structures of sentences to complement the annotations generated by LLMs, as they may overlook domain-specific aspect terms. Extensive experimentation on multiple datasets is performed to demonstrate the efficacy of our hybrid method for the tasks of aspect term extraction and aspect sentiment classification. Keywords: Aspect Based Sentiment Analysis, Syntactic Parsing, large language model (LLM)
Inference to the Best Explanation in Large Language Models
Feb 16, 2024



While Large Language Models (LLMs) have found success in real-world applications, their underlying explanatory process is still poorly understood. This paper proposes IBE-Eval, a framework inspired by philosophical accounts on Inference to the Best Explanation (IBE) to advance the interpretation and evaluation of LLMs' explanations. IBE-Eval estimates the plausibility of natural language explanations through a combination of explicit logical and linguistic features including: consistency, parsimony, coherence, and uncertainty. Extensive experiments are conducted on Causal Question Answering (CQA), where \textit{IBE-Eval} is tasked to select the most plausible causal explanation amongst competing ones generated by LLMs (i.e., GPT 3.5 and Llama 2). The experiments reveal that IBE-Eval can successfully identify the best explanation with up to 77\% accuracy ($\approx 27\%$ above random), improving upon a GPT 3.5-as-a-Judge baseline ($\approx+17\%$) while being intrinsically more efficient and interpretable. Additional analyses suggest that, despite model-specific variances, LLM-generated explanations tend to conform to IBE criteria and that IBE-Eval is significantly correlated with human judgment, opening up opportunities for future development of automated explanation verification tools.
Empowering recommender systems using automatically generated Knowledge Graphs and Reinforcement Learning
Jul 11, 2023Personalized recommendations have a growing importance in direct marketing, which motivates research to enhance customer experiences by knowledge graph (KG) applications. For example, in financial services, companies may benefit from providing relevant financial articles to their customers to cultivate relationships, foster client engagement and promote informed financial decisions. While several approaches center on KG-based recommender systems for improved content, in this study we focus on interpretable KG-based recommender systems for decision making.To this end, we present two knowledge graph-based approaches for personalized article recommendations for a set of customers of a large multinational financial services company. The first approach employs Reinforcement Learning and the second approach uses the XGBoost algorithm for recommending articles to the customers. Both approaches make use of a KG generated from both structured (tabular data) and unstructured data (a large body of text data).Using the Reinforcement Learning-based recommender system we could leverage the graph traversal path leading to the recommendation as a way to generate interpretations (Path Directed Reasoning (PDR)). In the XGBoost-based approach, one can also provide explainable results using post-hoc methods such as SHAP (SHapley Additive exPlanations) and ELI5 (Explain Like I am Five).Importantly, our approach offers explainable results, promoting better decision-making. This study underscores the potential of combining advanced machine learning techniques with KG-driven insights to bolster experience in customer relationship management.
TrollsWithOpinion: A Dataset for Predicting Domain-specific Opinion Manipulation in Troll Memes
Sep 08, 2021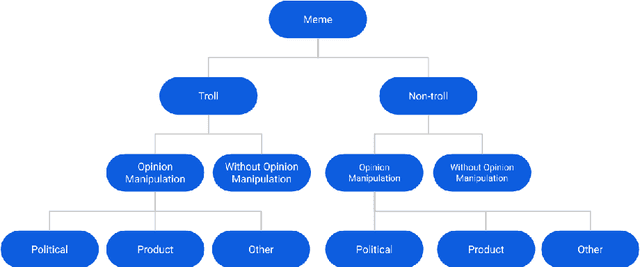

Research into the classification of Image with Text (IWT) troll memes has recently become popular. Since the online community utilizes the refuge of memes to express themselves, there is an abundance of data in the form of memes. These memes have the potential to demean, harras, or bully targeted individuals. Moreover, the targeted individual could fall prey to opinion manipulation. To comprehend the use of memes in opinion manipulation, we define three specific domains (product, political or others) which we classify into troll or not-troll, with or without opinion manipulation. To enable this analysis, we enhanced an existing dataset by annotating the data with our defined classes, resulting in a dataset of 8,881 IWT or multimodal memes in the English language (TrollsWithOpinion dataset). We perform baseline experiments on the annotated dataset, and our result shows that existing state-of-the-art techniques could only reach a weighted-average F1-score of 0.37. This shows the need for a development of a specific technique to deal with multimodal troll memes.
Contextual Modulation for Relation-Level Metaphor Identification
Oct 12, 2020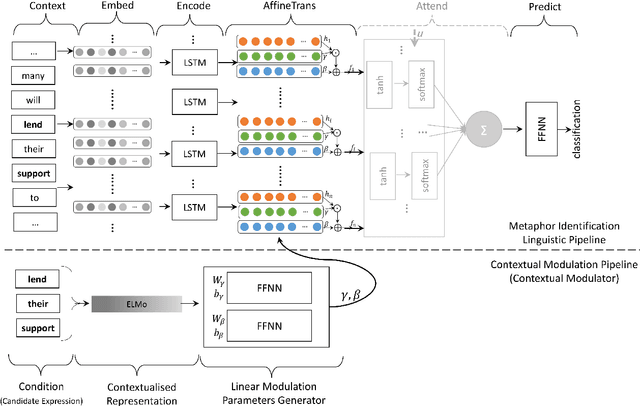
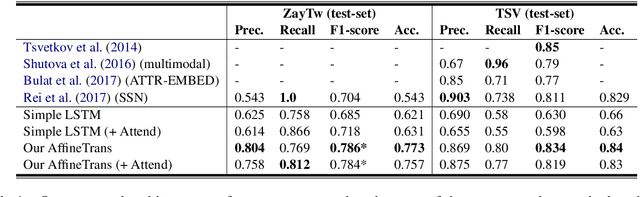


Identifying metaphors in text is very challenging and requires comprehending the underlying comparison. The automation of this cognitive process has gained wide attention lately. However, the majority of existing approaches concentrate on word-level identification by treating the task as either single-word classification or sequential labelling without explicitly modelling the interaction between the metaphor components. On the other hand, while existing relation-level approaches implicitly model this interaction, they ignore the context where the metaphor occurs. In this work, we address these limitations by introducing a novel architecture for identifying relation-level metaphoric expressions of certain grammatical relations based on contextual modulation. In a methodology inspired by works in visual reasoning, our approach is based on conditioning the neural network computation on the deep contextualised features of the candidate expressions using feature-wise linear modulation. We demonstrate that the proposed architecture achieves state-of-the-art results on benchmark datasets. The proposed methodology is generic and could be applied to other textual classification problems that benefit from contextual interaction.
Polylingual Wordnet
Mar 04, 2019
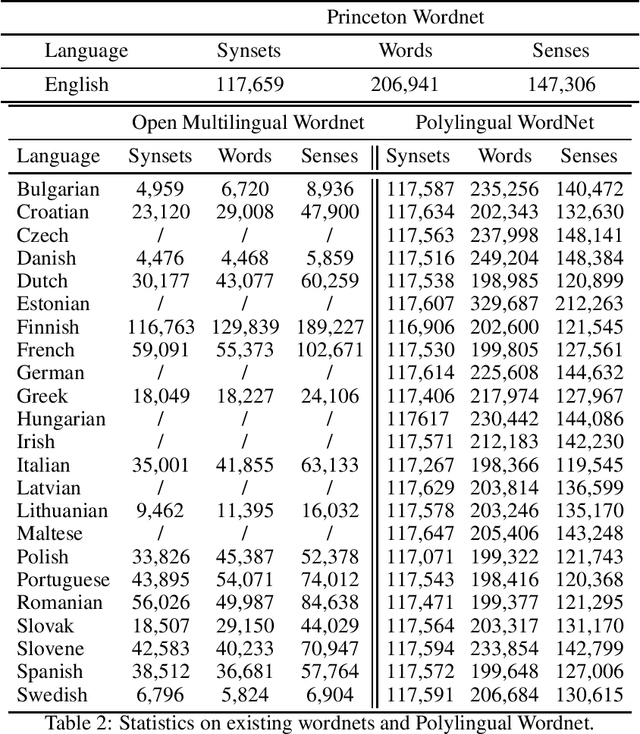
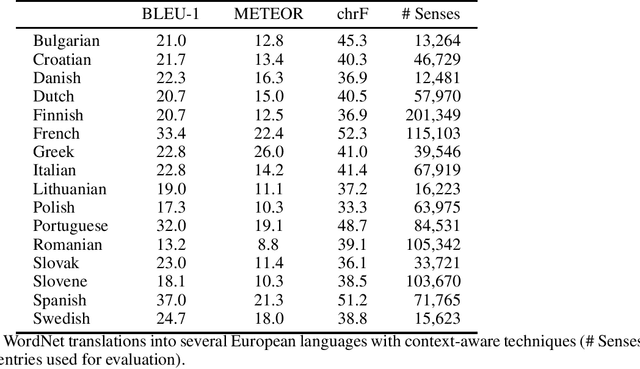
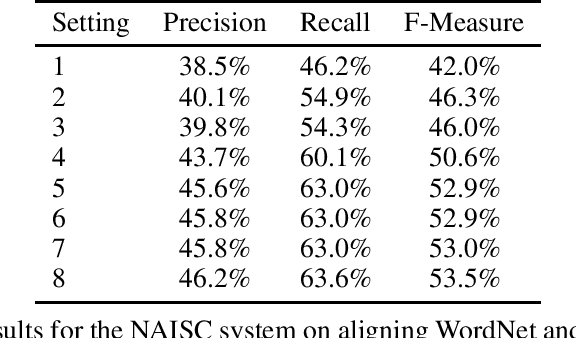
Princeton WordNet is one of the most important resources for natural language processing, but is only available for English. While it has been translated using the expand approach to many other languages, this is an expensive manual process. Therefore it would be beneficial to have a high-quality automatic translation approach that would support NLP techniques, which rely on WordNet in new languages. The translation of wordnets is fundamentally complex because of the need to translate all senses of a word including low frequency senses, which is very challenging for current machine translation approaches. For this reason we leverage existing translations of WordNet in other languages to identify contextual information for wordnet senses from a large set of generic parallel corpora. We evaluate our approach using 10 translated wordnets for European languages. Our experiment shows a significant improvement over translation without any contextual information. Furthermore, we evaluate how the choice of pivot languages affects performance of multilingual word sense disambiguation.
Augmenting Neural Machine Translation with Knowledge Graphs
Feb 23, 2019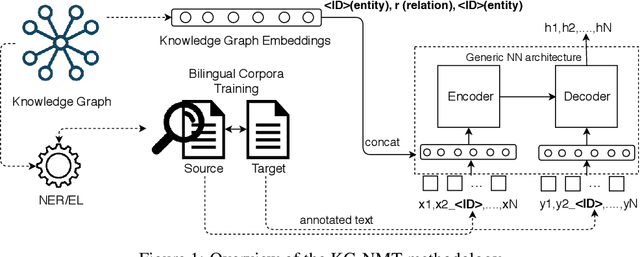
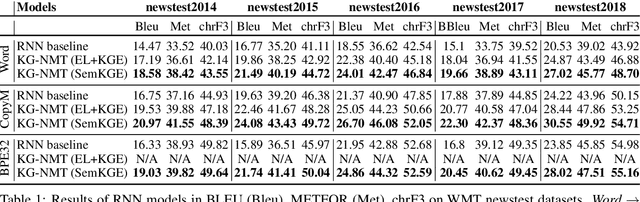
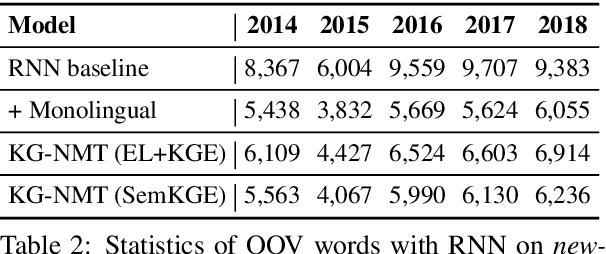
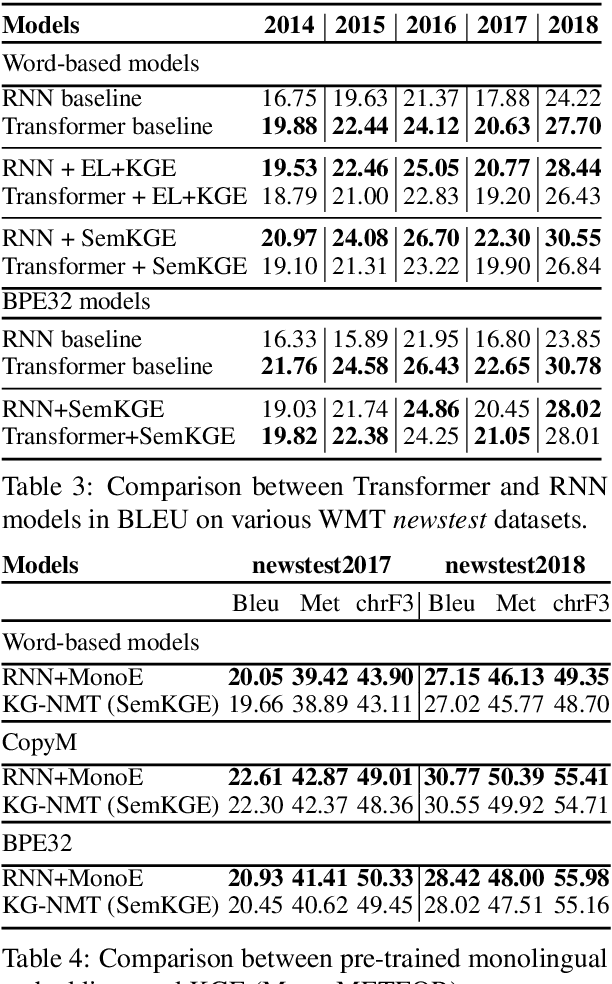
While neural networks have been used extensively to make substantial progress in the machine translation task, they are known for being heavily dependent on the availability of large amounts of training data. Recent efforts have tried to alleviate the data sparsity problem by augmenting the training data using different strategies, such as back-translation. Along with the data scarcity, the out-of-vocabulary words, mostly entities and terminological expressions, pose a difficult challenge to Neural Machine Translation systems. In this paper, we hypothesize that knowledge graphs enhance the semantic feature extraction of neural models, thus optimizing the translation of entities and terminological expressions in texts and consequently leading to a better translation quality. We hence investigate two different strategies for incorporating knowledge graphs into neural models without modifying the neural network architectures. We also examine the effectiveness of our augmentation method to recurrent and non-recurrent (self-attentional) neural architectures. Our knowledge graph augmented neural translation model, dubbed KG-NMT, achieves significant and consistent improvements of +3 BLEU, METEOR and chrF3 on average on the newstest datasets between 2014 and 2018 for WMT English-German translation task.