 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Distant Supervision in Suggestion Mining through Part-of-Speech Embeddings
Paper and Code
Dec 05, 2017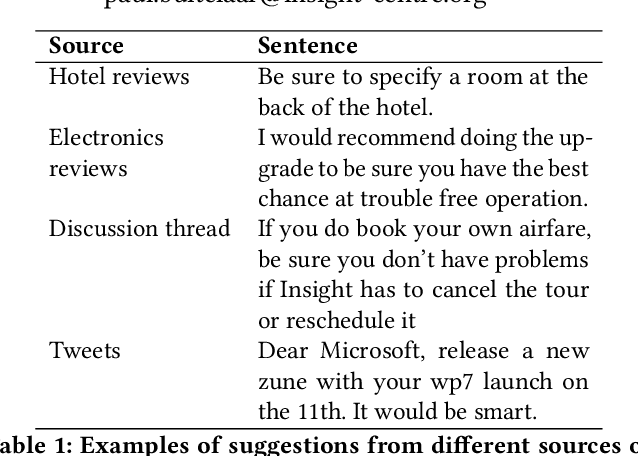


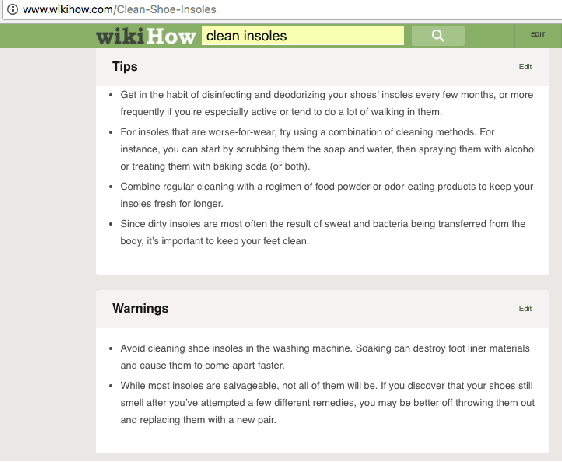
Mining suggestion expressing sentences from a given text is a less investigated sentence classification task, and therefore lacks hand labeled benchmark datasets. In this work, we propose and evaluate two approaches for distant supervision in suggestion mining. The distant supervision is obtained through a large silver standard dataset, constructed using the text from wikiHow and Wikipedia. Both the approaches use a LSTM based neural network architecture to learn a classification model for suggestion mining, but vary in their method to use the silver standard dataset. The first approach directly trains the classifier using this dataset, while the second approach only learns word embeddings from this dataset. In the second approach, we also learn POS embeddings, which interestingly gives the best classification accuracy.