 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Enriching Investor Micro-blogs for Opinion-Aware Emotion Analysis: A Practical Approach
May 04, 2026While sentiment analysis is the staple of financial NLP, capturing the nuances of 'why' behind that sentiment remains a challenge. There have been attempts to address this by analysing investor emotions alongside sentiment; however, this does not provide the additional granularity required to understand the target of the emotion/sentiment. We address this by augmenting the StockEmotions dataset with semantically structured opinion graphs, which provide granular semantic depth to the existing sentiment and emotion labels. Using a declarative LLM pipeline, we augment the StockEmotions dataset with opinion graphs for each sentence, derived from 10,000 comments collected from StockTwits. In addition, we study the effect of introducing opinion semantics on baseline classifiers using Graph Neural Networks (GNNs). Our analysis demonstrates that incorporating opinion semantics improves classification performance across different emotional spectrums
Large Language Models as Automatic Annotators and Annotation Adjudicators for Fine-Grained Opinion Analysis
Jan 23, 2026Fine-grained opinion analysis of text provides a detailed understanding of expressed sentiments, including the addressed entity. Although this level of detail is sound, it requires considerable human effort and substantial cost to annotate opinions in datasets for training models, especially across diverse domains and real-world applications. We explore the feasibility of LLMs as automatic annotators for fine-grained opinion analysis, addressing the shortage of domain-specific labelled datasets. In this work, we use a declarative annotation pipeline. This approach reduces the variability of manual prompt engineering when using LLMs to identify fine-grained opinion spans in text. We also present a novel methodology for an LLM to adjudicate multiple labels and produce final annotations. After trialling the pipeline with models of different sizes for the Aspect Sentiment Triplet Extraction (ASTE) and Aspect-Category-Opinion-Sentiment (ACOS) analysis tasks, we show that LLMs can serve as automatic annotators and adjudicators, achieving high Inter-Annotator Agreement across individual LLM-based annotators. This reduces the cost and human effort needed to create these fine-grained opinion-annotated datasets.
LTG at SemEval-2025 Task 10: Optimizing Context for Classification of Narrative Roles
Jun 06, 2025Our contribution to the SemEval 2025 shared task 10, subtask 1 on entity framing, tackles the challenge of providing the necessary segments from longer documents as context for classification with a masked language model. We show that a simple entity-oriented heuristics for context selection can enable text classification using models with limited context window. Our context selection approach and the XLM-RoBERTa language model is on par with, or outperforms, Supervised Fine-Tuning with larger generative language models.
Towards Semantic Integration of Opinions: Unified Opinion Concepts Ontology and Extraction Task
May 24, 2025This paper introduces the Unified Opinion Concepts (UOC) ontology to integrate opinions within their semantic context. The UOC ontology bridges the gap between the semantic representation of opinion across different formulations. It is a unified conceptualisation based on the facets of opinions studied extensively in NLP and semantic structures described through symbolic descriptions. We further propose the Unified Opinion Concept Extraction (UOCE) task of extracting opinions from the text with enhanced expressivity. Additionally, we provide a manually extended and re-annotated evaluation dataset for this task and tailored evaluation metrics to assess the adherence of extracted opinions to UOC semantics. Finally, we establish baseline performance for the UOCE task using state-of-the-art generative models.
A Hybrid Approach To Aspect Based Sentiment Analysis Using Transfer Learning
Mar 25, 2024



Aspect-Based Sentiment Analysis (ABSA) aims to identify terms or multiword expressions (MWEs) on which sentiments are expressed and the sentiment polarities associated with them. The development of supervised models has been at the forefront of research in this area. However, training these models requires the availability of manually annotated datasets which is both expensive and time-consuming. Furthermore, the available annotated datasets are tailored to a specific domain, language, and text type. In this work, we address this notable challenge in current state-of-the-art ABSA research. We propose a hybrid approach for Aspect Based Sentiment Analysis using transfer learning. The approach focuses on generating weakly-supervised annotations by exploiting the strengths of both large language models (LLM) and traditional syntactic dependencies. We utilise syntactic dependency structures of sentences to complement the annotations generated by LLMs, as they may overlook domain-specific aspect terms. Extensive experimentation on multiple datasets is performed to demonstrate the efficacy of our hybrid method for the tasks of aspect term extraction and aspect sentiment classification. Keywords: Aspect Based Sentiment Analysis, Syntactic Parsing, large language model (LLM)
MaCmS: Magahi Code-mixed Dataset for Sentiment Analysis
Mar 07, 2024The present paper introduces new sentiment data, MaCMS, for Magahi-Hindi-English (MHE) code-mixed language, where Magahi is a less-resourced minority language. This dataset is the first Magahi-Hindi-English code-mixed dataset for sentiment analysis tasks. Further, we also provide a linguistics analysis of the dataset to understand the structure of code-mixing and a statistical study to understand the language preferences of speakers with different polarities. With these analyses, we also train baseline models to evaluate the dataset's quality.
Detecting Deepfake Videos Using Euler Video Magnification
Jan 27, 2021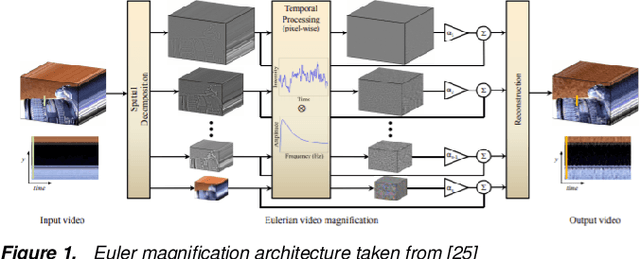
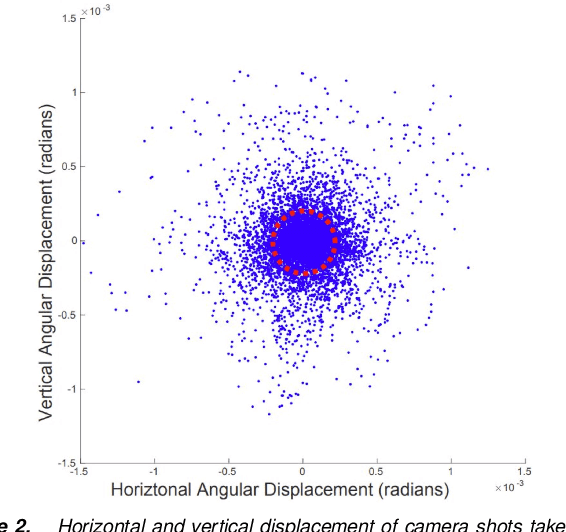
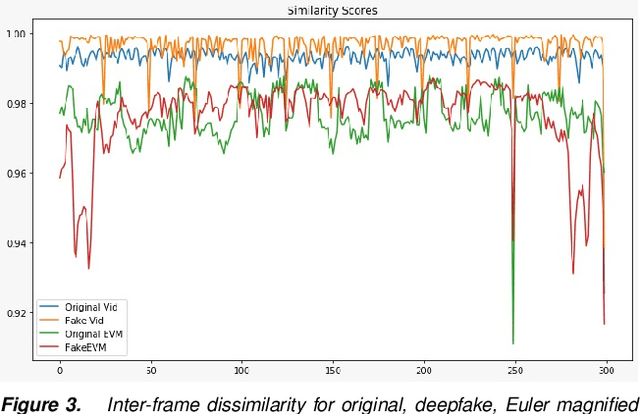

Recent advances in artificial intelligence make it progressively hard to distinguish between genuine and counterfeit media, especially images and videos. One recent development is the rise of deepfake videos, based on manipulating videos using advanced machine learning techniques. This involves replacing the face of an individual from a source video with the face of a second person, in the destination video. This idea is becoming progressively refined as deepfakes are getting progressively seamless and simpler to compute. Combined with the outreach and speed of social media, deepfakes could easily fool individuals when depicting someone saying things that never happened and thus could persuade people in believing fictional scenarios, creating distress, and spreading fake news. In this paper, we examine a technique for possible identification of deepfake videos. We use Euler video magnification which applies spatial decomposition and temporal filtering on video data to highlight and magnify hidden features like skin pulsation and subtle motions. Our approach uses features extracted from the Euler technique to train three models to classify counterfeit and unaltered videos and compare the results with existing techniques.