 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenLID-v3: Improving the Precision of Closely Related Language Identification -- An Experience Report
Feb 13, 2026Language identification (LID) is an essential step in building high-quality multilingual datasets from web data. Existing LID tools (such as OpenLID or GlotLID) often struggle to identify closely related languages and to distinguish valid natural language from noise, which contaminates language-specific subsets, especially for low-resource languages. In this work we extend the OpenLID classifier by adding more training data, merging problematic language variant clusters, and introducing a special label for marking noise. We call this extended system OpenLID-v3 and evaluate it against GlotLID on multiple benchmarks. During development, we focus on three groups of closely related languages (Bosnian, Croatian, and Serbian; Romance varieties of Northern Italy and Southern France; and Scandinavian languages) and contribute new evaluation datasets where existing ones are inadequate. We find that ensemble approaches improve precision but also substantially reduce coverage for low-resource languages. OpenLID-v3 is available on https://huggingface.co/HPLT/OpenLID-v3.
LTG at SemEval-2025 Task 10: Optimizing Context for Classification of Narrative Roles
Jun 06, 2025Our contribution to the SemEval 2025 shared task 10, subtask 1 on entity framing, tackles the challenge of providing the necessary segments from longer documents as context for classification with a masked language model. We show that a simple entity-oriented heuristics for context selection can enable text classification using models with limited context window. Our context selection approach and the XLM-RoBERTa language model is on par with, or outperforms, Supervised Fine-Tuning with larger generative language models.
Mixed Feelings: Cross-Domain Sentiment Classification of Patient Feedback
Jan 31, 2025Sentiment analysis of patient feedback from the public health domain can aid decision makers in evaluating the provided services. The current paper focuses on free-text comments in patient surveys about general practitioners and psychiatric healthcare, annotated with four sentence-level polarity classes -- positive, negative, mixed and neutral -- while also attempting to alleviate data scarcity by leveraging general-domain sources in the form of reviews. For several different architectures, we compare in-domain and out-of-domain effects, as well as the effects of training joint multi-domain models.
Entity-Level Sentiment: More than the Sum of Its Parts
Jul 04, 2024



In sentiment analysis of longer texts, there may be a variety of topics discussed, of entities mentioned, and of sentiments expressed regarding each entity. We find a lack of studies exploring how such texts express their sentiment towards each entity of interest, and how these sentiments can be modelled. In order to better understand how sentiment regarding persons and organizations (each entity in our scope) is expressed in longer texts, we have collected a dataset of expert annotations where the overall sentiment regarding each entity is identified, together with the sentence-level sentiment for these entities separately. We show that the reader's perceived sentiment regarding an entity often differs from an arithmetic aggregation of sentiments at the sentence level. Only 70\% of the positive and 55\% of the negative entities receive a correct overall sentiment label when we aggregate the (human-annotated) sentiment labels for the sentences where the entity is mentioned. Our dataset reveals the complexity of entity-specific sentiment in longer texts, and allows for more precise modelling and evaluation of such sentiment expressions.
NorBench -- A Benchmark for Norwegian Language Models
May 06, 2023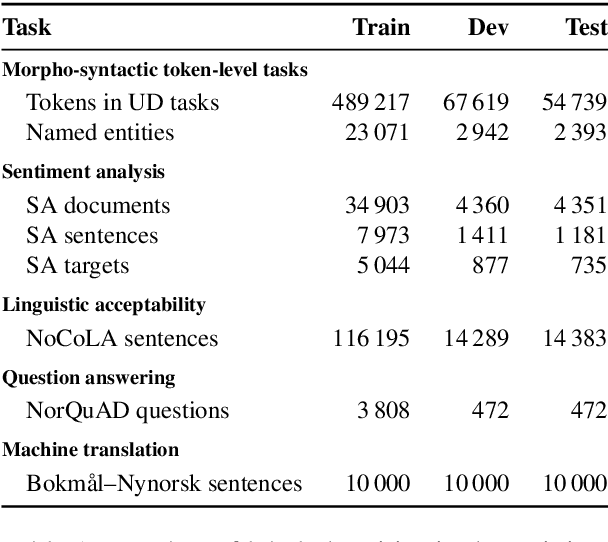


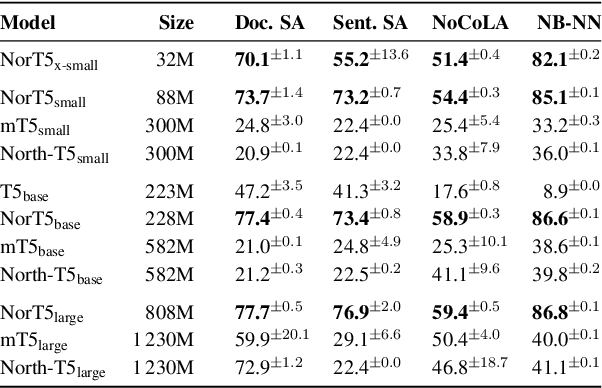
We present NorBench: a streamlined suite of NLP tasks and probes for evaluating Norwegian language models (LMs) on standardized data splits and evaluation metrics. We also introduce a range of new Norwegian language models (both encoder and encoder-decoder based). Finally, we compare and analyze their performance, along with other existing LMs, across the different benchmark tests of NorBench.
Entity-Level Sentiment Analysis (ELSA): An exploratory task survey
Apr 27, 2023



This paper explores the task of identifying the overall sentiment expressed towards volitional entities (persons and organizations) in a document -- what we refer to as Entity-Level Sentiment Analysis (ELSA). While identifying sentiment conveyed towards an entity is well researched for shorter texts like tweets, we find little to no research on this specific task for longer texts with multiple mentions and opinions towards the same entity. This lack of research would be understandable if ELSA can be derived from existing tasks and models. To assess this, we annotate a set of professional reviews for their overall sentiment towards each volitional entity in the text. We sample from data already annotated for document-level, sentence-level, and target-level sentiment in a multi-domain review corpus, and our results indicate that there is no single proxy task that provides this overall sentiment we seek for the entities at a satisfactory level of performance. We present a suite of experiments aiming to assess the contribution towards ELSA provided by document-, sentence-, and target-level sentiment analysis, and provide a discussion of their shortcomings. We show that sentiment in our dataset is expressed not only with an entity mention as target, but also towards targets with a sentiment-relevant relation to a volitional entity. In our data, these relations extend beyond anaphoric coreference resolution, and our findings call for further research of the topic. Finally, we also present a survey of previous relevant work.
UIO at SemEval-2023 Task 12: Multilingual fine-tuning for sentiment classification in low-resource languages
Apr 27, 2023Our contribution to the 2023 AfriSenti-SemEval shared task 12: Sentiment Analysis for African Languages, provides insight into how a multilingual large language model can be a resource for sentiment analysis in languages not seen during pretraining. The shared task provides datasets of a variety of African languages from different language families. The languages are to various degrees related to languages used during pretraining, and the language data contain various degrees of code-switching. We experiment with both monolingual and multilingual datasets for the final fine-tuning, and find that with the provided datasets that contain samples in the thousands, monolingual fine-tuning yields the best results.
BRENT: Bidirectional Retrieval Enhanced Norwegian Transformer
Apr 19, 2023Retrieval-based language models are increasingly employed in question-answering tasks. These models search in a corpus of documents for relevant information instead of having all factual knowledge stored in its parameters, thereby enhancing efficiency, transparency, and adaptability. We develop the first Norwegian retrieval-based model by adapting the REALM framework and evaluating it on various tasks. After training, we also separate the language model, which we call the reader, from the retriever components, and show that this can be fine-tuned on a range of downstream tasks. Results show that retrieval augmented language modeling improves the reader's performance on extractive question-answering, suggesting that this type of training improves language models' general ability to use context and that this does not happen at the expense of other abilities such as part-of-speech tagging, dependency parsing, named entity recognition, and lemmatization. Code, trained models, and data are made publicly available.