 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoWit-24: A Richly Annotated Dataset of Wordplay in News Headlines
Mar 03, 2025



We present KoWit-24, a dataset with fine-grained annotation of wordplay in 2,700 Russian news headlines. KoWit-24 annotations include the presence of wordplay, its type, wordplay anchors, and words/phrases the wordplay refers to. Unlike the majority of existing humor collections of canned jokes, KoWit-24 provides wordplay contexts -- each headline is accompanied by the news lead and summary. The most common type of wordplay in the dataset is the transformation of collocations, idioms, and named entities -- the mechanism that has been underrepresented in previous humor datasets. Our experiments with five LLMs show that there is ample room for improvement in wordplay detection and interpretation tasks. The dataset and evaluation scripts are available at https://github.com/Humor-Research/KoWit-24
NorBench -- A Benchmark for Norwegian Language Models
May 06, 2023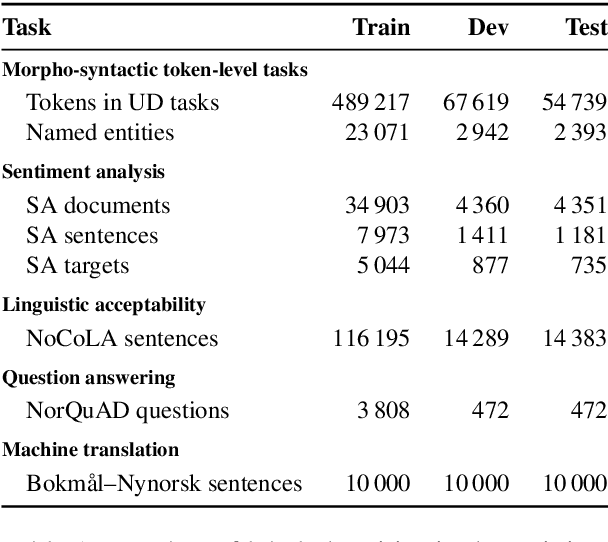


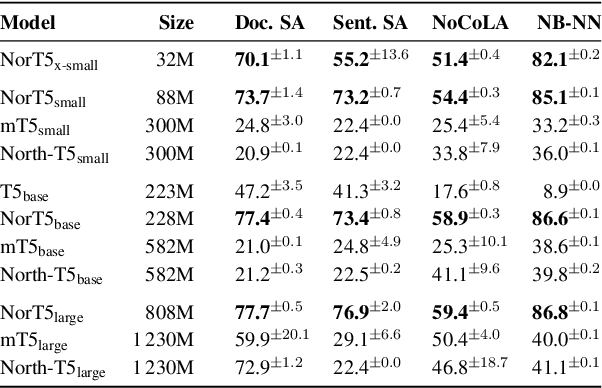
We present NorBench: a streamlined suite of NLP tasks and probes for evaluating Norwegian language models (LMs) on standardized data splits and evaluation metrics. We also introduce a range of new Norwegian language models (both encoder and encoder-decoder based). Finally, we compare and analyze their performance, along with other existing LMs, across the different benchmark tests of NorBench.