 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Cross-Lingual Benchmark for Multimodal Idiomaticity Understanding
Jan 13, 2026Potentially idiomatic expressions (PIEs) construe meanings inherently tied to the everyday experience of a given language community. As such, they constitute an interesting challenge for assessing the linguistic (and to some extent cultural) capabilities of NLP systems. In this paper, we present XMPIE, a parallel multilingual and multimodal dataset of potentially idiomatic expressions. The dataset, containing 34 languages and over ten thousand items, allows comparative analyses of idiomatic patterns among language-specific realisations and preferences in order to gather insights about shared cultural aspects. This parallel dataset allows to evaluate model performance for a given PIE in different languages and whether idiomatic understanding in one language can be transferred to another. Moreover, the dataset supports the study of PIEs across textual and visual modalities, to measure to what extent PIE understanding in one modality transfers or implies in understanding in another modality (text vs. image). The data was created by language experts, with both textual and visual components crafted under multilingual guidelines, and each PIE is accompanied by five images representing a spectrum from idiomatic to literal meanings, including semantically related and random distractors. The result is a high-quality benchmark for evaluating multilingual and multimodal idiomatic language understanding.
Fluent Alignment with Disfluent Judges: Post-training for Lower-resource Languages
Dec 09, 2025



We propose a post-training method for lower-resource languages that preserves fluency of language models even when aligned by disfluent reward models. Preference-optimization is now a well-researched topic, but previous work has mostly addressed models for English and Chinese. Lower-resource languages lack both datasets written by native speakers and language models capable of generating fluent synthetic data. Thus, in this work, we focus on developing a fluent preference-aligned language model without any instruction-tuning data in the target language. Our approach uses an on-policy training method, which we compare with two common approaches: supervised finetuning on machine-translated data and multilingual finetuning. We conduct a case study on Norwegian Bokmål and evaluate fluency through native-speaker assessments. The results show that the on-policy aspect is crucial and outperforms the alternatives without relying on any hard-to-obtain data.
Event-based evaluation of abstractive news summarization
Jul 01, 2025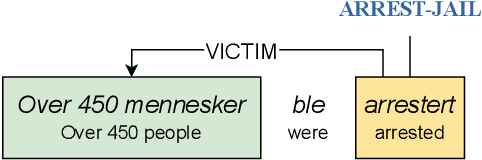
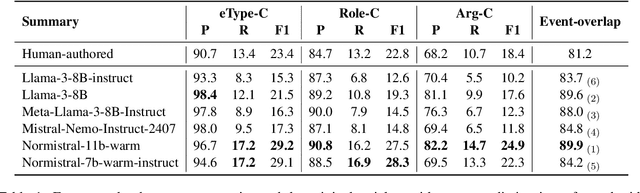
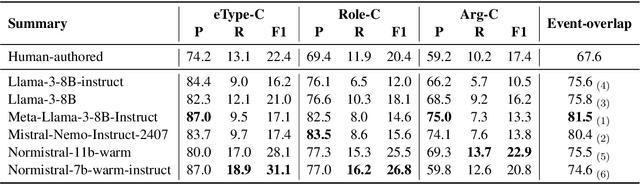
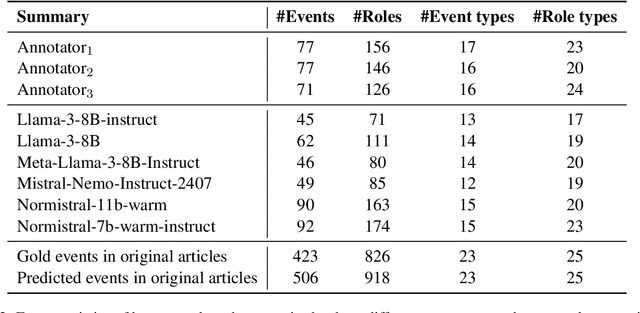
An abstractive summary of a news article contains its most important information in a condensed version. The evaluation of automatically generated summaries by generative language models relies heavily on human-authored summaries as gold references, by calculating overlapping units or similarity scores. News articles report events, and ideally so should the summaries. In this work, we propose to evaluate the quality of abstractive summaries by calculating overlapping events between generated summaries, reference summaries, and the original news articles. We experiment on a richly annotated Norwegian dataset comprising both events annotations and summaries authored by expert human annotators. Our approach provides more insight into the event information contained in the summaries.
NorEval: A Norwegian Language Understanding and Generation Evaluation Benchmark
Apr 10, 2025This paper introduces NorEval, a new and comprehensive evaluation suite for large-scale standardized benchmarking of Norwegian generative language models (LMs). NorEval consists of 24 high-quality human-created datasets -- of which five are created from scratch. In contrast to existing benchmarks for Norwegian, NorEval covers a broad spectrum of task categories targeting Norwegian language understanding and generation, establishes human baselines, and focuses on both of the official written standards of the Norwegian language: Bokm{\aa}l and Nynorsk. All our datasets and a collection of over 100 human-written prompts are integrated into LM Evaluation Harness, ensuring flexible and reproducible evaluation. We describe the NorEval design and present the results of benchmarking 19 open-source pre-trained and instruction-tuned LMs for Norwegian in various scenarios. Our benchmark, evaluation framework, and annotation materials are publicly available.
Semantic Role Labeling: A Systematical Survey
Feb 09, 2025



Semantic role labeling (SRL) is a central natural language processing (NLP) task aiming to understand the semantic roles within texts, facilitating a wide range of downstream applications. While SRL has garnered extensive and enduring research, there is currently a lack of a comprehensive survey that thoroughly organizes and synthesizes the field. This paper aims to review the entire research trajectory of the SRL community over the past two decades. We begin by providing a complete definition of SRL. To offer a comprehensive taxonomy, we categorize SRL methodologies into four key perspectives: model architectures, syntax feature modeling, application scenarios, and multi-modal extensions. Further, we discuss SRL benchmarks, evaluation metrics, and paradigm modeling approaches, while also exploring practical applications across various domains. Finally, we analyze future research directions in SRL, addressing the evolving role of SRL in the age of large language models (LLMs) and its potential impact on the broader NLP landscape. We maintain a public repository and consistently update related resources at: https://github.com/DreamH1gh/Awesome-SRL
Mixed Feelings: Cross-Domain Sentiment Classification of Patient Feedback
Jan 31, 2025Sentiment analysis of patient feedback from the public health domain can aid decision makers in evaluating the provided services. The current paper focuses on free-text comments in patient surveys about general practitioners and psychiatric healthcare, annotated with four sentence-level polarity classes -- positive, negative, mixed and neutral -- while also attempting to alleviate data scarcity by leveraging general-domain sources in the form of reviews. For several different architectures, we compare in-domain and out-of-domain effects, as well as the effects of training joint multi-domain models.
A Collection of Question Answering Datasets for Norwegian
Jan 19, 2025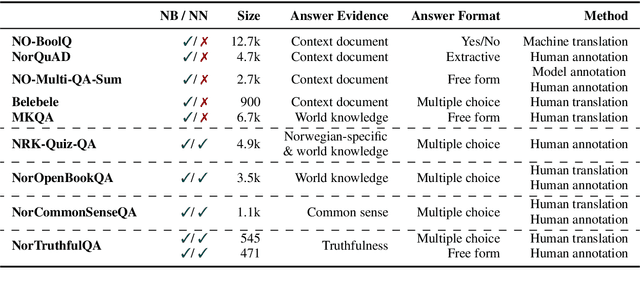
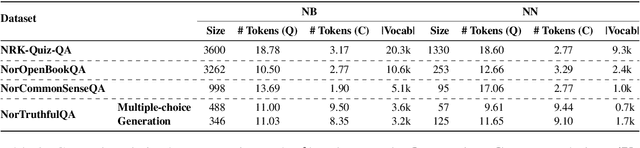
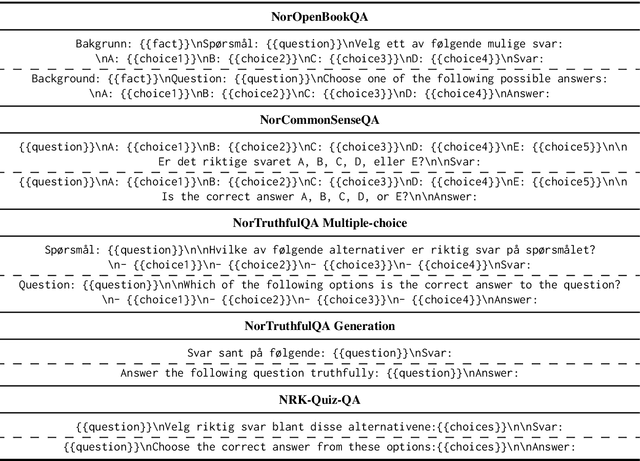
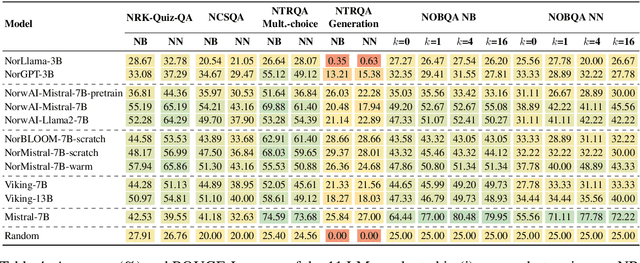
This paper introduces a new suite of question answering datasets for Norwegian; NorOpenBookQA, NorCommonSenseQA, NorTruthfulQA, and NRK-Quiz-QA. The data covers a wide range of skills and knowledge domains, including world knowledge, commonsense reasoning, truthfulness, and knowledge about Norway. Covering both of the written standards of Norwegian - Bokm{\aa}l and Nynorsk - our datasets comprise over 10k question-answer pairs, created by native speakers. We detail our dataset creation approach and present the results of evaluating 11 language models (LMs) in zero- and few-shot regimes. Most LMs perform better in Bokm{\aa}l than Nynorsk, struggle most with commonsense reasoning, and are often untruthful in generating answers to questions. All our datasets and annotation materials are publicly available.
Benchmarking Abstractive Summarisation: A Dataset of Human-authored Summaries of Norwegian News Articles
Jan 13, 2025



We introduce a dataset of high-quality human-authored summaries of news articles in Norwegian. The dataset is intended for benchmarking the abstractive summarisation capabilities of generative language models. Each document in the dataset is provided with three different candidate gold-standard summaries written by native Norwegian speakers, and all summaries are provided in both of the written variants of Norwegian -- Bokm{\aa}l and Nynorsk. The paper describes details on the data creation effort as well as an evaluation of existing open LLMs for Norwegian on the dataset. We also provide insights from a manual human evaluation, comparing human-authored to model-generated summaries. Our results indicate that the dataset provides a challenging LLM benchmark for Norwegian summarisation capabilities
Small Languages, Big Models: A Study of Continual Training on Languages of Norway
Dec 09, 2024



Training large language models requires vast amounts of data, posing a challenge for less widely spoken languages like Norwegian and even more so for truly low-resource languages like S\'ami. To address this issue, we present a novel three-stage continual training approach. We also experiment with combining causal and masked language modeling to get more flexible models. Based on our findings, we train, evaluate, and openly release a new large generative language model for Norwegian Bokm\r{a}l, Nynorsk, and Northern S\'ami with 11.4 billion parameters: NorMistral-11B.
Entity-Level Sentiment: More than the Sum of Its Parts
Jul 04, 2024



In sentiment analysis of longer texts, there may be a variety of topics discussed, of entities mentioned, and of sentiments expressed regarding each entity. We find a lack of studies exploring how such texts express their sentiment towards each entity of interest, and how these sentiments can be modelled. In order to better understand how sentiment regarding persons and organizations (each entity in our scope) is expressed in longer texts, we have collected a dataset of expert annotations where the overall sentiment regarding each entity is identified, together with the sentence-level sentiment for these entities separately. We show that the reader's perceived sentiment regarding an entity often differs from an arithmetic aggregation of sentiments at the sentence level. Only 70\% of the positive and 55\% of the negative entities receive a correct overall sentiment label when we aggregate the (human-annotated) sentiment labels for the sentences where the entity is mentioned. Our dataset reveals the complexity of entity-specific sentiment in longer texts, and allows for more precise modelling and evaluation of such sentiment expressions.