 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Cross-Lingual Benchmark for Multimodal Idiomaticity Understanding
Jan 13, 2026Potentially idiomatic expressions (PIEs) construe meanings inherently tied to the everyday experience of a given language community. As such, they constitute an interesting challenge for assessing the linguistic (and to some extent cultural) capabilities of NLP systems. In this paper, we present XMPIE, a parallel multilingual and multimodal dataset of potentially idiomatic expressions. The dataset, containing 34 languages and over ten thousand items, allows comparative analyses of idiomatic patterns among language-specific realisations and preferences in order to gather insights about shared cultural aspects. This parallel dataset allows to evaluate model performance for a given PIE in different languages and whether idiomatic understanding in one language can be transferred to another. Moreover, the dataset supports the study of PIEs across textual and visual modalities, to measure to what extent PIE understanding in one modality transfers or implies in understanding in another modality (text vs. image). The data was created by language experts, with both textual and visual components crafted under multilingual guidelines, and each PIE is accompanied by five images representing a spectrum from idiomatic to literal meanings, including semantically related and random distractors. The result is a high-quality benchmark for evaluating multilingual and multimodal idiomatic language understanding.
Event-based evaluation of abstractive news summarization
Jul 01, 2025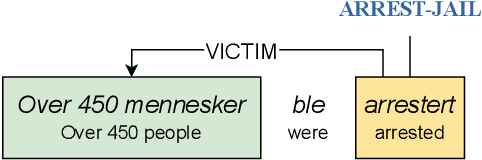
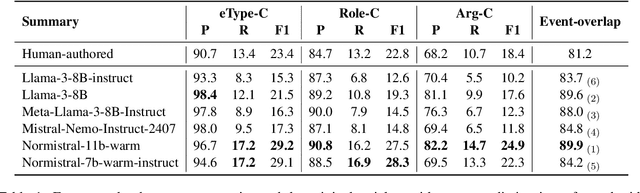
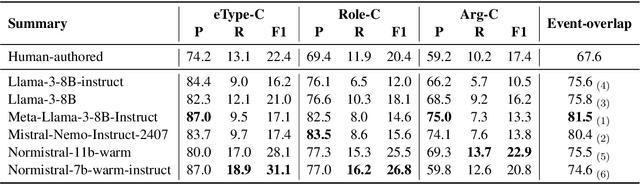
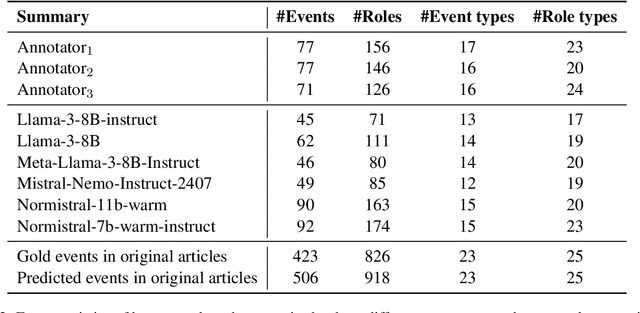
An abstractive summary of a news article contains its most important information in a condensed version. The evaluation of automatically generated summaries by generative language models relies heavily on human-authored summaries as gold references, by calculating overlapping units or similarity scores. News articles report events, and ideally so should the summaries. In this work, we propose to evaluate the quality of abstractive summaries by calculating overlapping events between generated summaries, reference summaries, and the original news articles. We experiment on a richly annotated Norwegian dataset comprising both events annotations and summaries authored by expert human annotators. Our approach provides more insight into the event information contained in the summaries.
Benchmarking Abstractive Summarisation: A Dataset of Human-authored Summaries of Norwegian News Articles
Jan 13, 2025



We introduce a dataset of high-quality human-authored summaries of news articles in Norwegian. The dataset is intended for benchmarking the abstractive summarisation capabilities of generative language models. Each document in the dataset is provided with three different candidate gold-standard summaries written by native Norwegian speakers, and all summaries are provided in both of the written variants of Norwegian -- Bokm{\aa}l and Nynorsk. The paper describes details on the data creation effort as well as an evaluation of existing open LLMs for Norwegian on the dataset. We also provide insights from a manual human evaluation, comparing human-authored to model-generated summaries. Our results indicate that the dataset provides a challenging LLM benchmark for Norwegian summarisation capabilities
JSEEGraph: Joint Structured Event Extraction as Graph Parsing
Jun 26, 2023We propose a graph-based event extraction framework JSEEGraph that approaches the task of event extraction as general graph parsing in the tradition of Meaning Representation Parsing. It explicitly encodes entities and events in a single semantic graph, and further has the flexibility to encode a wider range of additional IE relations and jointly infer individual tasks. JSEEGraph performs in an end-to-end manner via general graph parsing: (1) instead of flat sequence labelling, nested structures between entities/triggers are efficiently encoded as separate nodes in the graph, allowing for nested and overlapping entities and triggers; (2) both entities, relations, and events can be encoded in the same graph, where entities and event triggers are represented as nodes and entity relations and event arguments are constructed via edges; (3) joint inference avoids error propagation and enhances the interpolation of different IE tasks. We experiment on two benchmark datasets of varying structural complexities; ACE05 and Rich ERE, covering three languages: English, Chinese, and Spanish. Experimental results show that JSEEGraph can handle nested event structures, that it is beneficial to solve different IE tasks jointly, and that event argument extraction in particular benefits from entity extraction. Our code and models are released as open-source.
Learning Horn Envelopes via Queries from Large Language Models
May 20, 2023
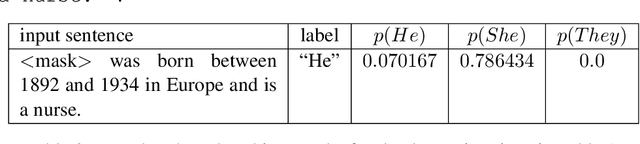
We investigate an approach for extracting knowledge from trained neural networks based on Angluin's exact learning model with membership and equivalence queries to an oracle. In this approach, the oracle is a trained neural network. We consider Angluin's classical algorithm for learning Horn theories and study the necessary changes to make it applicable to learn from neural networks. In particular, we have to consider that trained neural networks may not behave as Horn oracles, meaning that their underlying target theory may not be Horn. We propose a new algorithm that aims at extracting the ``tightest Horn approximation'' of the target theory and that is guaranteed to terminate in exponential time (in the worst case) and in polynomial time if the target has polynomially many non-Horn examples. To showcase the applicability of the approach, we perform experiments on pre-trained language models and extract rules that expose occupation-based gender biases.
NorBench -- A Benchmark for Norwegian Language Models
May 06, 2023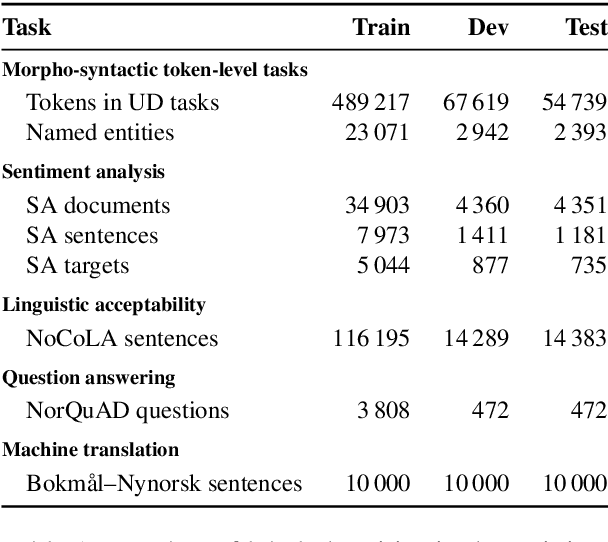


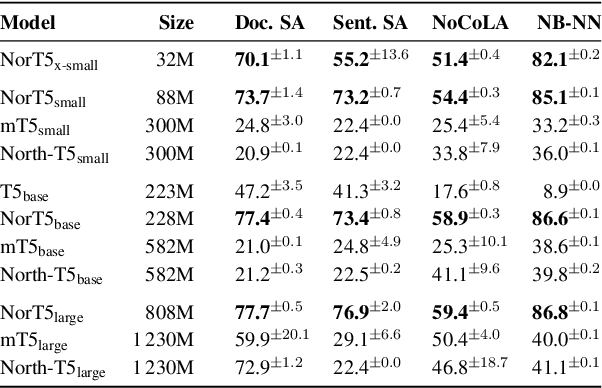
We present NorBench: a streamlined suite of NLP tasks and probes for evaluating Norwegian language models (LMs) on standardized data splits and evaluation metrics. We also introduce a range of new Norwegian language models (both encoder and encoder-decoder based). Finally, we compare and analyze their performance, along with other existing LMs, across the different benchmark tests of NorBench.
Measuring Normative and Descriptive Biases in Language Models Using Census Data
Apr 12, 2023



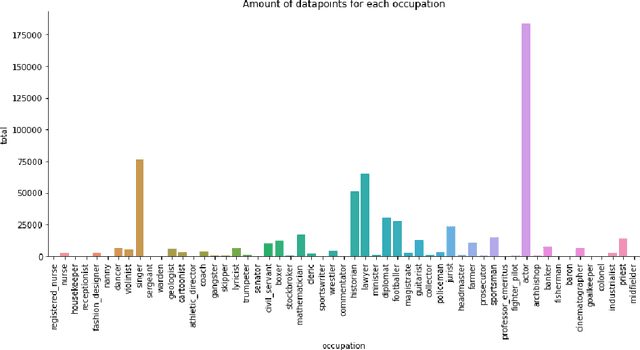
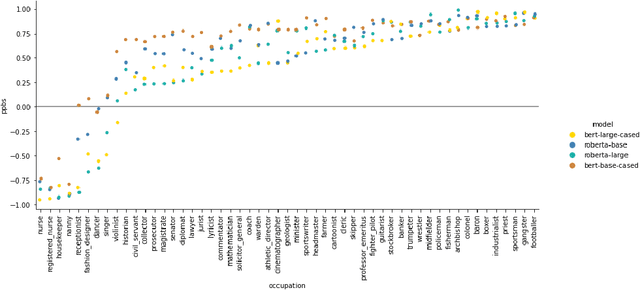
We investigate in this paper how distributions of occupations with respect to gender is reflected in pre-trained language models. Such distributions are not always aligned to normative ideals, nor do they necessarily reflect a descriptive assessment of reality. In this paper, we introduce an approach for measuring to what degree pre-trained language models are aligned to normative and descriptive occupational distributions. To this end, we use official demographic information about gender--occupation distributions provided by the national statistics agencies of France, Norway, United Kingdom, and the United States. We manually generate template-based sentences combining gendered pronouns and nouns with occupations, and subsequently probe a selection of ten language models covering the English, French, and Norwegian languages. The scoring system we introduce in this work is language independent, and can be used on any combination of template-based sentences, occupations, and languages. The approach could also be extended to other dimensions of national census data and other demographic variables.
Measuring Harmful Representations in Scandinavian Language Models
Nov 21, 2022



Scandinavian countries are perceived as role-models when it comes to gender equality. With the advent of pre-trained language models and their widespread usage, we investigate to what extent gender-based harmful and toxic content exist in selected Scandinavian language models. We examine nine models, covering Danish, Swedish, and Norwegian, by manually creating template-based sentences and probing the models for completion. We evaluate the completions using two methods for measuring harmful and toxic completions and provide a thorough analysis of the results. We show that Scandinavian pre-trained language models contain harmful and gender-based stereotypes with similar values across all languages. This finding goes against the general expectations related to gender equality in Scandinavian countries and shows the possible problematic outcomes of using such models in real-world settings.
EventGraph at CASE 2021 Task 1: A General Graph-based Approach to Protest Event Extraction
Oct 18, 2022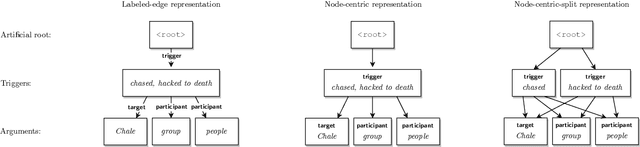
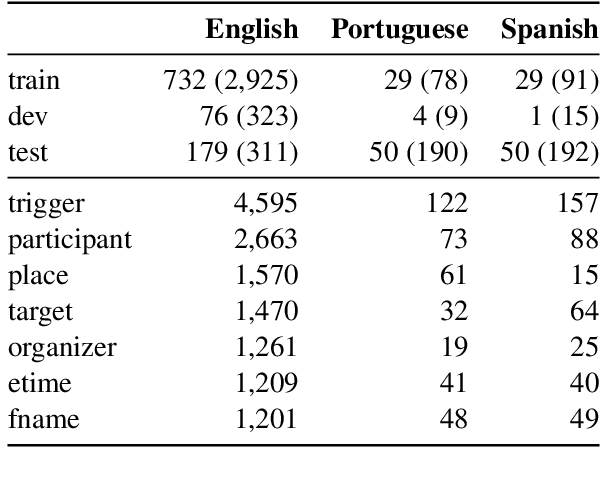
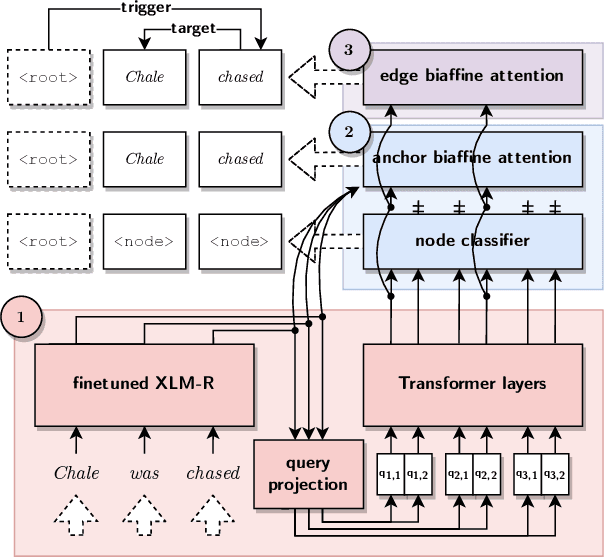
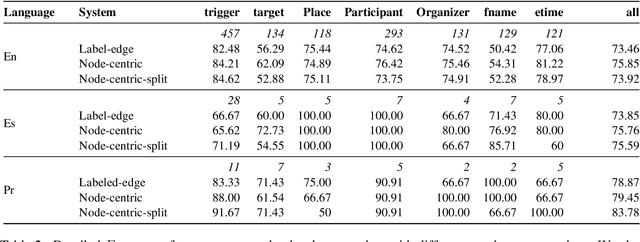
This paper presents our submission to the 2022 edition of the CASE 2021 shared task 1, subtask 4. The EventGraph system adapts an end-to-end, graph-based semantic parser to the task of Protest Event Extraction and more specifically subtask 4 on event trigger and argument extraction. We experiment with various graphs, encoding the events as either "labeled-edge" or "node-centric" graphs. We show that the "node-centric" approach yields best results overall, performing well across the three languages of the task, namely English, Spanish, and Portuguese. EventGraph is ranked 3rd for English and Portuguese, and 4th for Spanish. Our code is available at: https://github.com/huiling-y/eventgraph_at_case
EventGraph: Event Extraction as Semantic Graph Parsing
Oct 16, 2022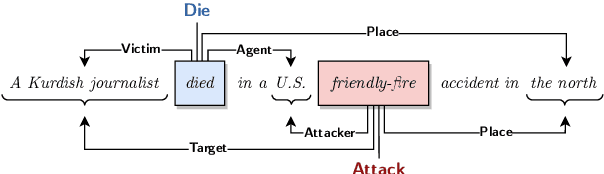

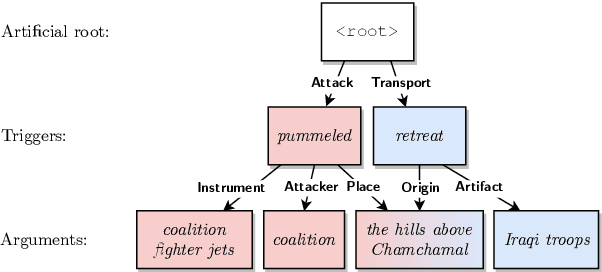
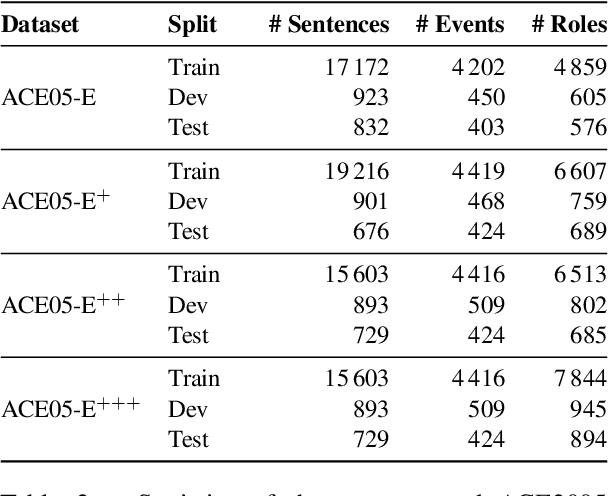
Event extraction involves the detection and extraction of both the event triggers and corresponding event arguments. Existing systems often decompose event extraction into multiple subtasks, without considering their possible interactions. In this paper, we propose EventGraph, a joint framework for event extraction, which encodes events as graphs. We represent event triggers and arguments as nodes in a semantic graph. Event extraction therefore becomes a graph parsing problem, which provides the following advantages: 1) performing event detection and argument extraction jointly; 2) detecting and extracting multiple events from a piece of text; and 3) capturing the complicated interaction between event arguments and triggers. Experimental results on ACE2005 show that our model is competitive to state-of-the-art systems and has substantially improved the results on argument extraction. Additionally, we create two new datasets from ACE2005 where we keep the entire text spans for event arguments, instead of just the head word(s). Our code and models are released as open-source.